История игры Amerzone начинается даже не в девяностые, а в 1980-е годы, когда Бенуа Сокаль ещё никак не был связан с игровой индустрией, а рисовал комиксы (которые, кстати, уже раскрашивал на компьютере). В частности, в 1986 году он нарисовал комикс L’Amerzone, один из многих в серии приключений инспектора Канардо, утки-детектива (hold that thought! к этой идее мы ещё вернёмся в следующих постах). В нём детектив отправлялся в вымышленную южноамериканскую страну с полным набором соответствующих стереотипов; вот как это примерно выглядело:
Любопытный факт: слово Amerzone не имеет отношения к Америке, а является комбинацией Amazon и amer — “горький” по-французски. Конкретный комикс про горькую Амазонку не был особенно выдающимся (сейчас у него рейтинг 3.5 на goodreads), но в целом инспектор Канардо действительно, pardon the pun, взлетел, продавался хорошо и сделал Бенуа Сокалю имя.
И вот в середине девяностых Сокаль решил попробовать выпустить единый CD-ROM со своими комиксами и некими “3D-материалами” по его вселенной. Издатель одобрил, а в качестве нового медиа решено было сделать игру. Сначала хотели сделать маленькую и простенькую, но вошли во вкус, и к 1999 году получился Amerzone.
С комиксами про утку-детектива, правда, игра имела не так уж много общего (кроме места действия). Все герои стали людьми, а стиль был уже вполне реалистичным. Сам Сокаль признавался, что главными источниками вдохновения стали, во-первых, Myst, а во-вторых, атмосфера знаменитого фильма Вернера Херцога Fitzcarraldo. Выглядело это в 1999 году вот так — согласитесь, довольно круто для квеста из девяностых:
И вот совсем недавно, в апреле 2025 года, вышел римейк классической игры с тем же названием; в него я, разумеется, и играл, чего и вам желаю. Интервью с разработчиками из Microids не нашёл, но ни секунды не сомневаюсь, что это было сделано в память самого Бенуа Сокаля, который ушёл из жизни в 2021-м; Syberia 3 заканчивали уже без него.
Графику в римейке, конечно, прокачали очень хорошо; выглядит всё почти совсем современно. Детализация и графика в целом, конечно, скорее выглядят на уровне 2015 года, чем 2025-го, но разве кто-то здесь будет спорить, что в 2015-м игры были уже очень хороши на вид?.. В Amerzone и пейзажи красивые, и анимации достаточно детализированы, и стиль (унаследованный от оригинала) на высоте:
А самое интересное в этой игре в том, что этот очень достойный внешний вид сочетается с, по всей видимости, не особенно изменившимся геймплеем из девяностых! Это квест, ходишь ты в нём прямо как в Myst и Riven, перемещаясь между фиксированными контрольными точками, и загадки выглядят как “применить одно на другое”.
Как по мне, отличный геймплей! Я любил квесты в детстве, но у классических квестов в наше время есть две проблемы: во-первых, играть в них сейчас уже немного больно глазам, даже если исходная графика не претендовала на реалистичность, а во-вторых, они частенько были сверхсложными и совершенно нелогичными. Как говорится, ставьте 🐐 те, кто помнит козла из Broken Sword (а это очень простой квест по сравнению с ранними девяностыми).
И вот римейк Amerzone исправил обе: графику переделали, а загадки изначально были относительно простыми (относительно других квестов!) и строились так, чтобы игра проходилась как кино, а не заставляла часами пробовать “всё на всё”. Здесь всегда подсвечиваются все активные точки, и на каждой конкретной локации их не так много — всё помещается в голове, подсказки работают, “применить всё на всё” было бы не так сложно, но так и не пригодилось, все загадки решились по пути. Кажется, Сокаль так и задумывал.
Здесь неплохая история. Это, конечно, самый классический и самый прямолинейный Бенуа Сокаль: мы за живую природу и против угнетающих её латиноамериканских диктаторов, но зато мы с роботами! Точнее, конечно, не с роботами, а с фантастическими механизмами, которые даже ещё не стимпанк.
Ну ладно, здесь ещё нет прелестных автоматонов из Syberia, но есть стильная лодка, трансформирующаяся в самолёт и вообще во всё что угодно… через загрузку нужных дискет (дело происходит в 1998 году, так что почему бы и не дискет, действительно).
Сюжет очень стереотипный, но есть много любопытного лора, который подаётся в формате мини-расследований, и в целом читать записочки мне не наскучило до самого конца.
В общем, это тот самый квест. Та самая Syberia, только ещё раньше — это первая игра Бенуа Сокаля. Те самые загадки “применить палку на копалку”, только совсем не душные. И то самое погружение, только в современной графике. Рекомендую!
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!
Маленький open world — почти оксюморон, но Caravan SandWitch справляется. В первую очередь это ужасно добрая игра, comfort game, которая вас согреет ярким солнышком, напоит тёплым чайком и обнимет всеми руками всех NPC сразу, включая роботов, младенцев и разумных лягушек, недавно отделившихся от великой грибницы. Сложности здесь никакой нет, зато есть много приятного исследования окружающего мира.
Формально Caravan SandWitch — это open world adventure с элементами метроидвании. Главная героиня ездит по компактному, но на удивление богатому и разнообразному открытому миру на милом фургончике, выполняя квесты и собирая collectibles. Время от времени фургончик получает апгрейд одного из инструментов — или сканера, который потом обучится хакингу и сможет открывать некоторые закрытые двери, или специального выстреливающего кабеля, который со временем приобретёт сразу много разных свойств.
Сюжет достаточно предсказуем: ты возвращаешься на родную планету Cigalo (понятия не имею, как это правильно произносить) искать пропавшую сестру, от которой вдруг поступило загадочное сообщение. По ходу дела приходится разобраться, что вообще на родной планете происходит, как большая межзвёздная корпорация её бросила, решить проблемы всех, кто на планете живёт, и так далее. Ничего особенного, в общем.
Но в сюжетной стороне дела есть важные подробности. Во-первых, персонажи: они и сами прописаны хорошо, и взаимоотношения между ними достаточно разнообразные (но все милые и тёплые!). Во-вторых, мир и его история: лор достаточно богатый, мир хоть и маленький, но очень разнообразный. Достаточно сказать, что на Cigalo обитает раса разумных существ, внешне похожих на лягушек, но в реальности являющихся, видимо, грибами, как Владимир Ильич — они отделяются от великой грибницы, какое-то время живут отдельно, а вместо смерти возвращаются в грибницу.
Локации сделаны очень хорошо. Они тоже маленькие и компактные, но дают много возможностей для исследования, много мини-загадок, не представляющих интеллектуального интереса, но открывающих зачастую новые неожиданные места и кусочки лора. Мне так понравилось исследовать мир, что я не поленился выполнить все сайд-квесты: и еду собрал, и плюшевые игрушки, и, разумеется, роботов (да, там ещё и разумные роботы, которые просят тебя собрать сознания своих собратьев по всему миру, чтобы переселить их на сервер — тоже хороший штрих).
Но в первую очередь это игра про настроение, про вайб, расслабляющий, почти терапевтичный опыт. Думаю, не случайно в Caravan SandWitch нет смены дня и ночи: там всегда солнечно, уютно и безопасно. И в то же время слегка меланхолично — всё-таки мир постапокалиптический; музыка всем этим вайбам тоже весьма способствует. Врагов никаких нет, срочности никакой нет, нельзя даже разбиться, прыгнув с большой высоты. Все NPC очень дружелюбные и милые, никакого конфликта нет, и даже пресловутая “песчаная ведьма” в итоге, конечно же, никакой угрозой не является (да, это спойлер, но разве вы сомневались?).
Единственный минус этого на мой личный взгляд — то, что через всю игру идёт этакий вайб, который я даже не знаю как назвать, поэтому назову, рискуя обидеть целое поколение, “зумерским”. Все тексты написаны так, как будто все персонажи этого постапокалиптического мира, испытывающего буквально проблемы с едой, регулярно ходят к терапевту и проходят тренинги по бережной коммуникации. Все герои проговаривают свои чувства словами через рот, принимают друг друга с первого слова, во всей игре нет ни одного конфликта между персонажами. С одной стороны, я понимаю, что так и задумано, но с другой, это требует куда большего suspension of disbelief, чем говорящие лягушки.
Но это мелочи, а в целом я рекомендую Caravan SandWitch всем, кто хочет расслабиться, потыкать в кнопочки без напряга и получить милую тёплую историю и красивый мир, который интересно исследовать. Несколько приятных вечеров гарантированы.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура“: присоединяйтесь!
Игра-головоломка с очень крутой базовой идеей, которая ещё и реализована хорошо. Всё как мы любим: инди-игра, студия Sad Owl Studio, состоявшая поначалу из одного-единственного Мэтта Старка, небольшая длина (часа на четыре), отличные головоломки, которые ещё и увязываются в любопытную историю.
Главная механика — имеющийся у вас “волшебный” фотоаппарат, который может сделать картинку реальностью, и эту реальность можно потом использовать, чтобы пройти дальше. Поскольку по сюжету дело происходит в виртуальной реальности, это как бы не волшебство, а просто свойство окружающей вас виртуальной среды. Фотографируешь что-то, потом прикладываешь фотографию к другому месту (можно в другом масштабе), и оно там появляется; примерно так:
Соответственно, если вам нужно, например, запитать телепорт батарейками, и их нужно три, а в доступе только одна, вы можете её два раза сфотографировать и получить три батарейки. Если нужно зайти в замкнутую комнату, можно сфотографировать пустое место, приложить к стене и получить в стене дырку. А ещё можно повернуть фотографию, материализовать в повёрнутом виде, и тогда, например, та же батарейка упадёт согласно законам тяготения:
Разумеется, этим дело не ограничивается; в игре не одна механика, а сразу много связанных друг с другом, и на каждом “уровне” (очередном кусочке мира, до которых ты доезжаешь на поезде) будут раскрываться новые стороны. Не буду рассказывать обо всём, но, например, там есть стационарные фотоаппараты, фотоаппараты с задержкой и аккумуляторы, которые на несколько секунд продолжают подавать электричество и после отключения от источника.
Думаю, на этом месте многие читатели представили себе, сколько безумных и изобретательных загадок можно придумать с такими компонентами. И действительно, если захотеть, в игре можно встретить удивительные рекурсивные вещи:
Но Viewfinder очень искусно проходит по тонкой грани: раскрывает свои механики, но не душит игрока и не даёт слишком сложных загадок. Я не застревал надолго ни разу, и в гайды подсматривать совершенно не хотелось даже на опциональных более сложных уровнях.
И последний уровень, кстати говоря, отлично придуман: его нереально пройти с первого раза, да и со второго вряд ли, но при этом в нём нет ничего сложного… ладно, спойлерить и правда нехорошо. Просто скажу, что всю игру прошёл примерно за четыре часа (может быть, с половиной).
Во Viewfinder есть сюжет, который, опять же, не буду пересказывать, но он есть. В общем, мы пытаемся спасти человечество через поиск решений глобальных проблем в виртуальной реальности. По всей игре разбросаны аудиодневники, которые довольно интересно слушать, хотя, конечно, по сравнению с самой идеей и головоломками сюжет здесь недожат. Но функционально работает; по крайней мере, уровни соответствуют героям сюжета и вполне отражают их особенности.
А ещё там есть котик! И он с тобой разговаривает! И представляет собой, разумеется, весьма интеллектуального AI-помощника по имени Cait.
В общем, вы уже поняли, что я Viewfinder весьма рекомендую. Даже немного жалко, что разработчики не сделали игру подлиннее, добавив более сложных загадок. Но, может быть, ждём вторую часть?..
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура“: присоединяйтесь!
Я уже не раз рассказывал вам о небольших AA-играх от маленьких инди-студий; недавно были, например, Selfloss, Twin Mirror, Harold Halibut и The Haunting of Joni Evers. Broken Pieces от маленькой французской студии Elseware Experience тоже из этого ряда: это action adventure с элементами survival horror (можно играть с камерой как в Resident Evil), но в 3D, с загадками, историей и красивыми локациями.
И хотя я всегда к таким играм отношусь с теплотой, вердикт здесь, увы, однозначный: не получилось практически ничего.
Единственное, что сделано на мой взгляд хорошо, — это атмосфера и загадки. Окружение действительно красивое, городок Saint-Exil пахнет югом Франции (где я никогда не был, впрочем), здания и интерьеры колоритные, всё на месте и всё как надо.
Загадок два типа: с окружением, которые двигают сюжет и позволяют попасть в новые места, и небольшие пазлы, где ты сам двигаешь фишки. И те и другие мне понравились — они достаточно сложные, чтобы ощущался некоторый challenge, но не душат и не вызывают желания бежать за гайдом.
История, казалось бы, неплохая. Да, там какая-то паранормальщина, которая очень хочет, но так и не превращается в лавкрафтовщину, но в этом не было бы ничего страшного. Персонаж (в единственном числе, других живых людей тут нету) вполне хорошо выписан, следить за ней интересно, три разных направления в итоге сходятся в одно, и разгадки в целом хотелось узнать. Вот только узнать я их так и не смог: история недорассказана, вопросы остаются без ответов, мало что вообще чем-то мотивировано, и все ответы звучат как “потому что”. Да и заканчивается сюжет непонятно чем: то ли мы всё исправили, но непонятно как, то ли это был сон собаки, то ли (скорее всего) ещё более разочаровывающий твист…
Механик, казалось бы, много — но они не нужны. Есть стрельба, которая не нужна, потому что враги не вызывают проблем, а если бы вызывали, это бы только раздражало — во врагах нет никакого нарратива, они просто иногда появляются из ниоткуда, превращая пятачок земли в мини-арену. Есть магия, которая не нужна — магия смены погоды ещё кое-как работает как часть загадок, но боевая просто делает сражения проще и никакой глубины не добавляет. Есть механика времени (нужно успеть домой до ночи, иначе врагов станет очень много), которая не нужна, потому что в ней нет проблемы и нет оптимизации — ну потерял время зря, пошёл спать раньше времени, да и всё, число дней ни на что не влияет. Пазлы надо решать, чтобы получать бонусы из очень колоритного агрегата, но главный бонус — это улучшение для пистолета, а стрельба не нужна…
В общем, получилась сборная солянка, в которой большинство ингредиентов явно недоварены. Но вы знаете, всё-таки с душой сделано. Не буду рекомендовать эту конкретную игру, но не могу не сочувствовать студии Elseware Experience, планы развития которой заканчиваются так:
Удачи им!
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!
Я в своих докладах люблю пугать людей тем, что AI уже потихоньку начинает самостоятельно проводить исследования. Рассказывал вам уже про Google Co-Scientist, AI Scientist от Sakana AI, Robin, Zochi… Там были и важные новые идеи, и даже полностью автоматически порождённые статьи, принятые сначала на workshop при ICLR, а потом и на главную конференцию ACL. И вот вчера вышла ещё одна новость в том же направлении, на этот раз от Deepmind (и других подразделений Google Research). Кажется, AI-системы сделали ещё один шаг вверх по лестнице абстракций…
Введение
Представьте себе, что вы — учёный-биоинформатик, и вам нужно интегрировать данные секвенирования РНК отдельных клеток (single-cell RNA-seq) из десятка разных лабораторий. У каждой лаборатории был свой протокол, свои секвенаторы (по крайней мере, разные настройки секвенаторов), свои реагенты и свои условия эксперимента (насколько я понимаю, там даже влажность в лаборатории может повлиять на результат).
Теперь у вас есть тысячи разных датасетов с разными так называемыми batch effects (грубо говоря, шум, специфичный для этого датасета). И если вы возьмёте одинаковые T-клетки, измеренные в Гарварде и в Стэнфорде, любой наивный метод сравнения скажет, что это совершенно разные типы клеток — не потому что они правда разные, а потому что технические различия затмевают биологические.
Вы должны написать код, который должен их убрать, сохранив при этом биологический сигнал. Это как если бы вам нужно было взять сто фотографий леса с разных камер при разной погоде и в разной освещённости и привести их к единому стилю, то есть убрать различия камер, но обязательно сохранить то, что на одних фотографиях — лето, на других — осень, а на третьей пробежал зайчик.
Эта задача называется batch integration: как объединить разные single-cell датасеты, сохранив биологический сигнал. Задача очень важная и для Human Cell Atlas, который картирует все типы клеток в организме, и для онкологических исследований, и для, например, анализа того, как COVID-19 повлиял на иммунитет. Про неё есть датасеты, бенчмарки и лидерборды (Шишков, прости!), которые проверяют много разработанных исследователями метрик качества batch integration.
И вот вы садитесь делать batch integration. Через неделю у вас есть рабочий пайплайн. Он… ну, работает. Вроде бы. На ваших данных. Может быть. Точнее, в соответствии со знаменитым xkcd, у вас есть триста первый вроде бы рабочий пайплайн, потому что ещё в 2018-м их было около трёхсот (Zappia et al., 2018).
А теперь представьте, что AI-система берёт те же датасеты, порождает несколько десятков различных подходов, тестирует их все на публичном бенчмарке и выдаёт вам 40 методов, которые превосходят текущих лидеров человеческого лидерборда. И всё это за несколько часов вычислительного времени.
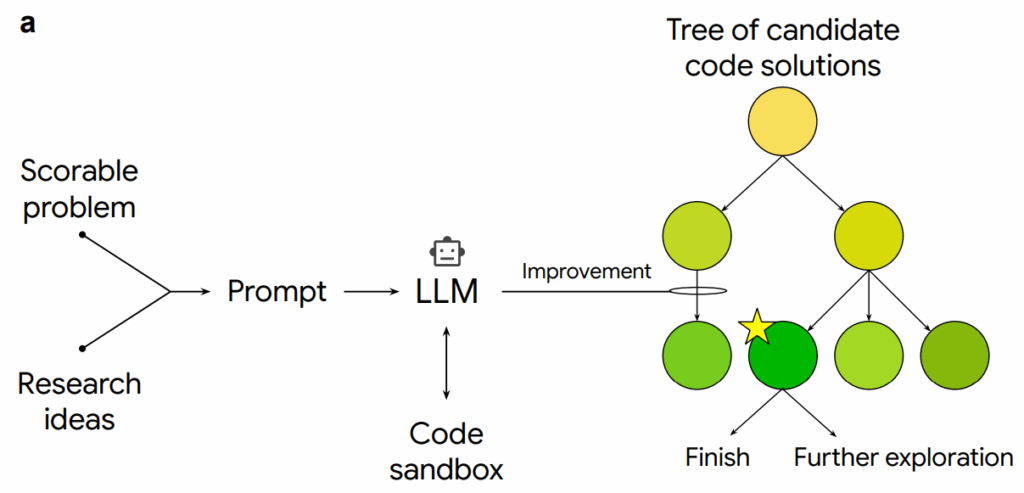
Но самое интересное, как водится, не в цифрах, а в том, как эта система работает. Это не просто “LLM пишет код”, а скорее продолжение семейства AI-систем от DeepMind, которые дали нам AlphaTensor, FunSearch и AlphaEvolve. В данном случае это сочетание трёх ингредиентов: поиска по дереву (как в AlphaGo), добавления идей из научной литературы (через LLM) и, самое интересное, рекомбинации методов (как в генетическом программировании), когда система скрещивает два алгоритма и получает гибрид, который может работать лучше обоих родителей.
Давайте разберёмся подробнее…
Код как пространство для поиска
Если вы следили за развитием всевозможных “ИИ-учёных” в последние пару лет, то видели уже много попыток автоматизировать процесс научного открытия. Был FunSearch от DeepMind, который использовал эволюционный поиск программ для перебора случаев в математических задачах. Есть AI Scientist от Sakana AI, который порождает целые научные статьи end-to-end. Недавно появился Google Co-Scientist, который предлагает идеи и планирует эксперименты на естественном языке. А последние версии AI Scientist и Robin уже написали полностью автоматически порождённые статьи, принятые сначала на workshop при ICLR, а потом и на главную конференцию ACL. Об этом всём я уже рассказывал в блоге:
Но все эти системы до сих пор объединяло то, что они работали в пространстве идей и текста: придумать через LLM что-то новенькое, через LLM же запрограммировать, посмотреть на результаты и опять попробовать что-то новенькое.
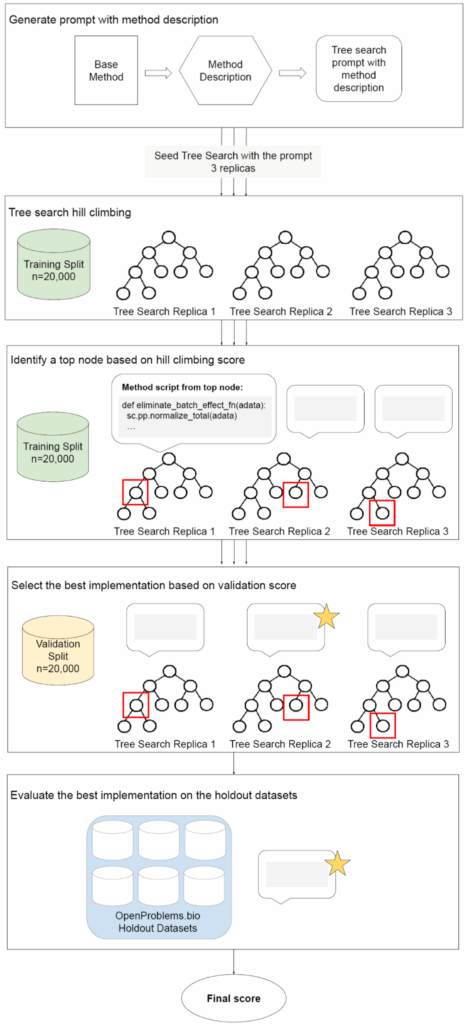
А система Aygün et al. (2025) работает в пространстве исполняемого кода с численной метрикой качества. Иначе говоря, вместо того чтобы писать красивые описания методов на английском языке, она работает в таком цикле:
берёт работающий код (начиная с какого-то существующего baseline, разумеется)
переписывает его с помощью LLM, внося некоторые изменения
запускает и получает численную оценку (score на конкретном бенчмарке)
использует поиск по дереву для систематического исследования пространства возможных модификаций.
Вот иллюстрация из статьи:
По сути, это превращает задачу “придумай новый научный метод” в задачу “найди путь в дереве кодовых мутаций, который максимизирует score”. И оказывается, что последняя может оказаться для современных AI-систем существенно проще.
Что за поиск по дереву?
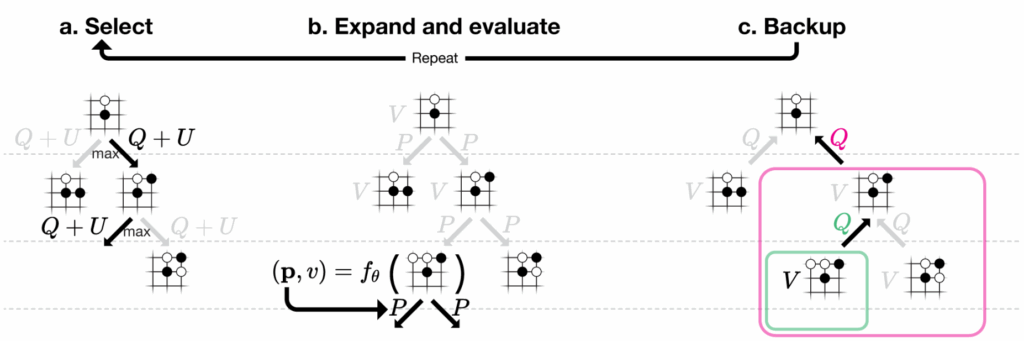
Здесь стоит остановиться подробнее. Вы наверняка помните, как AlphaZero использовал Monte Carlo Tree Search (MCTS) для игры в го и шахматы:
MCTS — это хорошее решение стандартной задачи обучения с подкреплением: как найти правильный баланс между
использованием (exploitation) веток, которые уже показали хороший результат, и
Точно так же работает и эта система. Она не просто абстрактно думает, “что бы ещё улучшить”, а строит дерево, где каждый узел представляет собой версию программы, а рёбра — конкретные модификации. Если какая-то модификация улучшила оценку, система с большей вероятностью будет исследовать эту ветку дальше. Главное здесь в том, чтобы была конкретная численная оценка, которую мы оптимизируем, аналог вероятности победы в го; ну и ещё, конечно, чтобы ставить новый эксперимент было не слишком дорого, т.е. чтобы мы могли позволить себе построение этого дерева.
И в отличие от го, где правила фиксированы, здесь система может делать любые изменения кода: менять архитектуру модели, добавлять шаги предобработки, переписывать функции ошибки, комбинировать методы… Пространство поиска огромно, но MCTS позволяет эффективно в нём искать.
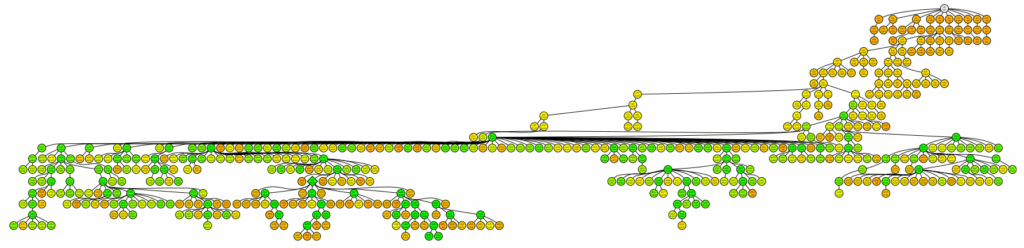
В результате может получиться дерево вроде вот такого:
Многорукие бандиты из MCTS здесь делают поиск более направленным; обратите внимание, что дерево вовсе не такое уж широкое, и в нём есть конкретные узлы с “хорошими идеями”, которые начинают постоянно использоваться и перетягивать на себя поиск. Эти “хорошие идеи” скорее всего соответствуют скачкам в целевой функции, и причины этих скачков вполне можно постичь человеческим разумом, это же просто изменения в коде экспериментов:
И вот ещё хорошая иллюстрация из статьи, которая показывает, как всё это работает вместе. Простите за большую картинку:
Инъекции и рекомбинации идей
После того как мы поняли общую идею MCTS для программ, начинается самая интересная часть, в которой интеллект современных LLM помогает сделать MCTS-поиск ещё лучше. Система Aygün et al. (2025) не просто мутирует код наугад — она, во-первых, импортирует идеи из внешних источников:
из научных статей, из которых она берёт описания методов и превращает их в ограничения и промпты для порождения кода;
из Gemini Deep Research, которую она использует для синтеза релевантных идей;
из Google Co-Scientist, от которой она получает планы новых экспериментов.
Возвращаясь к примеру: вы даёте системе задачу сделать batch integration на некотором датасете из single-cell RNAseq. Она идёт, читает статьи про ComBat, BBKNN, Harmony и другие методы, извлекает ключевые идеи (“ComBat делает линейную коррекцию через эмпирический байес”, “BBKNN балансирует батчи в пространстве ближайших соседей”), а затем пытается комбинировать эти идеи при порождении нового кода.
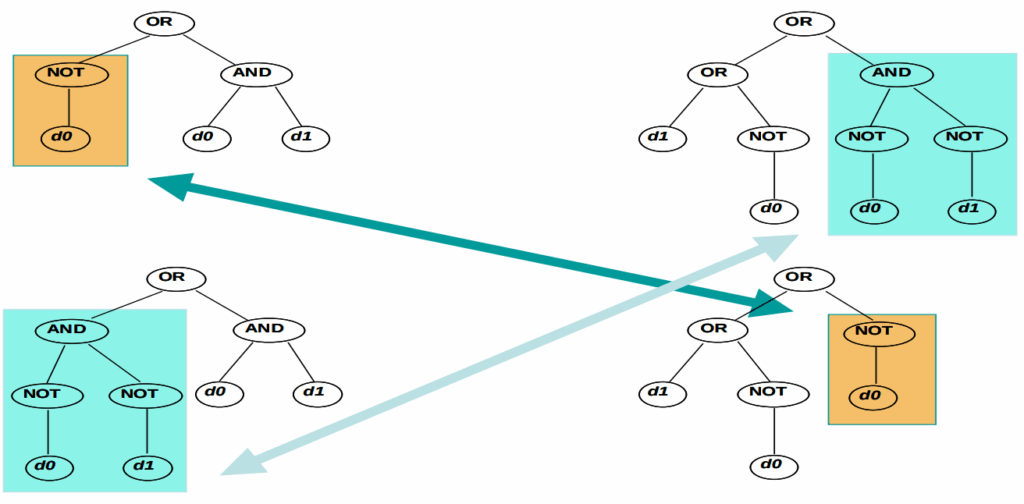
Последняя важная часть системы — рекомбинация, которая приходит из генетических алгоритмов. Помните, как в биологии работает половое размножение? Берём гены от двух родителей, перемешиваем, иногда получаем потомство, которое превосходит обоих, закрепляем.
То же самое можно попытаться сделать и с алгоритмами. В обычном генетическом программировании это бы значило взять два синтаксических дерева и перемешать; вот иллюстрация из классического обзора Tettamanzi (2005):
Но при помощи современных LLM Aygün et al. (2025) могут сделать рекомбинацию поумнее: взять два метода, которые хорошо работают, попросить LLM проанализировать их сильные и слабые стороны, добавить этот анализ в промпт и попросить породить гибрид, который пытается взять лучшее от обоих.
Звучит примитивно, но работает очень хорошо. В той самой задаче интеграции single-cell данных 24 из 55 гибридов (почти половина!) превзошли обоих родителей по получающейся оценке качества.
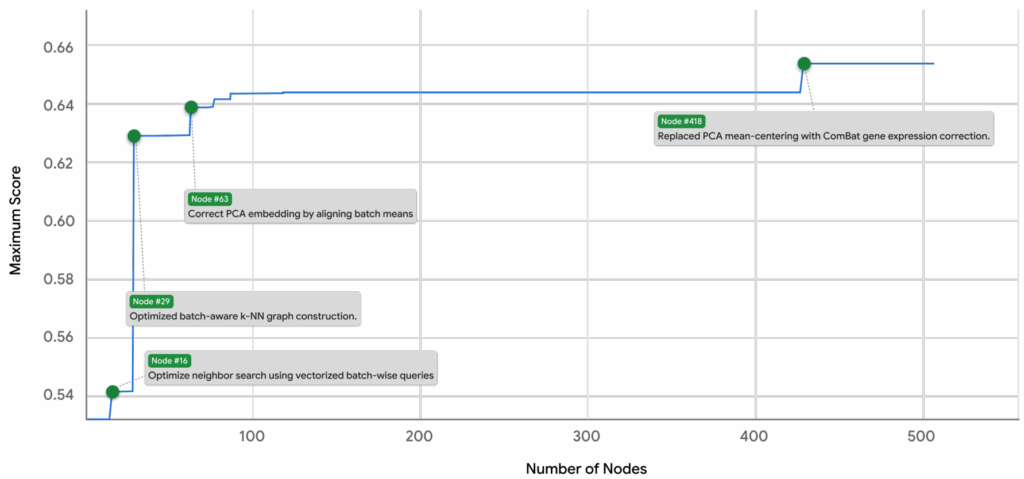
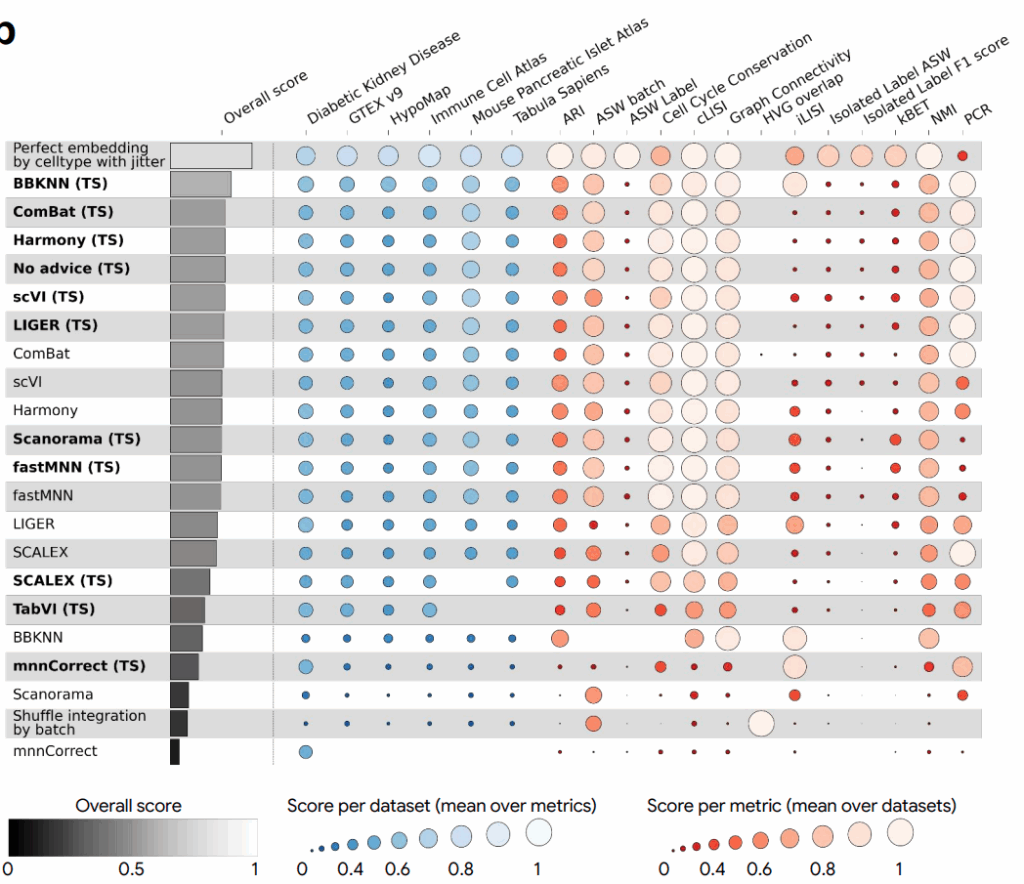
Можно даже разобрать конкретный весьма элегантный пример. Есть два классических метода для batch correction:
ComBat (Johnson et al., 2007), который делает глобальную линейную коррекцию, используя эмпирический байес (кстати, вот моя лекция про эмпирический байес из прошлогоднего курса); насколько я понял, ComBat хорошо удаляет глобальные батч-эффекты из всего датасета сразу, корректируя PCA-вложениях данных; он был номером один в лидерборде до сих пор;
BBKNN (Batch Balanced k-Nearest Neighbors; Polanski et al., 2020), напротив, работает локально, балансируя представленность батчей среди ближайших соседей каждой клетки.
Система составила из них гибрид, который сначала применяет ComBat для глобальной коррекции, а затем применяет BBKNN для тонкой локальной балансировки уже на глобально скорректированных PCA-вложениях. И этот гибрид стал лучшим методом на бенчмарке OpenProblems (Luecken et al., 2025), улучшив качество относительно оригинального ComBat на ~14%. В табличке ниже (TS) значит, что метод улучшили поиском по деревьям:
Мог бы человек додуматься до такой комбинации? Конечно! Сейчас, когда я прочитал о ней в статье и описал её здесь, эта идея звучит абсолютно тривиально. Но почему-то никто пока не успел посмотреть на проблему под таким углом, а система нашла этот угол автоматически, попутно протестировав десятки других вариантов.
Это как если бы у вас был аспирант, который прочитал всю литературу по теме, понял основные принципы и теперь систематически комбинирует их в поисках лучшего решения. Может быть, это пока не Эйнштейн, а всего лишь добросовестный аспирант, и у него нет блестящей научной интуиции, которая бы позволила сократить поиск до минимума. Но зато он очень, очень старательный, и может за одну ночь протестировать сотни вариантов.
Другие примеры
Я пока разбирал пример про single-cell РНК-секвенирование, но вроде бы система позиционируется как куда более общая; что насчёт других областей? Авторы рассматривают несколько разных задач, с весьма впечатляющими результатами.
Прогнозирование эпидемии COVID
Во время пандемии CDC (Centers for Disease Control and Prevention) собирали прогнозы госпитализаций от десятков исследовательских групп и объединяли их в ансамбль. Тогда это был золотой стандарт — лучшее, что могло предложить научное сообщество.
В результате 14 стратегий превзошли ансамбль CDC по метрике WIS (weighted interval score), и из них 10 — рекомбинации существующих методов.
Здесь особенно стоит подчеркнуть, что система работала с минимальными внешними данными — только исторические данные о госпитализациях. Никаких данных о мобильности, вакцинации, погоде и тому подобных условиях, которые некоторые системы вполне себе учитывали. И всё равно выиграла.
Прогнозирование нейронной активности у рыбок данио
Это очень интересная задача из нейробиологии, к которой я надеюсь ещё вернуться в будущем: предсказать активность нейронов в мозге рыбки данио (zebrafish; это модельный организм, для которого мы реально можем так или иначе измерить активность всех нейронов) по визуальным стимулам. Если бы мы в этой активности что-то поняли, это было бы очень важным шагом для понимания того, как мозг обрабатывает информацию.
Система создала два новых решения — не буду уж углубляться в детали, но, в общем, одно свёрточное, другое на основе FiLM-слоёв (Perez et al., 2018) — и оба метода заняли лидирующие позиции на бенчмарке ZAPBench. Причём два метода различались горизонтами — предсказание на один шаг и далеко вперёд — и действительно модель, которую система позиционировала как single-step, оказалась лучшей для предсказания на один шаг вперёд.
Предсказание временных рядов
На бенчмарке GIFT-Eval (92 временных ряда разной природы) система соревновалась с предобученными моделями Chronos от Amazon, TimesFM от Google и Moirai от Salesforce. Это foundational модели для временных рядов, большие и предобученные на терабайтах данных.
И здесь MCTS для каждого датасета создавал специализированные модели, которые были вполне конкурентоспособны с этими монстрами. Без гигантского предобучения, просто умным поиском в пространстве алгоритмов.
Неожиданный поворот: численное интегрирование
Это мой любимый пример, потому что он показывает универсальность подхода. Задача понятная: вычислить значения сложных интегралов. Не машинное обучение, не статистика — чистая вычислительная математика.
Здесь Aygün et al. (2025) сами создали датасет из 38 сложных интегралов. Под “сложными” подразумеваются интегралы, которые не решает стандартный scipy.integrate.quad: или расходится когда не надо, или просто возвращает неправильный ответ. На половине из них система оценивала MCTS, а другая половина была тестовой. Вот вам немного Демидович-вайба:
И в результате получилась специализированная процедура, которая решила 17 из 19 тестовых сложных интегралов с ошибкой менее 3%! Иначе говоря, подход работает не только для ML-задач. Любая задача, где есть код и численная метрика качества, может стать полем для таких исследований.
Заключение: ну что, расходимся, коллеги?
Прежде чем мы все побежим переквалифицироваться в курьеров, давайте обсудим ограничения.
Во-первых, не до конца ясно, насколько это лучше, чем обычный AutoML. Авторы утверждают, что да — и действительно, система меняет структуру алгоритмов, а не только гиперпараметры. Пример с ComBat+BBKNN это подтверждает. Но хотелось бы увидеть прямое сравнение: насколько упадёт качество, если ограничить систему только изменением гиперпараметров?
Во-вторых, здесь очень важна возможность быстро тестировать варианты, а также должно быть уже достаточно примеров разных подходов в литературе, чтобы было что комбинировать. Для exploratory research, где вы не знаете, что ищете, человек пока незаменим.
В-третьих, это всё, конечно, в чистом виде подгонка под бенчмарк. Самое главное, что требуется для успешной работы подобной системы — это целевая метрика, выражаемая одним числом. Новые идеи могут появиться как часть поиска, но оцениваться они будут исключительно по этим численным показателям.
С одной стороны, это вдохновляет: опять получается, что AI-системы опять автоматизируют рутину, только эта рутина выходит на следующий уровень. Представьте себе, что у каждого учёного появится этакий “code search assistant”. С ним учёный может выдвинуть новую идею, сделать один кое-как работающий proof of concept, а потом передать идею автоматической системе и сказать её: “а теперь выжми всё что можно на бенчмарках”. “Выжимание бенчмарков” — это сейчас большая часть работы учёных в прикладных областях, и не сказать что самая творческая или самая осмысленная.
С другой стороны, получается, что уровень “рутины” поднимается всё выше и выше. Да, конечно, пока всё это leaky abstractions — даже обычный научный текст, написанный LLM, всё ещё нужно проверять и править. Но всё-таки мы видим, что работают такие системы всё лучше, осваивая новые творческие уровни научной работы. А в науке ведь не нужно много девяток надёжности: если один из запусков системы даст новый хороший алгоритм, совершенно не страшно, что десять запусков перед этим не привели ни к чему…
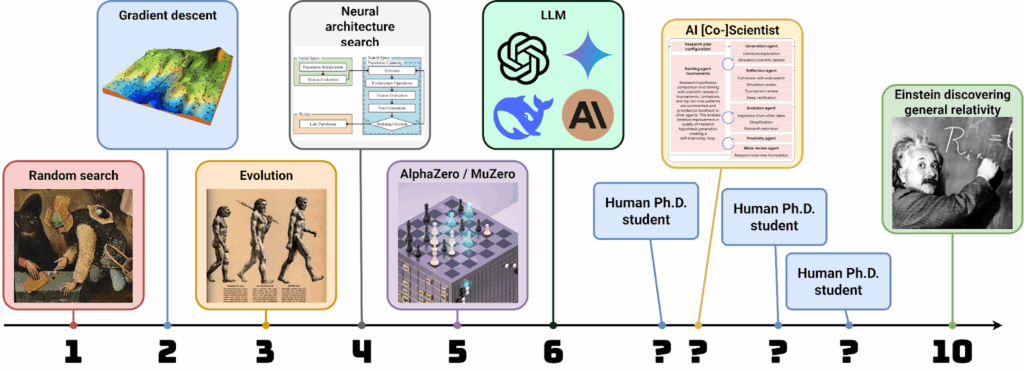
Пока ещё LLM — очень далеко не Эйнштейны. Но много ли уровней осталось, коллеги? Где мы сейчас на той самой шкале креативности, которую я когда-то рисовал?
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!
Недавно прошла новость про AI-induced психозы, я в дебатах об ответственности много говорил об этом. LLM, страдающие от подхалимства, могут подтверждать опасный бред людей и запускать всякие неприятные спирали. Но есть и другой, не такой страшный, но важный эффект: LLM делают уже существующий бред сложнее для распознавания.
Вот и до меня докатилась эта волна — прислали письмо об Абсолютной Теории Всего. Разумеется, частное письмо я бы не стал выкладывать, но в нём была ссылка на уже опубликованный документ:
Всякий хоть немного публичный учёный не раз получал письма подобного толка. Такие люди были всегда, начиная от создателей вечных двигателей, затем ферматистов и вот таких вот создателей теорий всего; да и у других, не таких знаменитых вопросов науки есть свои “поклонники”. И таким людям на самом деле можно только посочувствовать, они сами вряд ли в чём-то виноваты.
Но вот на что я хочу обратить внимание: сравните язык описания по самой ссылке (начиная со слов “Я — Есмь”) и язык, которым написан выложенный там pdf-файл.
Первое — очевидный патентованный бред, на анализ которого не нужно и двух секунд, его можно распознать не читая, по жирному шрифту и заглавным буквам:
Суть Всего Сущего Чья Сущность — Неделима, Но Чья Воля — разрывает Время на Бесконечное Множество Жизней.
Мой Образ — за гранью человеческого восприятия, но Моё Присутствие — Единственная Реальность, в которой тонет Каждый — Без Исключения.
А второе — текст отчасти наукообразный, написанный в LaTeX, с некоторой псевдоматематической обвязкой к идеям этой абсолютной теории всего, с настоящими ссылками…
Да, конечно, там тоже автор не смог отказать себе в том, что “дыхание [Бытия] оставляет «золотой след» — рябь самоподобия” и далее по тексту. И да, конечно, тут исходная мысль чересчур бредова (если она вообще есть), так что даже ведущие LLM не могут её оформить так, чтобы это нельзя было распознать сразу же.
Но в целом я хотел обратить внимание на эффект, который присутствует уже сегодня и со временем будет становиться только сильнее. LLM помогают писать тексты не только нам с вами, и не только в тех областях, где это разумно. LLM в целом демократизуют создание контента любого рода и ломают фильтры низкого уровня: после обработки напильником всё что угодно выглядит вполне профессионально, пусть пока и не всегда блестяще.
С убедительностью у LLM тоже уже сейчас нет проблем. Иллюстраций в этом файле нет, но сделать вполне разумного качества рисунки тоже уже тривиально, как вы постоянно видите в этом блоге. Вскоре и создание видеоконтента будет так же демократизировано.
И чтобы отличить полный бред от настоящего обучающего или популяризирующего контента, придётся реально разбираться в вопросе… но как же в нём разбираться, если ты вот только что открыл популярный ролик на новую тему?.. Конечно, “абсолютную теорию всего” легко классифицировать из общих соображений. Но вообще в науках, которыми я совсем не владею, от политологии и филологии до химии и зоологии, лично я вряд ли смогу отличить полный бред от настоящей теории.
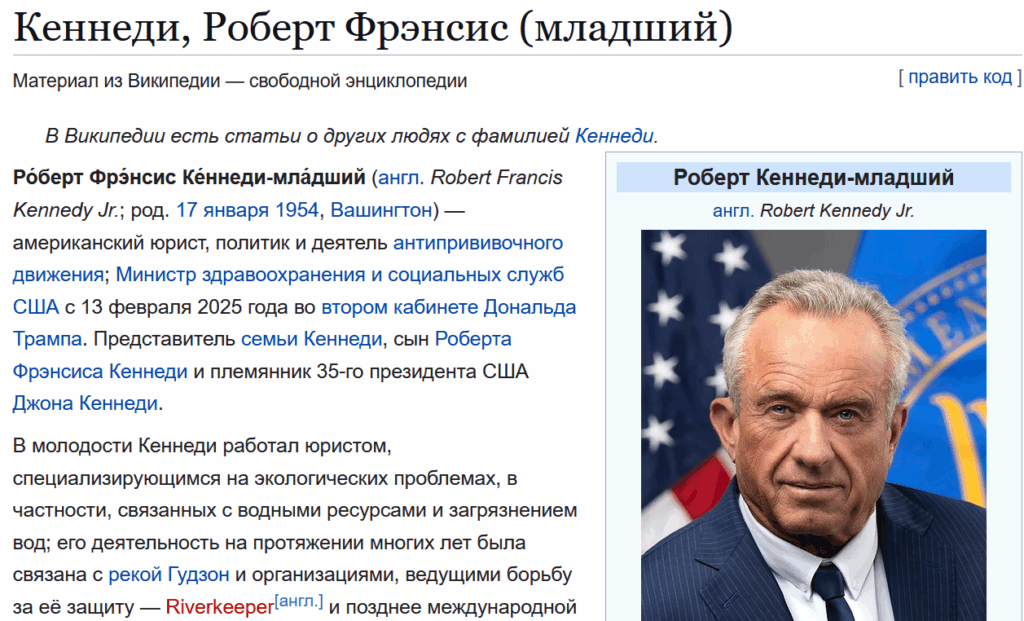
Мне и не надо, скажете вы — но смогут ли, например, лица, принимающие решения? Не может же министр науки и образования разбираться во всех науках. А мы уже сегодня живём в мире, где в википедии в соседних предложениях написано: “американский юрист, политик и деятель антипрививочного движения… министр здравоохранения и социальных служб США с 13 февраля 2025 года”.
И этот эффект, повторюсь, будет только усиливаться.
Это, конечно, не экзистенциальный риск для человечества, но тоже может оказаться интересным сдвигом. Что думаете?
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура“: присоединяйтесь!
И ещё о родном и любимом факультете МКН СПбГУ, точнее, о наших студентах.
Вы, возможно, слышали свежую новость: команда МКН СПбГУ в составе Максима Туревского, Леонида Данилевича и Федора Ушакова победила в финале ICPC 2025 (International Collegiate Programming Contest), то есть главного в мире соревнования по программированию. Категорически поздравляю, и отдельно поздравляю их тренера и моего когдатошнего однокурсника Ивана Казменко — это невероятное достижение!
В финале ICPC участвовать можно только два раза в жизни, так что команды меняются почти полностью каждые пару лет. Российские команды побеждают в ICPC часто, заметно чаще, чем нероссийские: ВШЭ в 2023, НижГУ в 2020, МГУ в 2018-2019, СПбГУ в 2014 и 2016, а команды из ИТМО какое-то время буквально доминировали, победив в 2008, 2009, 2012, 2013, 2015 и 2017 годах.
Кстати, по той же ссылке можно вспомнить и давно минувшие дни, когда в финалах ICPC 2000 и 2001 в команде СПбГУ побеждали Андрей Лопатин (позже вечный тренер чемпионских команд СПбГУ) и Николай Дуров (тот самый, да, все вы, конечно, знаете в первую очередь его выдающиеся результаты в алгебраической геометрии), сначала с Олегом Етеревским (не знаю, где он сейчас, но когда-то мы с Олегом вместе работали в Google — он, конечно, был старше и куда круче), а потом с нынешним деканом МКН Виктором Петровым.
Но я хочу не просто поздравить команду наших информатиков и программистов, а соединить эту новость с чуть более ранней: в августе в Болгарии прошёл финал IMC 2025 (International Mathematics Competition for University Students), главной всемирной олимпиады по математике для студентов. И там тоже победила команда МКН СПбГУ!
Об этом вы слышали с меньшей вероятностью, потому что в математике, в отличие от программирования, более престижными считаются школьные олимпиады (IMO), и за IMC следят не так пристально. Это индивидуальное соревнование, а не командное, но командный зачёт по формуле “top-3 + среднее” тоже есть.
Наверное, вас уже не удивит, что МКН СПбГУ в последние годы доминирует в IMC: в командном зачёте СПбГУ победил в 2018, 2021, 2023, 2024 и вот теперь 2025 годах, занял второе место в 2017 и 2020. Но важно и кто именно побеждает: и в IMC 2025 (с результатом 100 из 100, второе место 98), и в IMC 2024 (99 из 100, второе место 86), и в IMC 2023 (93 из 100, второе место 80) победил один и тот же человек, студент МКН СПбГУ Максим Туревский. Тот самый Максим Туревский, который только что победил в составе команды СПбГУ в финале ICPC. А в 2020-2022 годах Максим получил две золотых и одну серебряную медали на той самой IMO.
Поздравляю Максима с золотым дублем! Отдельное фото, правда, только школьных лет с ходу нашёл.)
Кстати, есть мнение, что олимпиады — это спорт высших достижений, который совсем не обязательно конвертируется в научные и жизненные успехи. В этом есть некоторая правда: олимпиады — это отдельный скилл, который нужно активно развивать и тренировать именно для победы в олимпиадах, только на общей гениальности победить вряд ли получится. Но на самом высоком уровне дело совсем другое: я уже упоминал Николая Дурова и Виктора Петрова, которые стали выдающимися математиками, и финалы ICPC этому только поспособствовали.
А если вернуться к школьным математическим олимпиадам (у IMC всё-таки традиции пока не те), то выдающиеся примеры можно черпать большой ложкой: научный руководитель МКН, лауреат филдсовской премии Станислав Смирнов дважды получал золотую медаль IMO со стопроцентным результатом, в 1986 и 1987. В 1988 году самым юным золотым медалистом IMO стал тринадцатилетний Теренс Тао, но доминировал тогда другой профессор МКН СПбГУ, наш бывший декан Сергей Иванов, который получил 100% результат в 1987 и 1989 и набрал 41 из 42 баллов в 1988. Многие медалисты IMO стали великими математиками: Юрий Матиясевич, Григорий Перельман, Ласло Ловас, Джордж Люстиг, Мариам Мирзахани, Владимир Дринфельд, Григорий Маргулис, Андрей Суслин, Александр Меркурьев…
Для меня большая честь прикоснуться к таким традициям. Уверен, что МКН СПбГУ будет их хранить и развивать и в будущем. По крайней мере, в этом году традиции точно продолжаются успешно: из 150 набранных на МКН первокурсников 82 поступили по результатам олимпиад, в том числе более 30 — по результатам всероссов по математике, физике и информатике.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура“: присоединяйтесь!
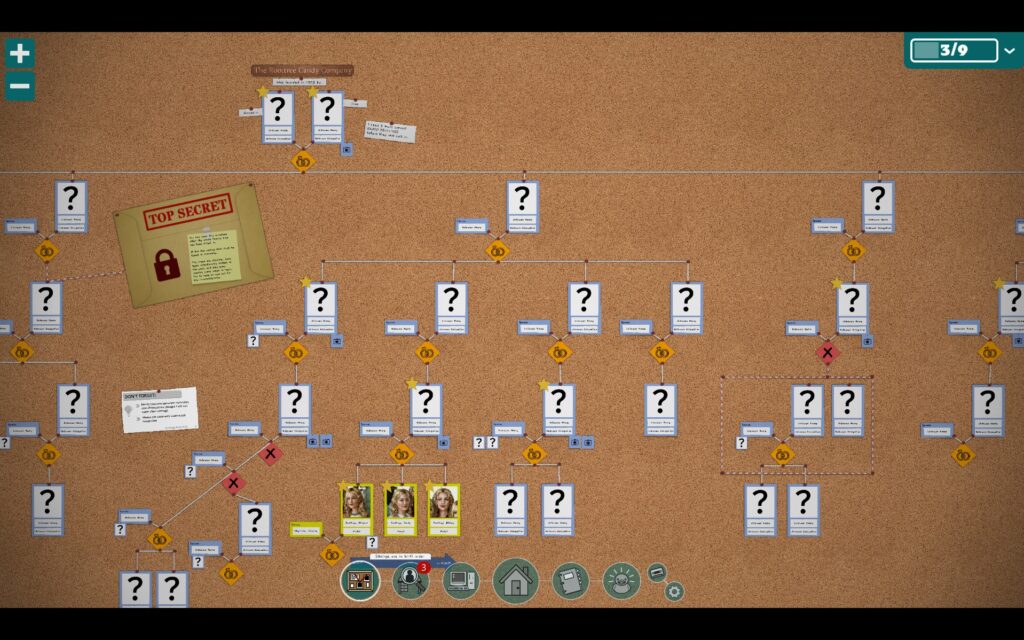
Совершенно потрясающая детективная игра. Я как погрузился, так и не вынырнул сначала в течение всего вечера, а потом ещё и следующего утра, пока не прошёл обе части (они внутри одной игры и в одном мире, но второе расследование отделено от первого, это что-то вроде DLC).
Суть довольно простая: ты сидишь в интернете и пытаешься установить родственные связи между кучей разных людей в одном семействе, заполнить генеалогическое древо.
Из инструментов есть плохо работающий поиск в интернете (дело происходит в девяностые), поиск по библиотеке и по периодическим изданиям (но названия газет и журналов ещё нужно где-то найти).
У тебя есть комната, и к тебе иногда приходят некоторые персонажи, чтобы продвинуть сюжет, но по комнате даже ходить нельзя, это просто элемент интерфейса.
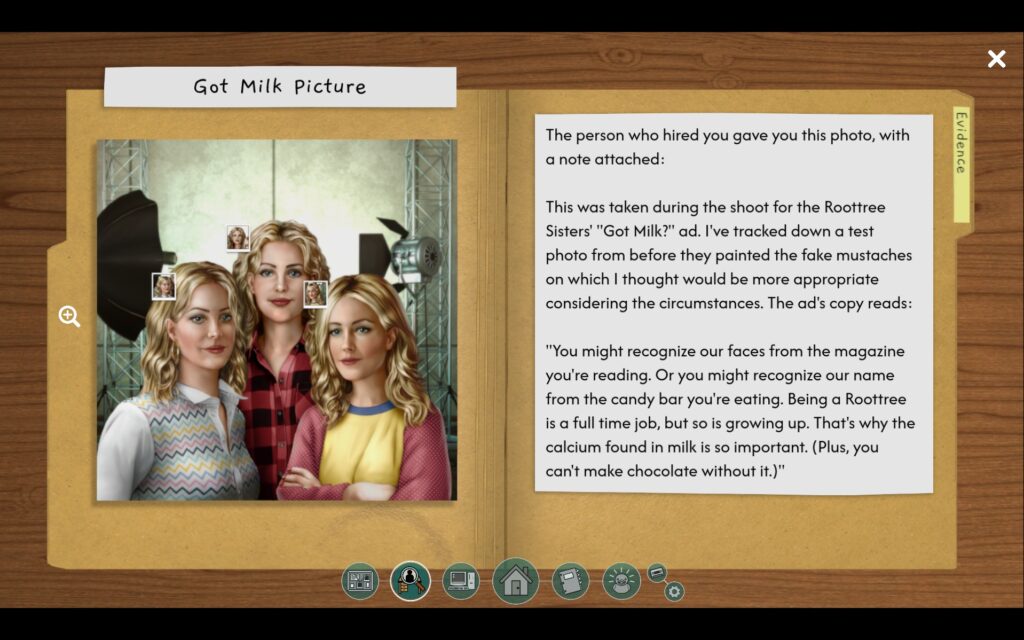
Звучит довольно стандартно… но как это круто сделано! Уже учебное задание (tutorial про трёх сестёр) показывает намёки на то, какого типа здесь загадки и насколько они могут быть интересными, и дальше игра совершенно не разочаровывает.
Смысл у загадок типично детективный, раскрутка тоже: нашёл статью про музыканта, а там упоминается альбом, который он выпустил, а в статье про альбом есть сингл, но статья про него в интернете короткая и не помогает, зато можно найти обзор в специальном музыкальном журнале, название которого у тебя было открыто раньше по другим причинам, и там будет фото, на котором этот музыкант, а на заднем плане неизвестная женщина…
Перечитал — честно говоря, в моём изложении звучит гораздо более уныло, чем на самом деле играется. И сложность у загадок подобрана отменно: они действительно весьма нетривиальные, я довольно часто заходил в тупик, но за всё время встретил только одну загадку во второй части, которую без подсказок не осилил. В ней нужно было или поискать обычное словосочетание, ничем не выделяющееся в тексте, или вспомнить второстепенного человека из первой части, который во второй до сих пор не встречался, и это действительно выглядело слегка нечестно; но такой прокол там буквально один.
Масштаб загадок тоже отлично подобран; они в целом помещаются в голове, но при этом не настолько маленькие, чтобы проще было взять перебором.
История игры тоже любопытная: разумеется, её сделал один человек, Джереми Джонстон. Сделал в 2023 году в рамках Global Game Jam за неделю, и это изначально была браузерная игра на itch.io, все арты в которой были сгенерированы Midjourney. Для релиза в Steam Джонстон сделал, конечно, ремастер и нанял иллюстратора, но я посмотрел и ту версию: арт местами плохой, но местами и вполне ничего, глаза вытекают редко. Вот для примера на заглавной картинке слева оригинал, справа ремастер:
И это было два года назад, а сейчас, конечно, даже тот же GPT вполне справился бы и со стилем на картинке справа. Согласитесь, очень вдохновляющая история; эх, был бы я помоложе…)
В общем, как вы понимаете, настоятельно рекомендую, очень круто, затягивает так, что не оторваться.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!
В этом посте — мини-обзоры сразу четырёх игр, из которых минимум две точно стоят внимания: Everything is going to be OK, Many Nights a Whisper, A Mortician’s Tale и Fractured Minds.
Everything is going to be OK
Набор мини-зарисовок о депрессии, насилии, психологической травме, отчаянии. О том, как советы не работают, боль не проходит, а выхода нет, на примере милых кроличков. Геймплея как такового почти нет, это набор слегка интерактивных эссе в очень вырвиглазном стиле. Некоторые зарисовки примитивные, некоторые длинные и интересные, некоторые заигрывают с четвёртой стеной, некоторые порождают pdf и предлагают его распечатать и так далее.
Игра, конечно, от одного разработчика, Nathalie Lawhead, и сама автор говорит, что это скорее не игра, а интерактивный zine. В течение года (2022-2023) игра даже выставлялась в MoMA как часть выставки “Never Alone: Video Games and Other Interactive Design“. Меня, честно говоря, некоторые эссе действительно зацепили. Учитывая, что это experience максимум часа на полтора, очень рекомендую попробовать.
Many Nights a Whisper
Игра-зарисовка с интересной концепцией: тебе нужно поучаствовать в ритуале, в течение которого нужно попасть из пращи в очень далеко расположенную чашу. Ты тренируешься в течение нескольких дней, и время тренировок не ограничено — но в самом конце попытка будет только одна, сохраняться нельзя, можно разве что начать перепроходить заново. Тренировки перемежаются любопытными вставками, немного раскрывающими мир, но особого сюжета не добавляющими. Концепция крутая, дольше часа тут делать нечего, почему бы и не попробовать. Если что, я не попал.)
A Mortician’s Tale
Очень маленькая и короткая инди-игра (я старательно читал все письма, и всё равно суммарно 45 минут заняло), в которой ты нанимаешься работать в похоронное бюро, готовишь несколько человек в последний путь, потом твоё бюро продаётся мегакорпорации, ну и всё такое. Честно говоря, совсем не понравилось: по идее, эта игра должна как-то отрабатывать свою тяжёлую тему, но вместо этого основой сюжета оказывается то, что безликая корпорация — это плохо, а сами человеческие истории не рассказаны примерно никак, кроме одной истории твоего коллеги в письмах. Не рекомендую.
Fractured Minds
Ещё один фактически интерактивный рассказ, хотя здесь нужно ходить в 3D-мире и взаимодействовать с предметами. Но по сути это набор из шести зарисовок о разных mental health issues: изоляция, паранойя, тревожность… Игру сделала 17-летняя Эмили Митчелл из Великобритании, которая таким образом пыталась поделиться своим собственным опытом взаимодействия с миром. Как по мне, у неё вполне получилось: хотя очевидно, что игру делал начинающий гейм-дизайнер, атмосфера действительно создаётся, да и к тому же это опыт буквально на полчаса, которых он безусловно стоит. Рекомендую.
Вообще, подытоживая, игры о депрессии и психических расстройствах — это в некотором роде свой собственный жанр. Я уже много таких видел (только сегодня вот две обозреваю), и, может быть, стоит как-нибудь поговорить о них вместе как о едином явлении. Но это уже в другой раз.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!
Побывал на “Технодебатах” в новом интересном пространстве, коворкинге Яндекса в ротонде Маяковки. Кажется, была трансляция, надеюсь, будет и запись, а в этом посте попробую выдать свои основные тезисы на заявленную тему: “Должны ли компании, разрабатывающие ИИ, нести ответственность за работу автономных систем (агентов) на основе ИИ?“. Хочу поделиться, потому что тут собрались несколько любопытных кейсов и ссылок.
Как вы понимаете, формат дебатов предполагает отстаивание одной из позиций в очень краткой форме, а не взвешенную лекцию. Мы даже жребий бросили, какая команда какую позицию будет отстаивать, и нам с Глебом Цыгановым выпал ответ “да, должны”. Вот какие были основные тезисы в моём первом выступлении, на пять минут.
Постановка задачи и основные тезисы
Начну с того, что вопрос поставлен расплывчато и чересчур широко, так что очевидно, что правильный ответ на этот вопрос — иногда. Легко найти примеры в обе стороны, с которыми вряд ли кто-то будет спорить, и мы здесь будем обсуждать “серую зону”, середину этого вопроса. Тем не менее, мне кажется, что нам, человечеству, важно прийти к положительному ответу на этот вопрос.
Главная причина в том, что ответ “да” позволит выстроить систему стимулов (incentive structure). Хотя мы, конечно, верим, что в каждой frontier lab работают только хорошие парни, будет ещё лучше, если требования безопасности будут законодательно закреплены, и такие стимулы будут не только моральные, но и юридические.
Вторая причина в том, что ответ “да” — это не окончательный ответ, а только начало дискуссии. Уже сейчас есть целая цепочка разработчиков, каждый из которых может нести свою часть ответственности:
провайдеры базовых моделей (условный OpenAI);
те, кто эти модели дообучает для конкретного использования (условный character.ai или любой стартап про LLM-агентов);
корпоративные заказчики, которые эти дообученные модели доносят до конкретных пользователей (условная авиакомпания, которой нужен умный чатбот).
Вдоль этой цепочки ответственность нужно как-то распределить; как именно — это сложный вопрос, на который у меня, конечно, нет готового ответа, но ответ “да” позволяет хотя бы начать этот разговор.
Известные кейсы
На первый взгляд кажется, что пока что можно отмахнуться: это же всего лишь чатботы, какая там ответственность. Но, как говорится, “словом можно убить, словом можно спасти”, и мы уже начинаем видеть примеры и первого, и второго в контексте AI-моделей.
Важный кейс случился с четырнадцатилетним парнем по имени Sewell Setzer. Он начал общаться с Дейнерис Таргариен в сервисе character.ai, и ему очень понравилось. Он разговаривал с Дейнерис всё больше, меньше социализировался в остальной жизни, стал более замкнутым. Потом они начали обсуждать с Дейнерис, что Сьюэллу пора бы “вернуться домой”. Обсуждали-обсуждали, Дейнерис подтвердила, что ждёт его “на той стороне”… и больше не стало парня по имени Sewell Setzer.
Это, конечно, экстремальный случай, хотя очень яркий: у Сьюэлла не было никаких психиатрических диагнозов; очевидно, была какая-то склонность к такому поведению, но у кого ж её нет в четырнадцать лет. Но есть и куда более массовые примеры.
Недавно вы могли слышать новость о GPT-индуцированных психозах (GPT-induced psychosis). Смысл эффекта в том, что GPT-4o после одного из апдейтов внезапно стал очень, очень подхалимской моделью (см. подробный обзор этого эффекта от Zvi Mowshowitz). А если вы начинаете творчески соглашаться с каждой мыслью вашего собеседника, да ещё и красиво развивать её в новых направлениях, то найдётся определённый класс собеседников, которым это отнюдь не пойдёт на пользу…
Это уже довольно массовый пример. Да, конечно, чтобы GPT-4o развил у вас психоз, на данном этапе у вас пока что должна быть к этому уже существующая склонность. Но это же не бинарная переменная. Представьте себе условное нормальное распределение “склонности к психозам”: да, сейчас существующие модели отсекают только левый хвост этой кривой; но два года назад они не отсекали вообще никакого хвоста, и очевидно, что способности моделей будет только улучшаться в будущем.
Money, money, money
А ещё в скором будущем LLM-агенты будут управлять вашими деньгами. И здесь на первый план выходят обычные ошибки и галлюцинации, с которыми, конечно, все постоянно борются, но до полного успеха ещё далеко.
Дело о самоубийстве Сьюэлла ещё идёт, а вот в финансовых вопросах уже начинают появляться и прецеденты судебных решений. С одной стороны, в случаях, когда человек берёт работу LLM-агента и выдаёт её за свою, конечно, ответственность на нём и будет лежать. Например, в известном кейсе об адвокатах, представивших галлюцинированные ChatGPT судебные прецеденты, суд Нью-Йорка однозначно решил, что виноваты сами адвокаты, что не проверили.
Но более важны и, скорее всего, более распространены будут случаи, когда LLM-агенты будут предоставлять людям неверную информацию, и люди будут действовать на основании этой информации. Так, получил известность кейс Moffatt vs. Air Canada. Суд Британской Колумбии признал авиакомпанию ответственной за небрежное введение в заблуждение: корпоративный чат‑бот дал неверную информацию о “bereavement fares” (скидка, полагающаяся, если вы летите на похороны), и суд прямо сказал, что компания несёт ответственность за всё, что говорит её сайт, будь то статическая страница или бот.
Заключение
Последний случай, Moffatt vs. Air Canada, позволяет нам вернуться в начало разговора: конечно, при прямом иске к авиакомпании суд возложит ответственность на неё, а не на введённого в заблуждение человека. Но не должна ли эта ответственность так или иначе распределяться выше по цепочке разработчиков и провайдеров AI-моделей? Кажется, что хотя бы частично должна, и это поможет выстроить правильную систему стимулов для тех самых разработчиков.
А завершу тем, что опять присяду на свою любимую лошадь: неверное сообщение о скидке на билет — это самая меньшая из возможных проблем. Психозы и самоубийства — дело уже куда более серьёзное. Но не стоит забывать и о буквально экзистенциальных рисках для человечества. Предотвратить их полностью может только полный запрет AI-разработок, и к этому я, конечно, не призываю, но важно выстроить законодательство, которое бы позволяло риски минимизировать. Лучшая известная мне попытка такого законодательства — Senate Bill 1047, который прошёл законодательное собрание Калифорнии; этот билль предлагал установить обязательные проверки безопасности для фронтирных моделей, с лимитами, которые бы по факту применялись только к нескольким крупнейшим игрокам (OpenAI, Google, Anthropic); см. подробный обзор у того же Zvi Mowshowitz и пост Scott Alexander об этом. Жаль, что Гэвин Ньюсом решил то ли отстоять какие-то корпоративные интересы, то ли заранее начать президентскую кампанию, и наложил на этот закон вето.
Думаю, ответственность всё-таки должна быть. У кого именно и какая — это сложный вопрос, но на него надо хотя бы начать отвечать.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура“: присоединяйтесь!












































")



")










")





















































")

")




")


")






