We’ve got great news: the very first paper with official Neuromation affiliation has appeared! This work, “3D Molecular Representations Based on the Wave Transform for Convolutional Neural Networks”, has recently appeared in a top biomedical journal, Molecular Pharmaceutics. This paper describes the work done by our friends and partners Insilico Medicine in close collaboration with Neuromation. We are starting to work together with Insilico on this and other exciting projects in the biomedical domain to both significantly accelerate drug discovery and improve the outcomes of clinical trials; by the way, I thank CEO of Insilico Medicine Alex Zhavoronkov and CEO of Insilico Taiwan Artur Kadurin for important additions to this post. Collaborations between top AI companies are becoming more and more common in the healthcare space. But wait — the American Chemical Society’s Molecular Pharmaceutics?! Doesn’t sound like a machine learning journal at all, does it? Read on…
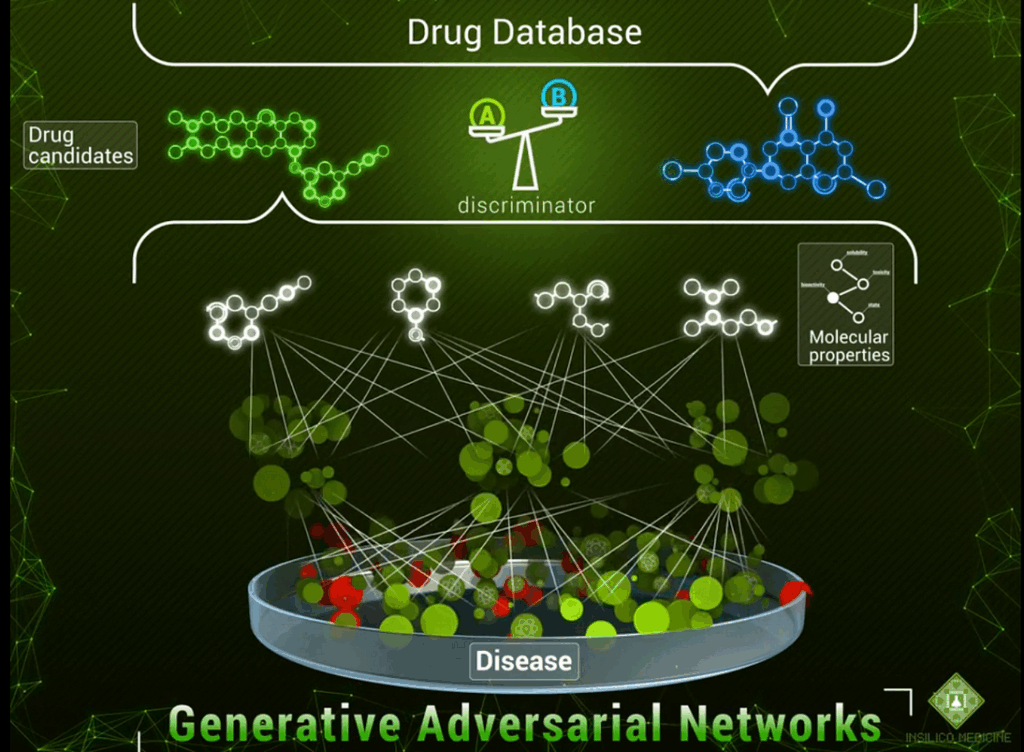
Lead Molecules: Educating the Guess
Getting a new drug to the market is a long and tedious process; it can take many years or even decades. There are all sorts of experiments, clinical studies, and clinical trials that you have to go through. And about 90% of all clinical trials in humans fail even after the molecules have been successfully tested in animals.
But to a first approximation, the process is as follows:
- the doctors study medical literature, in particular associations between drugs, diseases, and proteins published in other papers and clinical studies, and find out what the target for the drug should be, i.e., which protein it should bind with;
- after that, they can formulate what kind of properties they want from the drug: how soluble it should be, which specific structures it should have to bind with this protein, should it treat this or that kind of cancer…
- then they sit down and think about which molecules might have these properties; there is a lot to choose from on this stage: e.g., one standard database lists 72 million molecules, complete with their formulas, some properties and everything; unfortunately, it doesn’t always say whether a given molecule cures cancer, this we have to find out for ourselves;
- then their ideas, called lead molecules, or leads, are actually sent to the lab for experimental validation;
- if the lab says that the substance works, the whole clinical trial procedure can be initiated; it is still very long and tedious, and only a small percentage of drugs actually go all the way through the funnel and reach the market, but at least there is hope.
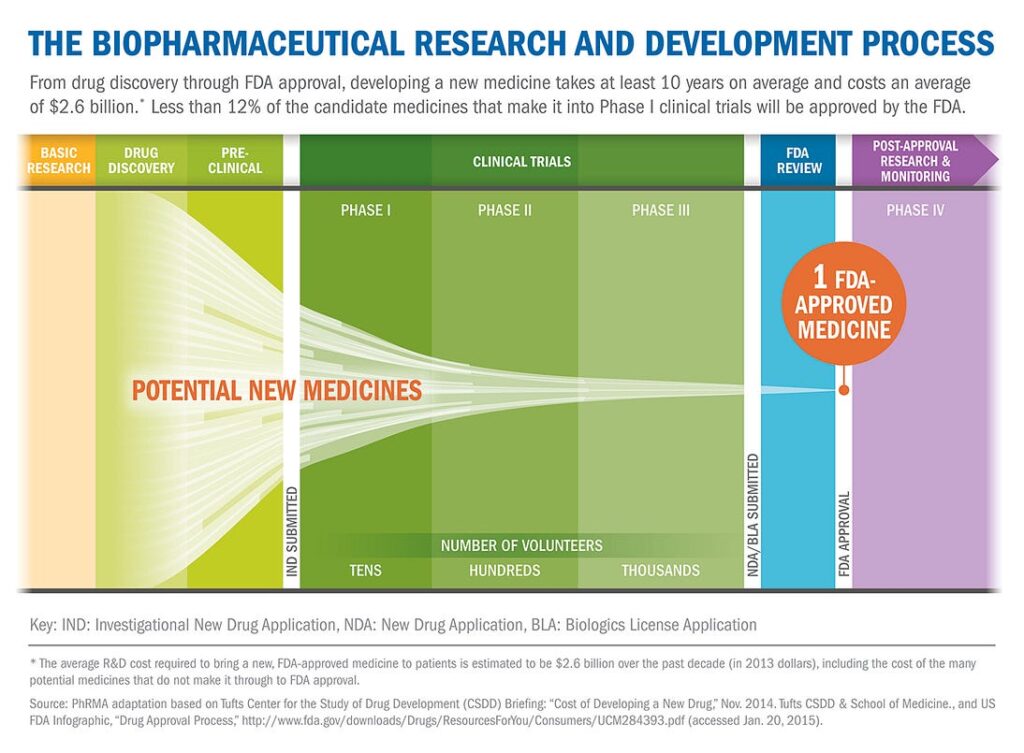
So where is the place of AI in this process? Naturally, we can’t hope to replace the lab or, God forbid, clinical trials: we wouldn’t want to sell a drug unless we are certain that it’s safe and confident that it is effective in a large number of patients. This certainty can only come from actual live experiments. In the future it is likely that we will be able to go from in silico (in a computer) to patients immediately with the AI-driven drug discovery pipelines but today we need to do the experiments.
Note, however, the initial stage of identifying the lead molecules. At this stage, we cannot be sure of anything, but live experiments in the lab are still very slow and expensive, so we would like to find lead molecules as accurately as we can. After all, even if the goal is to treat cancer there is no hope to check the entire endless variation of small molecules in the lab (“small” are molecules that can easily get through a cell membrane, which means basically everything smaller than a nucleic acid). 72 million is just the size of a specific database, the total number of small molecules is estimated to be between 10⁶⁰ and 10²⁰⁰, and synthesizing and testing a single new molecule in the lab may cost thousands or tens of thousands of dollars. Obviously, the early guessing stage is really, really important.
By now you can see how it might be beneficial to apply latest AI techniques to drug discovery. We can use machine learning models to try and choose the molecules that are most likely to have desired properties.
But when you have 72 million of something, “choosing” ceases to look like classification and gets more into the “generation” part of the spectrum. We have to basically generate a molecule from scratch, and not just some molecule, but a promising candidate for a drug. With modern generative models, we can stop searching for a needle in a haystack and design perfect needles instead:

How do we generate something from scratch? Deep learning does have a few answers when it comes to generative models; in this case, the answer turned out to be…
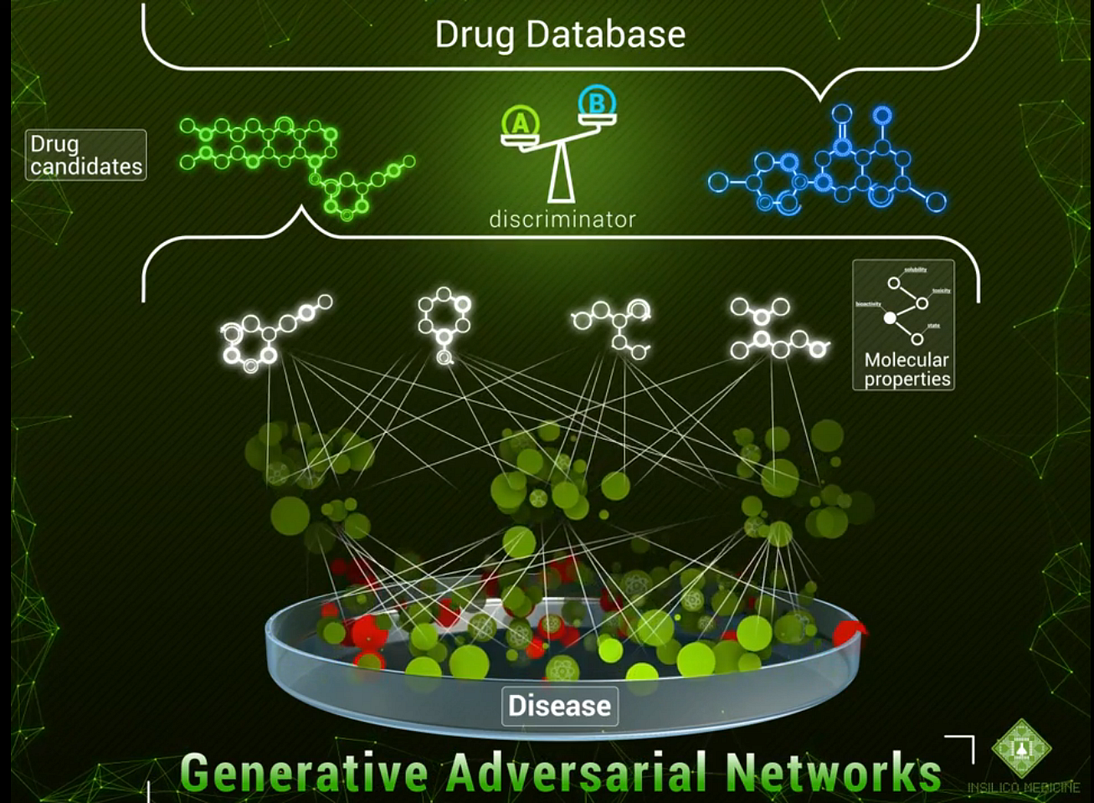
Generative Adversarial Networks
We have already briefly talked about generative adversarial networks (GANs) in a previous post, but I’m sure a reminder is in order here. GANs are a class of neural networks that aim to learn to generate objects from a certain class. Previously, GANs had been mostly used to generate images: human faces as in (Karras et al., 2017), photos of birds and flowers as in StackGAN, or, somewhat suprisingly, bedroom interiors, a very popular choice for GAN papers due to a commonly used part of the standard LSUN scene understanding dataset. Generation in GANs is based on a very interesting and rather commonsense idea. They have two parts that are in competition with each other:
- the objective of the generator is to generate new objects that are supposed to pass for “true” data points;
- while the discriminator has to decipher the tricks played by the generator and distinguish between real data points and the ones produced by the generator.
Here is how the general scheme looks:
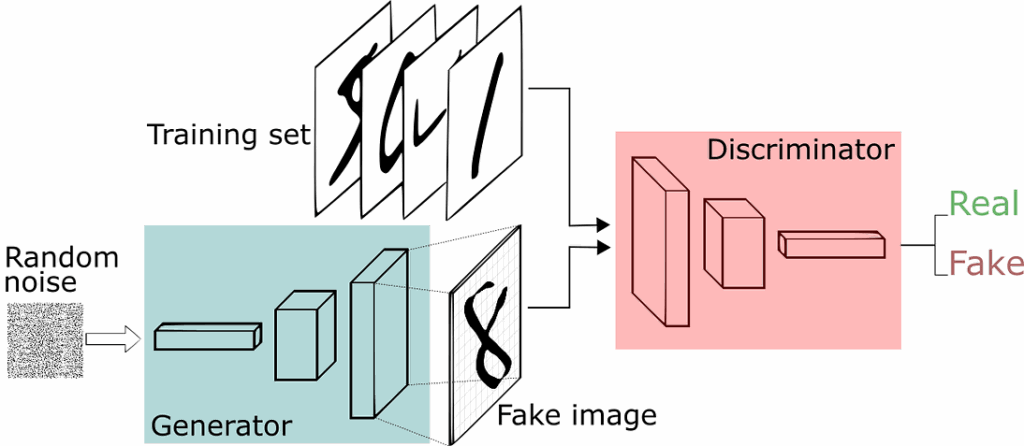
In other words, the discriminator learns to spot the generator’s counterfeit images, while the generator learns to fool the discriminator. I refer to, e.g., this post for a simple and fun introduction to GANs.
We at Neuromation are following GAN research with great interest due to many possible exciting applications. For example, conditional GANs have been used for image transformations with the explicit purpose of enhancing images; see, e.g., image de-raining recently implemented with GANs in this work. This ties in perfectly with our own ideas of using synthetic data for computer vision: with a proper conditional GAN for image enhancement, we might be able to improve synthetic (3D-rendered) images and make them more like real photos, especially in small details. In the post I referred to, we saw how NVIDIA researchers introduced a nice way to learn GANs progressively, from small images to large ones.
But wait. All of this so far makes a lot of sense for images. Maybe it also makes sense for some other relatively “continuous” kinds of data. But molecules? The atomic structure is totally not continuous, and GANs are notoriously hard to train for discrete structures. Still, GANs did prove to work for generating molecules as well. Let’s find out how.
Adversarial Autoencoders
Our recent paper on molecular representations is actually a part of a long line of research done by our good friends and partners, Insilico Medicine. It began with Insilico’s paper “The cornucopia of meaningful leads: Applying deep adversarial autoencoders for new molecule development in oncology”, whose lead author Artur Kadurin is a world-class expert on deep learning, one of Insilico Medicine’s Pharma.AI team on deep learning for molecular biology, recently appointed CEO of Insilico Taiwan… and my Ph.D. student.
In this work, Kadurin et al. presented an architecture for generating lead molecules based on a variation of the GAN idea called Adversarial Autoencoders (AAE). In AAE, the idea is to learn to generate objects from their latent representations. Generally speaking, autoencoders are neural architectures that take an object as input… and try to return the same object as output. Doesn’t sound too hard, but the idea is that in the middle of the architecture, the input must go through a middle layer that learns a latent representation, i.e., a set of features that succinctly encode the input in such a way that afterwards subsequent layers can decode the object back:
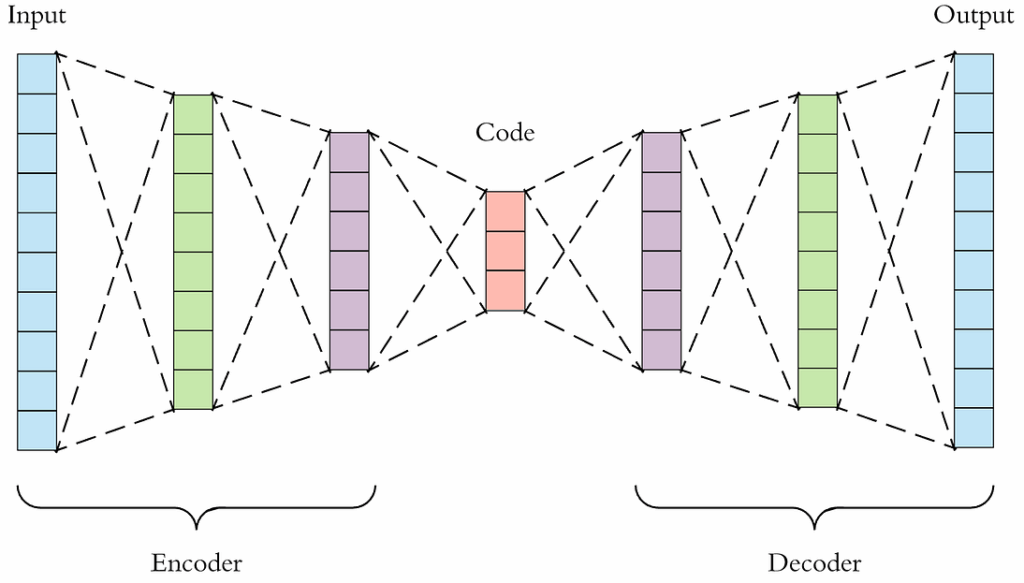
Either the middle layer is simply smaller (has lower dimension) than input and output, or the autoencoder uses special regularization techniques, but in any case it’s impossible to simply copy the input through all layers, and the autoencoder has to extract the really important stuff.
So what did Kadurin et al. do? They took a conditional adversarial autoencoder and trained it to generate fingerprints of molecules, using and serving desired properties as conditions. Here is the general model architecture from (Kadurin et al., 2017):
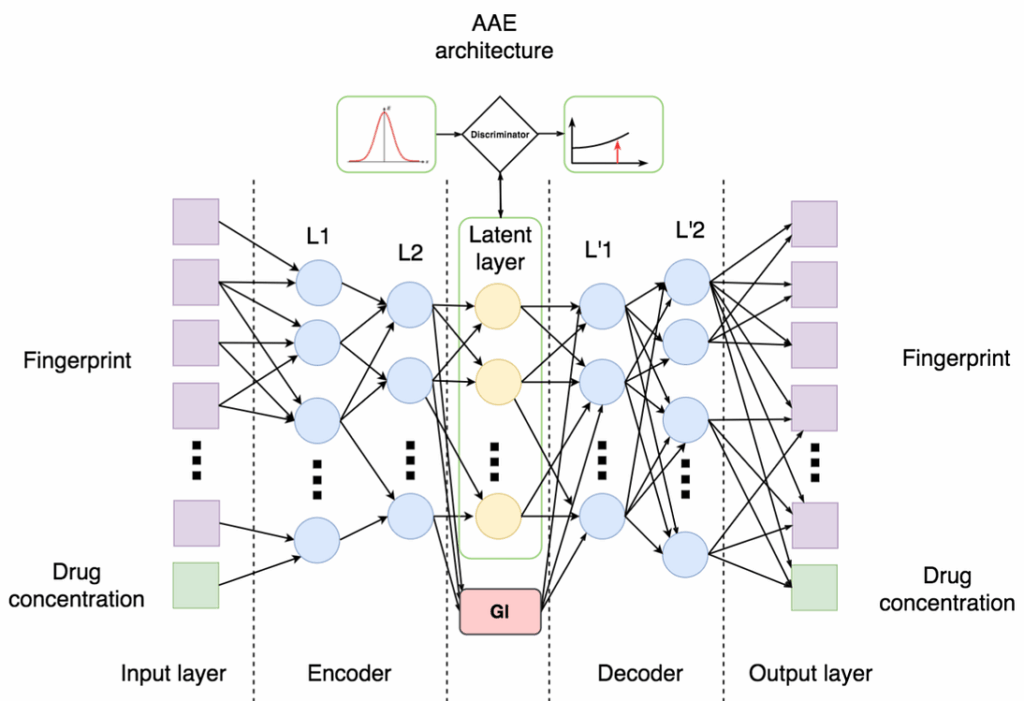
Looks just like the autoencoder above, but with two important additions in the middle:
- on top, there is a discriminator that tries to distinguish the distribution of latent representations from some standard distribution, e.g., a Gaussian; this is the main idea of AAE: if you can make the distribution of latent codes indistinguishable from some standard distribution, it means that you can then sample from this distribution and generate reasonable samples through the decoder;
- on the bottom, there is a condition that in this case encodes desired properties of the molecule; we train on the molecules with known properties, and the problem is then to generate molecules with desired (perhaps even never before seen) combinations of properties.
There is still that nagging question about the representations, though. How do we generate discrete structures like molecules? We will discuss molecular representations in much greater detail in the next post; here let me simply mention that this work used a standard representation of a molecule as a MACCS fingerprint, a set of binary characteristics of the molecule such as “how many oxygens is has” or “does it have a ring of size 4”.
Basically, the problem becomes to “translate” the condition, i.e., desired properties of a molecule, into more “low-level” properties of the molecular structure encoded into their MACCS fingerprints. Then a simple screening of the database can find molecules with the fingerprints most similar to generated ones.
At the time that was the first peer-reviewed paper showing that GANs can generate novel molecules. The submission was made in June 2016 and it was accepted in December 2016. In 2017 the community started to notice:
It turned out that the resulting molecules do look interesting…
Conclusion
This post is getting a bit long; let’s take it one step at a time. We will get to our recent paper in the next installment, and now let us summarize what we’ve seen so far.
Since the deep learning revolution, deep neural networks have been revolutionizing one field after another. In this post, we have seen how modern deep learning techniques are transforming molecular biology and drug discovery. Constructions such as adversarial autoencoders are designed to generate high-quality objects of various nature, and it’s not a huge wonder that such approaches work for molecular biology as well. I have no doubt that in the future, these or similar techniques will bring us closer to truly personalized medicine.
So what next? Insilico has already generated several very promising candidates for really useful drugs. Right now they are undergoing experimental validation in the lab. Who know, perhaps in the next few years we will see new drugs identified by deep learning models. Fingers crossed.
Sergey Nikolenko
Chief Research Officer, Neuromation