
Совсем недавно я рассказывал об LLM для математики на митапе CS Space, и вот появилась мощная новость на эту тему. Говорят, новая модель от OpenAI, которая ещё не скоро будет опубликована, смогла нарешать на золотую медаль IMO 2025! Но ведь ещё год назад AlphaProof не хватало одного балла до золота IMO 2025, так что же здесь удивительного? Давайте разберёмся по порядку: начнём с того, чем был прошлогодний AlphaProof, а потом перейдём к последней новости.
Кто же выиграл серебро? AlphaGeometry и AlphaProof
История AlphaProof началась с модели AlphaGeometry (Trinh et al., 2024), которая совмещала LLM и символьные вычисления в духе DeepMind’овских моделей вроде AlphaTensor. Чтобы решить геометрическую задачу, нужно уметь:
- выводить все факты об объектах, которые можно увидеть на рисунке;
- делать новые построения, которые добавят новые объекты, о которых можно повыводить факты.
Первый пункт здесь в основном чисто технический и формальный, а творчество состоит во втором пункте. Поэтому в AlphaGeometry LLM порождает идеи для новых построений, а symbolic engine выводит из них всё, что можно:

AlphaGeometry решал геометрические задачи на уровне серебра IMO. Потом появилась AlphaGeometry 2, на модели Gemini получше и на большем синтетическом датасете.
Ну а потом перешли и к не-геометрическим задачам. В системе AlphaProof (DeepMind, 2024; см. также презентацию) LLM соединяется с Lean, системой для порождения и проверки формальных доказательств (proof assistant). Специально дообученная модель Gemini переводит естественный язык в формальную постановку, а потом RL в стиле AlphaZero обучается искать доказательство в Lean:

Здесь солвер (solver network) — это модель, которая выбирает следующий “ход” в виде Lean tactic, как AlphaZero. Солвер обучается сначала с учителем на mathlib, большой библиотеке проверенных формальных доказательств, а потом обучением с подкреплением, где Lean проверяет порождённые доказательства.

Солвер учится доказывать так же, как AlphaZero учится играть в шахматы, это поиск по дереву; а LLM даёт формализацию и новые идеи. По мере решения задач они добавляются в обучение, т.е. сам собой получается curriculum learning от простого к сложному.
В итоге AlphaProof вместе с AlphaGeometry 2 дошли до уровня серебряной медали на IMO 2024, минус один балл от золота:

Это направление, конечно же, продолжается и сегодня, и есть масса работ о том, как соединить формальные доказательства с LLM. Наверное, самый громкий недавний релиз — это DeepSeek-Prover-V2 (Ren et al., 30 апреля 2025): LLM, специально дообученная для формальных доказательств в Lean 4:

Сейчас обычно именно его используют в дальнейших таких исследованиях (например, DREAM от Cao et al., June 20, 2025, или LeanConjecturer от Onda et al., June 27, 2025), но сам по себе DeepSeek-Prover-V2, конечно, никакого золота IMO не выиграет.
LLM до сих пор: Proofs and Bluffs
Выходит, AlphaProof — это что-то очень сложное, что нам с вами не запустить. Мне не до конца понятно, почему мы не знаем результатов AlphaProof на FrontierMath и тому подобных более “научных” датасетах, но нам, пользователям, в любом случае интереснее, как работают те LLM, к которым мы можем получить доступ (хотя бы в некотором будущем). Как же “чистые” LLM, без обвязки и дообучения подобно AlphaProof, справляются со сложными олимпиадными задачами?
В докладе на митапе я остановился на отрицательном результате. В работе под названием “Proof or Bluff” Petrov et al. проверили, как LLM справятся с 2025 USA Math Olympiad, которой точно не было в обучающей выборке. Просили писать полное доказательство и проверяли как людей. Оказалось, что результаты были почти нулевыми, максимум 2 балла из 42 у DeepSeek R1:

Разумеется, и этот результат в итоге оказался не таким обескураживающим, как кажется. Первая версия “Proof or Bluff” вышла 27 марта 2025 года, а буквально через неделю вышла Gemini 2.5 Pro, и Petrov et al. пришлось срочно обновлять табличку! В версии от 9 апреля Gemini 2.5 Pro решает уже одну задачу совсем хорошо и другую наполовину, 10 баллов из 42:

А 29 мая появился новый бенчмарк: исследователи из ETH Zurich Balunovic et al. (2025) сделали бенчмарк MathArena, который призван как раз сравнивать LLM на разных математических олимпиадах. Они сравнили o3, o4-mini, Gemini-2.5-Pro, Grok-4 и Deepseek-R1, причём старались делать это по-честному, с максимальной “силой” модели:
- порождали по 32 ответа для каждой модели и выбирали лучший самой же моделью (best-of-32); это хороший способ улучшить результат, особенно в задачах на доказательство;
- проверяли полученные решения руками, четырьмя профессиональными судьями, у которых был опыт проверки IMO и других олимпиад.
В частности, такой эксперимент провели и на IMO 2025. И вот что у них получилось:
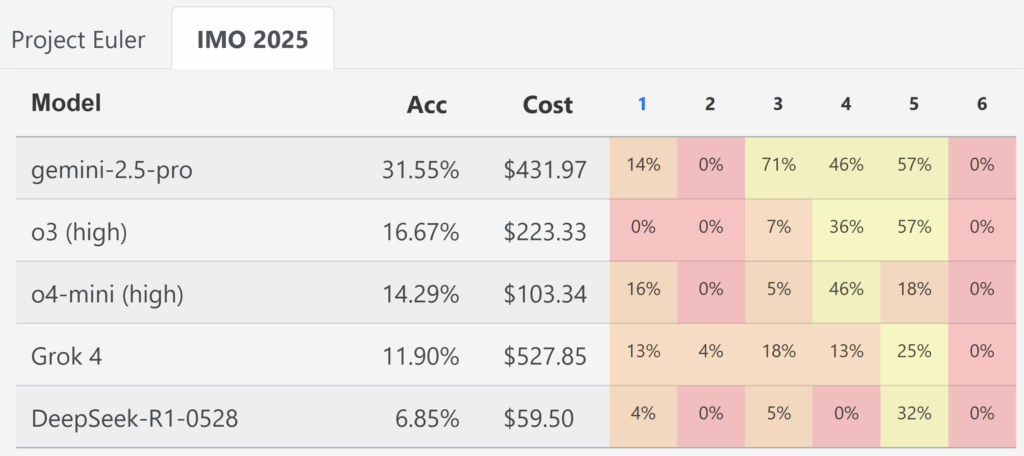
Получился огромный прогресс по сравнению с тем, что было в конце марта: Gemini 2.5 Pro уже набрала довольно много баллов… но это далеко не золото. Пост от создателей бенчмарка так и назывался: “Not Even Bronze“.
Новая модель OpenAI: золото IMO для “чистой” LLM
И с этим мы подходим к 18-19 июля 2025 года, когда исследователи из OpenAI объявили, что их новая модель смогла добраться до уровня золота IMO 2025. У нас пока не так много информации: тред Alexander Wei, репозиторий с решениями задач и тред Noam Brown; если честно, мне кажется, что это “пока” ещё надолго, OpenAI ещё очень долго не планируют релиз этой экспериментальной модели.
И тем не менее кое-какие важные детали мы узнали:
- это general reasoning LLM, не система вроде AlphaProof или DeepSeek-Prover; иначе говоря, это обычная LLM вроде o3-pro, только лучше, следующая итерация;
- очевидно, там было много улучшений, но главное, о чём пишут Wei и Brown — это следующий шаг в масштабировании test-time reasoning; современные модели “размышляют” в течение считанных минут подряд (Deep Research не совсем считается, там скорее много небольших размышлений объединены), а эта секретная модель может думать уже в течение пары часов;
- кстати, о часах — модель участвовала наравне с людьми, в течение двух четырёхчасовых сессий; это тоже важно, потому что, например, AlphaProof в прошлом году решал задачи, кажется, трое суток;
- оценивали тоже наравне с людьми, три судьи с опытом оценки настоящих IMO; в результате модель набрала 35 баллов из 42, решив пять задач из шести; кстати, если это значит, что 5 из 6 решены на 7 баллов, а шестая никак (Wei не уточняет), то это тоже шаг вперёд от текущих LLM, которые всё время чего-то недоговаривают и набирают частичные баллы, даже если идея правильная.
Я хотел было обсудить какую-нибудь задачу из IMO 2025 и её решение новой моделью OpenAI… но быстро сдался. Решения выглядят хоть и читаемо в целом, но разбираться в них нелегко; вот типичный кусочек:
3. Analyze n=3 exactly.
S := P_3 = {positive ints (a,b), a+b<=4}: 6 points.
List as:
A=(1,1), B=(1,2), C=(1,3), D=(2,1), E=(2,2), F=(3,1). Exactly 6.First enumerate non-sunny lines’ intersections with S.
Non-sunny directions: vertical x=const, horizontal y=const, diagonal x+y=const.
Inside S:
Verticals: x=1: {A,B,C} (size3), x=2:{D,E} size2, x=3:{F}.
Horiz: y=1 {A,D,F} size3, y=2 {B,E} size2, y=3 {C}.
Diagonal: sums:2:{A} ,3:{B,D} size2, 4:{C,E,F} size3.
So any non-sunny line intersection with S is subset of one of:
three size3 sets: {A,B,C}; {A,D,F}; {C,E,F};
three size2: {B,E}; {D,E}; {B,D}. (size1 irrelevant).So far.
Надеюсь, Фёдор Петров, который на митапе рассказывал про LLM и олимпиадные задачи, разберётся. Я готов поверить, что умными людьми уже проверено; достижение в любом случае замечательное.
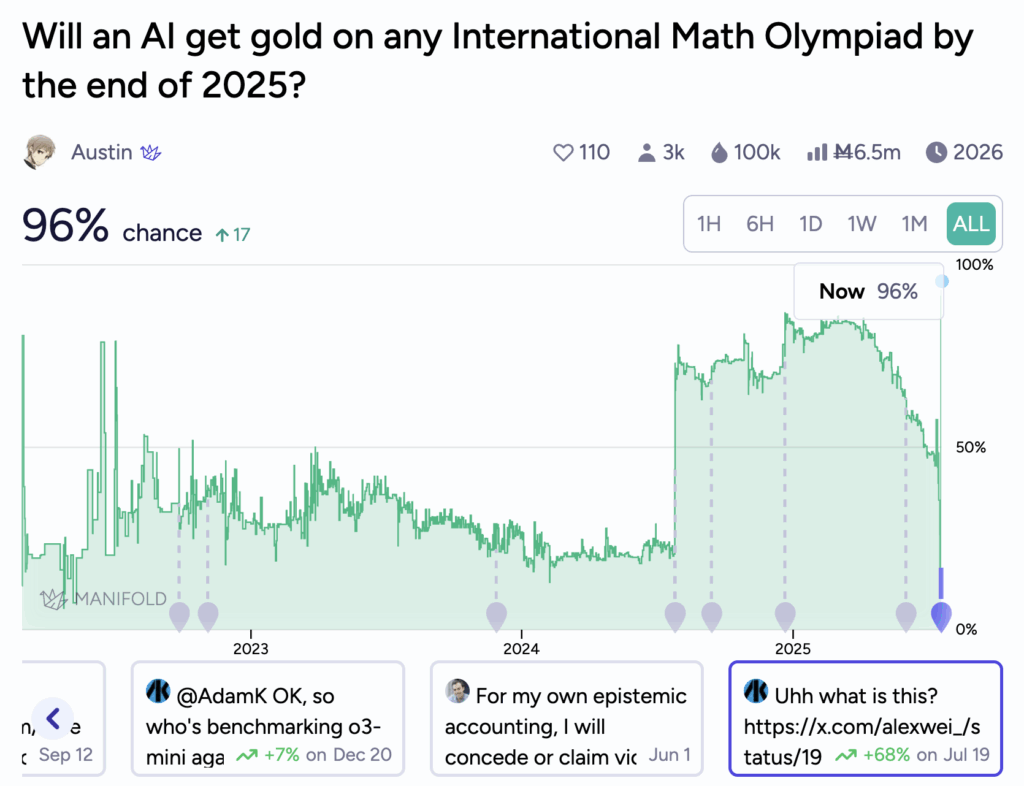
На Manifold был на этот счёт prediction market, на котором отметились даже такие люди, как Пол Кристиано и Элиэзер Юдковский. В 2022 году Кристиано писал: “I’d put 4% on “For the 2022, 2023, 2024, or 2025 IMO an AI built before the IMO is able to solve the single hardest problem… Maybe I’ll go 8% on “gets gold” instead of “solves hardest problem”.” Юдковский был более оптимистичен: “My probability is at least 16% [on the IMO grand challenge falling]”.
Не будем их критиковать: в 2022 предсказать реальную скорость прогресса было очень сложно. Но сейчас линия этого предсказания выглядит вот так:
Заключение
Заглавная картинка в посте — намёк на знаменитый мем о сборной США на IMO. Может быть, скоро роботы превзойдут людей и в математических олимпиадах. Но главное, конечно, не в том, чтобы решать олимпиадные задачки. Шахматы не умерли с появлением сверхчеловеческих движков (а скорее набрали популярность), и математические олимпиады как соревнования между людьми не умрут.
Главное в том, сможет ли этот прогресс превратиться не просто в спортивный успех, а в новые математические результаты. А где математические, там и алгоритмические, а там и пресловутый self-improvement, первые шаги которого мы только что видели в AlphaEvolve.
И вот это уже очень, очень интересный вопрос.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!
Leave a Reply