Meet our distinguished guest for the third interview: Professor Victor Lempitsky. Prof. Lempitsky is among the best researchers in machine learning, placing especially highly in the field of computer vision (here is his Google Scholar account). Currently Victor is leading the Computer Vision Group at Skoltech (Skolkovo Institute of Science and Technology) and is the VR project leader at Yandex.

Foreword. Before we begin, I have to say that this interview was composed before February 24, 2022. In fact, it was finalized on February 22, so by now it is almost half a year old. This is the reason why Q6 may look a little strange these days—we were not dancing around the elephant in the room, it simply had not entered yet. By now, Victor has left both positions mentioned in the preamble and is currently working on a new startup in the AR/VR field.
Q1. Hello Victor, and welcome to our interview! Computer vision is your major focus, so let me start off immediately with the obligatory question for our blog: what is your general view on synthetic data for computer vision? Do you agree that synthetic data, understood as artificially generated labeled data used to train machine learning models, can be a feasible way out of the data problem for computer vision? Or do you place more faith in other possible approaches that we’ve previously discussed on this blog: augmentations, mixup and self-adversarial training, few- and zero-shot learning, adding unlabeled data, and others?
I do believe in synthetic data, and several recent projects I was involved with have seen clear benefits from using synthetic data. However, most useful synthetic data are modeled from the real world. Such modeling can benefit strongly from unsupervised learning. So, in the end, there is no dichotomy: I believe in the usefulness of synthetic data, which is enriched/created from real unlabeled data. Augmentations, mixups, adversarial training can all be used as the ways to generate useful synthetic data from real data, even though people not always think about augmentations in this way.
Q2. Much of your most recent work is devoted to image generation. You have created GANs that work without convolutions or self-attention, neural renderers that can dress 3D avatars and generate semi-transparent objects, GANs that generate timelapse videos of landscapes, and much more. In particular, you often work on 3D generation—generating meshes, textures, point clouds—which is the obvious next step after learning to generate flat images. 3D generation is only starting to work well enough for practical applications, but still, the rate of progress in this field is spectacular. I usually show this picture in my lectures on GANs:

Do you expect 3D generation to undergo similarly explosive growth in the near future? Or are there conceptual difficulties that need to be resolved before we get the virtual reality Metaverse generated on the fly with GANs?
The picture you show is indeed very telling, and it reflects and conflates several trends: improvements in algorithms, improvements in computational resources, and improvements in datasets.
Given how many bright people are now working on 3D data synthesis, I believe that fast progress in algorithms is inevitable. Neural renderers such as PyTorch3D or nvdiffrast are certainly one piece of the puzzle. Computational resources are trickier and a lot of progress will be bottlenecked on them, so I naturally expect that main breakthroughs will come from the “big four” of NVidia, Google/DeepMind, Meta, and Microsoft (all four have brilliant researchers but also huge computational resources). This was to a large degree true even for 2D image generation, and will likely remain even more true for 3D. Note that I am not saying that everybody else should either join those corporations or work on something else. Just like StyleGAN(s) from NVidia created a whole vibrant ecosystem of researchers from different institutes building on top of it, the same will likely happen with 3D.
The main bottleneck for progress in 3D data synthesis, however, is (and will be) datasets. Here things are very different from 2D. With 2D, once algorithms and resources were ready, finding good enough datasets for learning was relatively easy. Note that here I am talking about 2D static image generation, good datasets of HD videos are much harder to get: say, YouTube is largely not HD quality, and it is quite a challenge to scrap video datasets of objects or people in high resolution from YouTube. Getting good and large 3D datasets is much harder, especially if we are talking about “full 3D” and not just 2.5D (i.e. color + depth) or toyish 3D models. Currently, quite a few researchers are trying to bypass this lack of datasets and to learn 3D synthesis by matching the 2D images. To this end, they insert 2D projections into their generation learning pipelines. This is surely interesting and could be fruitful, but is inevitably much harder. Just imagine someone trying to learn StyleGAN-like image synthesis while only having access to a dataset of 1D projections such as row sums or one-pixel slices.
To sum up, I think that the rate of progress in 3D data synthesis will be limited and conditioned on the quality of 3D datasets. Hence, it will be a harder and longer story than with 2D (but no less interesting!)
Q3. Let us continue from the last question, taking generative models yet further into the realm of speculation. I have always viewed image and 3D generation as an inherently finite task. It has not been easy to scale GANs up, but it seems like progress is inevitable. And human eyes have a finite resolution after all (be it 8K, 32K, or 256K), so the models will sooner or later reach this resolution with photorealistic quality, and there will be no point to move any further.
Do you agree with this view, and if yes, when do you expect image and 3D scene generation to hit this ceiling and provide a perfectly immersive experience? (Let’s limit this question to vision, I understand that full immersion will require other senses as well.)
Let me start by noting that the story with 2D image generation is far from over, even if one can generate very realistic human faces. First of all, GANs still have limited diversity and mode coverage (otherwise we will not have dozens of interesting papers on StyleGAN inversion, and very simple approaches would do the job). Diffusion models are better than GANs in covering the whole distribution but are still extremely slow. Furthermore, even though GAN samples for faces are realistic, GAN samples for full body human images or, say, for full body cats are either significantly less realistic or significantly less diverse (or both). Finally, for 2D video synthesis, we as a community are very far from truly realistic results (at least in the unconditional setting).
Regarding 3D, the situation is even harder for the reasons I discussed in the answer to the previous question, so I do not expect perfect photorealism there for quite a few years.
Q4. Now let me ask a (slightly more) technical question that I’ve been interested in for a long time. Your two most cited papers according to Google Scholar are “Unsupervised domain adaptation by backpropagation” (joint work with Yaroslav Ganin) and its continuation and extension, “Domain-adversarial training of neural networks” (with a lot of people including, e.g., Hugo Larochelle). They are also, in my opinion, some of the most relevant for synthetic data because they present a simple and ingenious domain adaptation method.
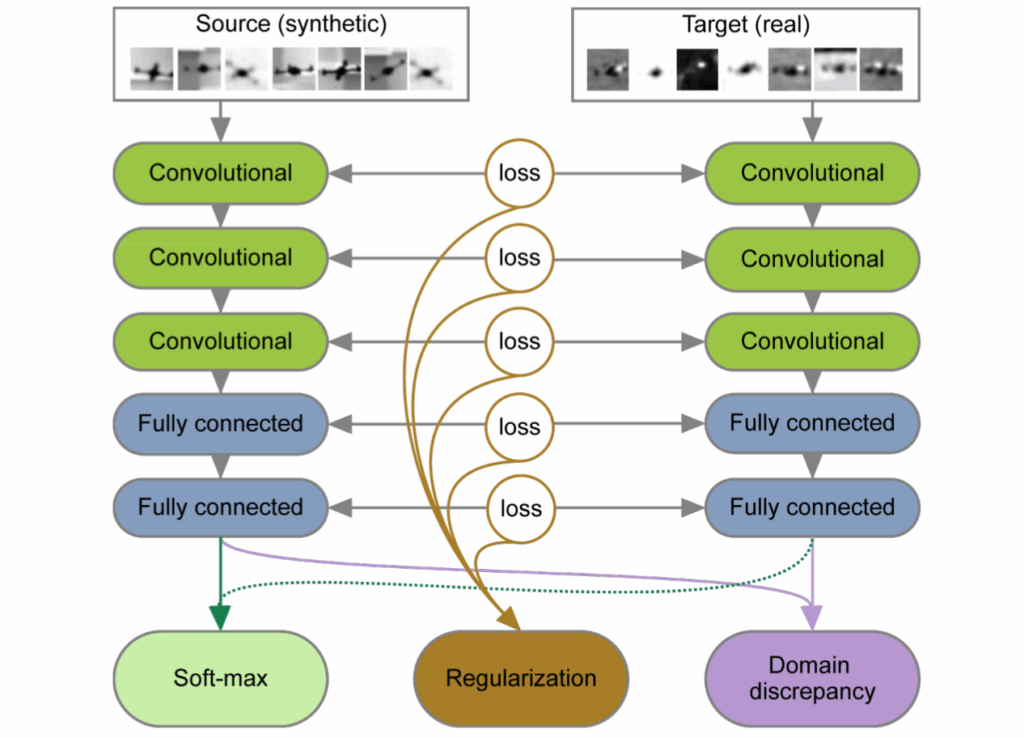
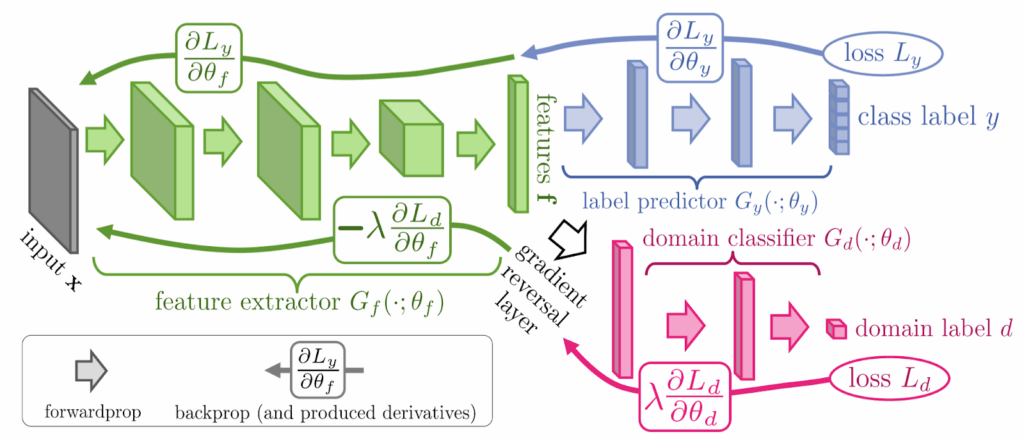
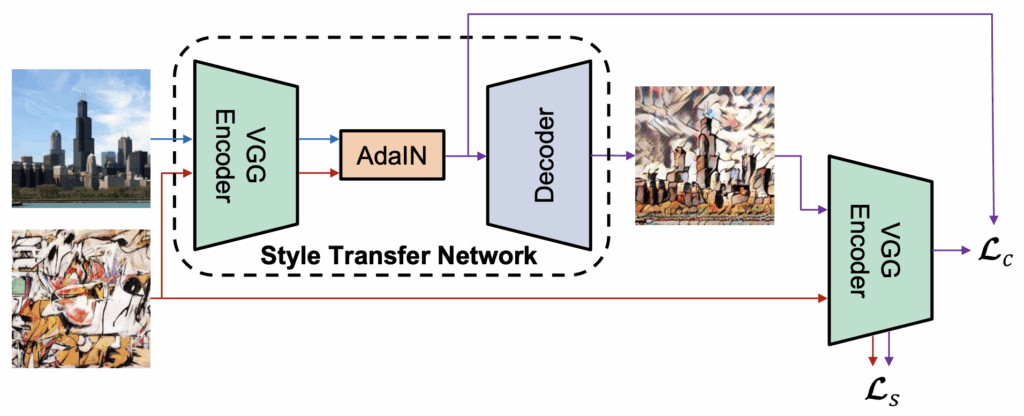
We have just discussed the basic idea of Ganin and Lempitsky (2015) on this blog, so I’ll be very brief in explaining it. The idea goes as follows: suppose you want to have a model that works for both synthetic and real data (or any two domains, really). You want to train a feature extractor that will extract features independently of the domain, so that, say, a synthetic face will have the same features extracted as its real counterpart, and models trained with these features on synthetic data can be applied to real data. To achieve this, you add a domain classifier that predicts whether it was a synthetic or a real image based on the features extracted. You want that classifier to fail, just like you want the discriminator to fail in GANs. So you train it as another head of your network, but the gradients for the classification error function are reversed, optimizing it in the opposite direction. In the illustration below (taken from your papers), the classifier wants to minimize its loss Ld, but by the time it gets to the feature extractor, the loss is inverted, and the extractor is actually maximizing it.
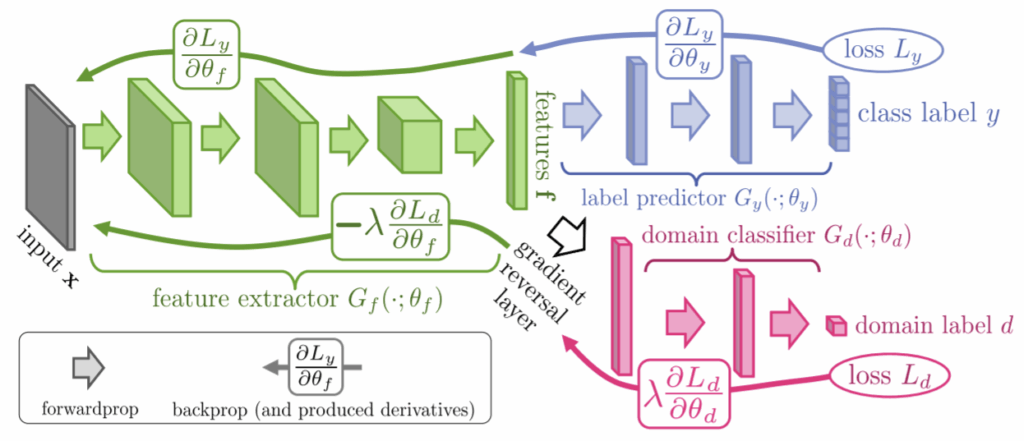
My question here is two-fold. First, I explained your idea in terms of synthetic and real images, and the actual papers also present examples of synthetic-to-real transfer, but only for small images. Have there been attempts to apply this to larger-scale domain adaptation, especially synthetic-to-real, and how successful have they been?
Second, domain-adversarial training sounds like a very general idea that could actually be applicable wider than just domain adaptation. One cannot say this idea is not widely known: both papers have thousands of citations, including foundational works on GANs. But why haven’t GANs switched to gradient reversal instead of alternating training between the generator and discriminator? Are there some hidden problems here that are not evident in the basic idea?
On your first question, indeed the approach has become popular, and there has been a lot of follow-up work including applications to large images. Just as with small images, the approach there works somewhat but without miracles. I.e., it usually beats the no-adaptation baseline quite confidently, but, of course, does not solve the domain gap problem completely. For the second question, indeed almost all GANs separate the steps for the generator and the discriminator updates and do not reuse the gradient. The main reason, I believe, is that most modern GANs use slightly different functionals as objectives for the generator and the discriminator. In particular, it turns out that to get the best GAN performance, it is useful to have some form of the so-called non-saturating objective for the discriminator, and also to regularize the discriminator quite strongly with a proper regularizer (and details of such regularization matter a lot). So, when your generator and discriminator are trying to optimize slightly different functionals, gradient reuse becomes highly non-trivial and is therefore not used.
Just to clarify, for me the difference between gradient reversal and GANs is not a big deal. Actually, we learned about the GAN arxiv report halfway during the project and by that time we have settled on the idea and the language of “gradient reversal”. This is why we explained our approach in a slightly different way in our paper, and perhaps connected it to GANs in a less clear way than we should have done (but back in early 2015 it was way less obvious that GANs would become such a dominating idea).
Q5. Another recent work of yours introduces Cloud Transformers, special architectures for processing point clouds that use ideas similar to self-attention blocks, with excellent results in point cloud segmentation, inpainting, and reconstruction tasks.
Since their inception in 2017, Transformers have taken deep learning by storm. They started by basically replacing all other embeddings in natural language processing and serving as the basis for the very best language models, but now they are all over computer vision as well, ever expanding their reach as your own work suggests. It looks a bit like deep learning gradually taking over every field in the early 2010s.
Do you have an explanation for this success? I understand how a Transformer works mathematically, but is there any explanation why self-attention proves to be such a good idea in practice?
Or maybe it’s just an umbrella term for a specific useful trick, and otherwise modern Transformers are very different from each other? In your paper, you keep using words such as “variant” or “reminiscent”, and the architecture indeed doesn’t look much like Vaswani’s original. What is that core idea that makes an architecture a Transformer, and again, why, in your opinion, does it work so well?
Well, it is hard to argue that transformers are the most exciting and impactful thing that has happened in deep learning in recent years. What is most exciting about transformers is their universality. True, we are still witnessing the competition between vision transformer variants and ConvNet architectures for the title of “the king of ImageNet”. But what is remarkable and makes many people excited is that very similar Transformer architectures can solve very different tasks across very different modalities (images, audio, text, action planning, etc) with near state-of-the-art quality. Certainly, it feels like the right thing, as our brains also have remarkable plasticity and can repurpose different parts between modalities.
Our cloud transformers paper will obviously be far less impactful compared to the original transformers, but I still like it very much. Our architecture is similar to “classical” transformers in some ways. E.g. it treats individual points as elements within an unordered set, and our key layer uses multiple processing heads. There are also differences (our equivalent of attention is sparse, and we use convolutions). Still, what I liked about our results is that essentially the same architecture is able to solve very different point cloud processing tasks. This is again reminiscent of the general transformer idea.
Q6. And finally a (slightly) more personal question. Anyone who knows you personally or at least follows you knows you feel strongly about the ethical use of AI.There is a trend in the computer vision community about ethical usage of CV technologies. For instance, the creator of YOLO object detectors Joseph Redmon quit computer vision in early 2020 and famously explained his decision as follows: “I stopped doing CV research because I saw the impact my work was having. I loved the work but the military applications and privacy concerns eventually became impossible to ignore.”
What is your view on the ethical concerns that arise in modern computer vision? Are researchers responsible for potentially unethical uses of their results? I suppose there is no way to stop progress, but do you think there may be ways to ensure that progress works for the benefit of humanity and not against it? What would you advise to work on if one wanted to achieve this goal?
I had a small project on person re-identification (mostly from surveillance cameras) with my PhD student back in 2016, and after one year or so we stopped. I do not think we pushed state-of-the-art in video surveillance that much, and the reviewers for the submissions we made on the subject concurred with that :). It is the only example where, in retrospect, I sleep slightly better because my work did not make an impact.
Having said that, some of the good and well-meaning people that I know still work on face recognition and camera-based surveillance, and I do not want to judge them. After all, the camera-based surveillance technology is double-edged. It will most likely benefit strong democratic societies by making life there safer and more convenient, but it will make life in authoritarian and totalitarian societies considerably worse, which we are already starting to witness in Russia and other countries. The same actually goes for AI and automation issues. The net effect will be strongly positive, people will live more meaningful and productive lives with more interesting occupations, but the dystopian scenarios will also materialize in some societies.
Like always, stopping the progress is impossible, even if many strong researchers including Joe Redmon quit the area. Progress in AI-based surveillance and automation “simply” calls for better and stronger political institutions. And the faster the progress, the more urgent the call. I know this all sounds like I am trying to push the responsibility from AI researchers to others (civil society and politicians), but I am just being honest and realistic. The best thing that we (researchers) can and must do is to inform the general public about the current state-of-the-art and reasonable projections for the future.
Victor, thank you very much for your answers! And you, dear reader, stay tuned for our next interviews!
Sergey Nikolenko
Head of AI, Synthesis AI