Here at Neuromation, we are always looking forward to the future. Actually, we are making the future. Thus, we are in a good position to try to predict what is going to happen with the AI industry soon. I know how difficult it is to make predictions, especially, as some Danish parliament member once remarked, about the future. Especially in an industry like ours. Still, here go my three predictions, or, better to say, three trends that I expect to continue for the next few years of AI. I concentrated on the technical side of things — I hope the research will stay as beautifully unpredictable as ever.
Specialized hardware for AI

One trend which is already obvious and will only gain in strength in the future is the rise of specialized hardware for AI. The deep learning revolution started in earnest when AI researchers realized they could train deep neural networks on graphical processors (GPUs, video cards). The idea was that training deep neural networks is relatively easy to parallelize, and graphic processing is also parallel in nature: you apply shaders to every pixel or every vertex of a model independently. Hence, GPUs have always been specifically designed for parallelization: a modern GPU has several thousand cores compared to 4–8 cores in a CPU (CPU cores are much faster, of course, but still, thousands). In 2009, this turned every gaming-ready PC into an AI powerhouse equal to the supercomputers of old: an off-the-shelf GPU trains a deep neural network 10–30x faster than a high-end CPU; see, e.g., an up-to-date detailed comparison here.
Since then, GPUs have been the most common tool for both research and practice in deep learning. My prediction is that over the next few years, they will be gradually dethroned in favour of chips specifically designed for AI.
The first widely known specialized chips for AI (specifically training neural networks) are proprietary Google TPUs. You can rent them on Google Cloud but they have not been released for sale for the general public, and probably won’t be.
But Google TPU is just the first example. I have already blogged about recent news from Bitmain, one of the leading designers and producers of ASICs for bitcoin mining. They are developing a new ASIC specifically for tensor computing — that is, for training neural networks. I am sure that over the next few years we will see many chips designed specifically that will bring deep learning to new heights.
AI Centralization and Democratization
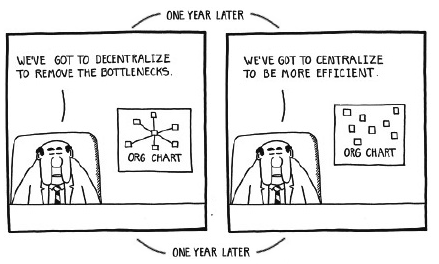
The second prediction sounds like an oxymoron: AI research and practice will centralize and decentralize at the same time. Allow me to explain.
In the first part, we talked about training neural networks on GPUs. Since about 2009, deep learning has been living in “the good old days” of computing when you can stay on the bleeding edge of AI research with a couple off-the-shelf GPU for $1000 each in your garage. These days are not past us yet, but it appears that soon they will be.
Modern advances in artificial intelligence are more and more dependent on computational power. Consider, e.g., AlphaZero, a deep reinforcement learning model that has recently trained to play chess, go, and shogi better than the best engines (not just humans! AlphaZero beat Stockfish in chess, AlphaGo in go and Elmo in shogi) completely from scratch, knowing only the rules of the game. This is a huge advance, and it made all the news with the headline “AlphaZero learned to beat Stockfish from scratch in four hours”.
Indeed, four hours were enough for AlphaZero… on a cluster of 5000 Google TPUs for generating self-play games and 64 second-generation TPUs to train the neural networks, as the AlphaZero paper explains. Obviously, you and I wouldn’t be able to replicate this effort in a garage, not without some very serious financing.
This is a common trend. Research in AI is again becoming more and more expensive. It increasingly requires specialized hardware (even if researchers use common GPUs, they need lots of them), large datacenters… all of the stuff associated with the likes of Google and Facebook as they are now, not as they were when they began. So I predict further centralization of large-scale AI research in the hands of cloud-based services.
On the other hand, this kind of centralization also means increased competition on this market. Moreover, the costs of computational power have been recently rather inflated due to super demand on the part of cryptocurrency miners. We tried to buy high-end off-the-shelf GPUs last summer and utterly failed: they were completely sold out for those who were getting into mining ethereum and litecoins. However, this trend is coming to an end too: mining is institutionalizing even faster, returns on mining decrease exponentially, and the computational resources are beginning to free up as it becomes less and less profitable to use them.
We at Neuromation are developing a platform to bring this computational power to AI researchers and practitioners. On our platform, you will be able to rent the endless GPUs that had been mining ETH, getting them cheaper than anywhere else but still making a profit for the miners. This effort will increase competition on the market (currently you go either to Amazon Web Services or Google Cloud, there are very few other solutions) and bring further democratization of various AI technologies.
AI Commoditization

By the way, speaking of democratization. Machine learning is a very community-driven area of research. It has unprecedented levels of sharing between researchers: it is common practice to accompany research papers with working open source code published on Github, and datasets, unless we are talking about sensitive data like medical records, are often provided for free as well.
For example, modern computer vision based on convolutional neural networks almost invariably uses a huge general purpose dataset called ImageNet; it has more than 14 million images hand-labeled into more than 20 thousand categories. Usually models are first pretrained on ImageNet, which lets them extract low-level features common for all photos of our world, and only then train it further (in machine learning, it is called fine-tuning) on your own data.
You can request access to ImageNet and download it for free, but what is even more important, the models already trained on ImageNet are commonly available for the general public (see, e.g., this repository). This means that you and I don’t have to go through a week or two of pretraining on a terabyte of images, we can jump right into it.
I expect this trend to continue and be taken further by AI researchers in the near future. Very soon, a lot of “basic components” will be publicly available, and an AI researcher will be able to work with and combine directly, without tedious fine-tuning. This will be partially a technical process of making what we (will) have easily accessible, but it will also require some new theoretical insights.
For example, a recent paper from DeepMind presented PathNet, a modular neural architecture able to combine completely different sub-networks and automatically choose and fine-tune a combination of these sub-networks most suitable for a given task. This is still a new direction, but I expect it to pick up.
Again, we at Neuromation plan to be on the cutting edge: in the future, we plan to provide modular components for building modern neural networks on our platform. Democratization and commoditization of AI research is what Neuromation platform is all about.
Sergey Nikolenko
Chief Research Officer, Neuromation