The list of accepted papers for ICLR 2019 (International Conference on Learning Representations) is already available online, and there are a number of very interesting papers there waiting to be reviewed. So, with the next several posts I thought we could dive into the best of them and discuss some related and very relevant areas.
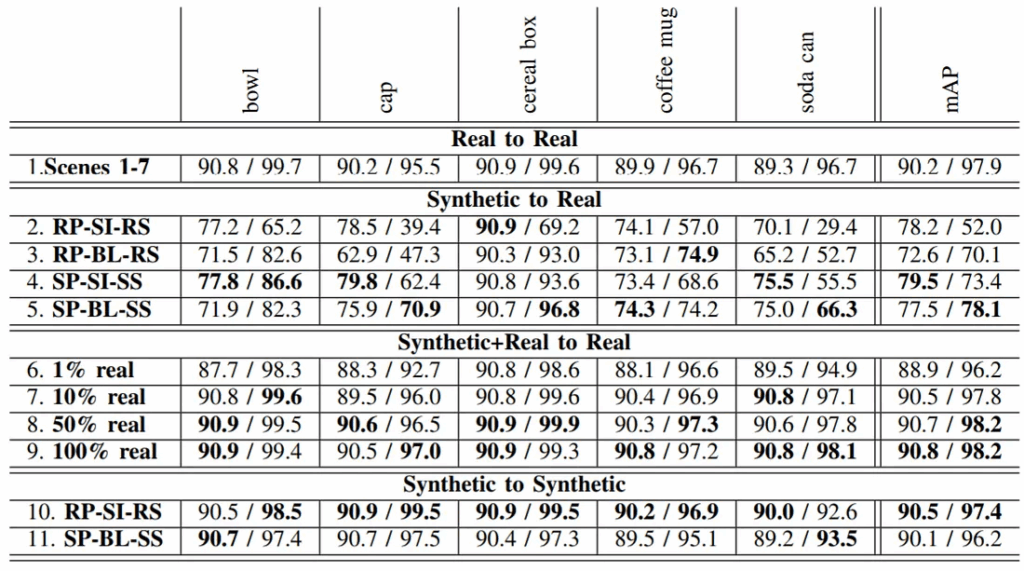
First off, the work of the renowned AI researcher Dmitry Vetrov. Dmitry has always been, so to speak, a “big brother” in AI for me. I remember how we first met: back in 2009, we made at least two laps around the Moscow State University campus (quite a walk!), talking about machine learning, deep learning, and the future of AI. Or, better to say, Dmitry was talking and I was listening. By now, Dmitry Vetrov is a laboratory leader at the Samsung AI Center Moscow, a research professor and laboratory head at the Higher School of Economics in Moscow, founder and head of the Bayesian Methods Research Group, one of the strongest ML research groups in Russia, and generally one of the most famous ML researchers in Russia. He has always advocated bringing Bayesian methods to deep learning, and many of his works are devoted to exactly this.

ICLR 2019 has become a very successful conference for Dmitry: he (naturally, not alone but with the researchers and students of his labs) has co-authored three papers accepted to ICLR! This is an outstanding achievement, so I decided to take the first NeuroNugget of the “ICLR in Review” series to say thank you to Dmitry Vetrov for all the advice, guidance, and, most importantly, simply a good example he has been setting for all of us through the years. Thank you Dima, and let’s review your latest and greatest!
I shall be telling this with a sigh
Somewhere ages and ages hence:
Two roads diverged in a wood, and I —
I took the one less traveled by,
And that has made all the difference.Robert Frost
Variance Networks: Unexpectedly, Expectation Is Not Required
The paper “Variance Networks: When Expectation Does Not Meet Your Expectations” by Kirill Neklyudov, Dmitry Molchanov, Arsenii Ashukha, and Dmitry Vetrov presents a very surprising construction. So surprising that we need to begin with a little context.
All of our readers probably know that randomization plays a central role in the training of modern neural networks. There is no way (and no need) to try to replace stochastic gradient descent with a regular one when using randomized mini-batches is orders of magnitude more efficient. Random initialization of the network weights has entirely replaced the unsupervised pre-training methods that jumpstarted the deep learning revolution back in 2006–2007, and new improvements in random initialization methods keep popping up (for example, Xavier initialization for symmetric activation functions, He initialization for ReLU, Le-Jaitly-Hinton for recurrent networks of ReLUs, and many more).
What is a bit less commonly known is that not only is the training randomized, but the networks themselves often are too, as in stochastic neural network constructions where the weights of the network are randomized not just during initialization but throughout training and even during inference as well.
Can you name the most common example of such a construction?..
…[I’ll just give you a little bit of space to think]…
…that’s right, dropout!
A dropout layer makes any network into a stochastic one. Each weight with value w is accessed through a probability distribution, albeit a very simple one. With probability p it’s w, and with probability (1-p) it’s 0. Dropout is very common, so now you see that stochastic neural networks are actually all over the place.
Dropout also showcases another important trick done with stochastic neural networks: weight scaling. In order to do inference with (that is, apply) a stochastic neural network, it might look like you need to run it several times and then average the results, getting an estimate for the resulting expectation which is usually intractable in any other way; this is known as test-time averaging.
But running a network 20 times to get a single answer is not too fast either! Weight scaling is the technique of approximating this process by replacing each weight with its expected value. In the case of dropout, this means that instead of running the network many times for every test example, we replace each weight w subject to dropout with its expected value pw.
Weight scaling is not really formally correct, but is used very widely. As Neklyudov et al. emphasize, its “success… implies that a lot of learned information is concentrated in the expected value of the weights”. But the main point of their paper is to introduce the so-called variance layers: stochastic layers where the expected values carry exactly zero information because the expectations are always set to zero, and only variances of the weights are trained!
This counterintuitive construction proves to be an interesting one. It turns out that variance layers can and do train and encode interesting features. Here is an illustration for a toy problem:
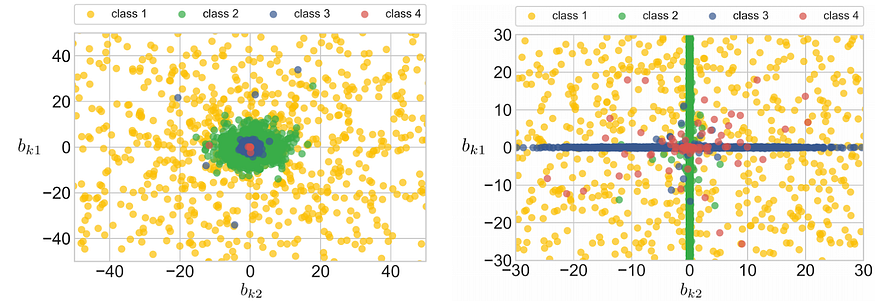
The two pictures above show two different ways that neurons at a variance layer can interact. On the left, the two neurons encode the four classes together, in almost exactly the same way: class 4 is encoded by the lowest variance (the red core at the origin), class 3 has higher variance, and so on. By using two neurons in the same way, the network can have a whole “sample” of the same underlying distribution, which makes for a more reliable estimate of the variance.
On the right, the two neurons decided to learn complementary things: the first neuron (Y-axis) has high variance for classes 1 and 2, and the second neuron (X-axis) has high variance for classes 1 and 3.
Neklyudov et al. show that variance networks can perform well on standard tasks, they prove to be more robust against adversarial attacks and can improve exploration in reinforcement learning. But most importantly, it turns out that expectations of the weights are not as crucial as people thought. This is a fascinating proof of concept. Who knows, maybe this will lead to a completely new genre of deep learning; we’ll have to wait and see.
The Deep Weight Prior
The second paper co-authored by Dmitry Vetrov at ICLR 2019 is “The Deep Weight Prior” by Andrei Atanov, Arsenii Ashukha, Kirill Struminsky, Dmitry Vetrov, and Max Welling, considers another key element of the Bayesian framework: prior distributions.
Let’s begin with the main formula of all machine learning — Bayes’ rule:
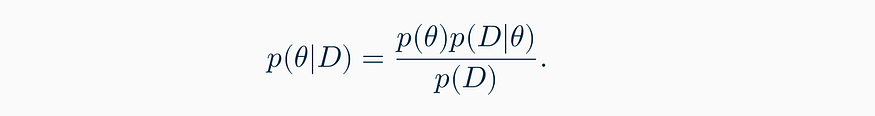
In machine learning, θ usually represents the model parameters, and D represents the data. The formula shows how we change our beliefs about the parameters θ after getting experimental results D: we update our prior belief p(θ) by essentially multiplying it by the likelihood p(D|θ). Recalculating p(θ) into p(D|θ) is the essence of Bayesian inference, and the essence of many machine learning problems and techniques.
But if this is the core of all machine learning, why don’t we hear more about prior distributions in deep learning? The simple answer is that nobody knows how to make nontrivial priors for complex neural networks. Naturally, an L2 regularizer can be thought of as a zero-mean Gaussian prior… but what if we are looking for something more meaningful?
Atanov et al. propose a novel and interesting way to tackle this problem. Specifically, they consider the case of convolutional neural networks, where:
- it is very plausible that convolutional layers, especially early ones, learn nearly the same features on all datasets from an entire domain — after all, most modern computer vision networks start out by pretraining on ImageNet even if their goal is not to recognize its classes;
- on the other hand, it makes little sense to assume that the prior distribution can decompose into a product over individual weights since the weight matrix of a convolution should represent a single object for this distribution.
Based on these remarks, Atanov et al. rightly assume that they can learn the prior distribution for a convolutional network on other datasets from the same domain (e.g., on smaller datasets of real photographs or handwritten digits), and that this prior distribution, while it factorizes over the layers and channels, will not factorize over the spatial dimensions of the filters, i.e., it will be a distribution over the weight matrices of convolutional filters.
So, how do you train a distribution like that? That’s where variational autoencoders (VAE) come in. We have already discussed VAEs in a previous post. Essentially, they learn a transformation from input x and some random bits with a fixed distribution to a distribution on the latent embeddings q(z|x) that should approximate p(z|x), by learning to output the parameters of q(z|x) (reparametrization trick), and then this distribution on the latent space z can be used through the decoder to make more samples from p(x):
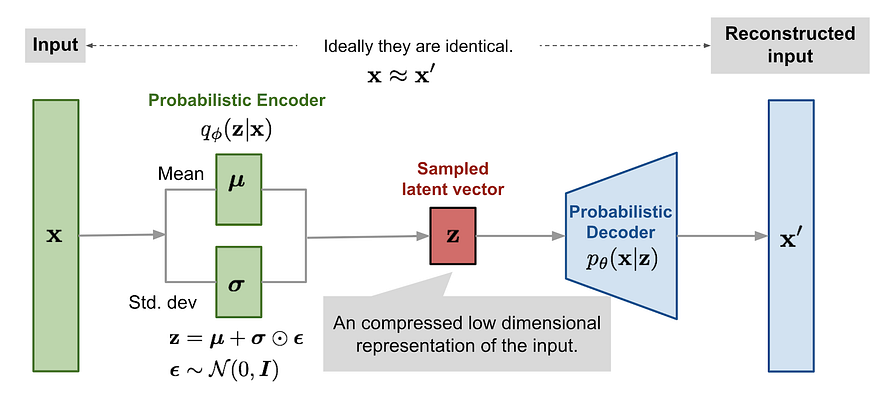
So what do Atanov et al. do? They opt to take some (smaller and simpler) datasets and train a number of convolutional nets (“source networks”) to get a dataset of convolutions. Then they train a VAE on this dataset to produce the prior distribution on the convolutional kernels! This VAE is now a model that can sample from the distribution of convolutional kernels and that defines the deep weight prior:
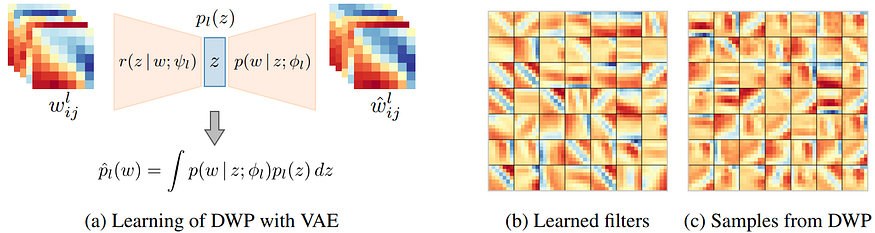
Then they show that variational inference on the convolutional weights with the deep weight prior works much better than with any other previously known kind of prior. But, again, the most important point here is not a specific experimental result but the idea that it can open up wonderful new possibilities for, among other things, transfer learning and domain adaptation.
Variational Autoencoder with Arbitrary Conditioning
And speaking of variational autoencoders… In the third ICLR paper by Vetrov’s group, “Variational Autoencoder with Arbitrary Conditioning”, Oleg Ivanov, Michael Figurnov, and Dmitry Vetrov introduce a very interesting extension for the VAE framework.
Once you have a generative model (of any kind) and can sample objects from a distribution, the natural next step is to try to construct a conditional version of the same model. This will let you create objects that are subject to some kind of condition; e.g., generate the face of a person with a given age and gender, or with a smile and sunglasses. Traditional conditional VAEs are well-known, of course; to add a label to the VAE construction, you can simply input it to both encoder and decoder, like this:
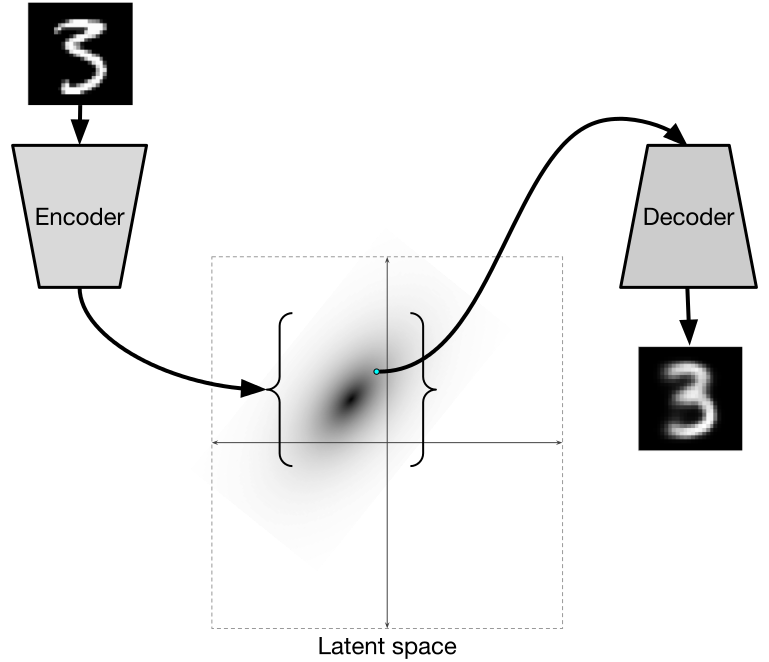
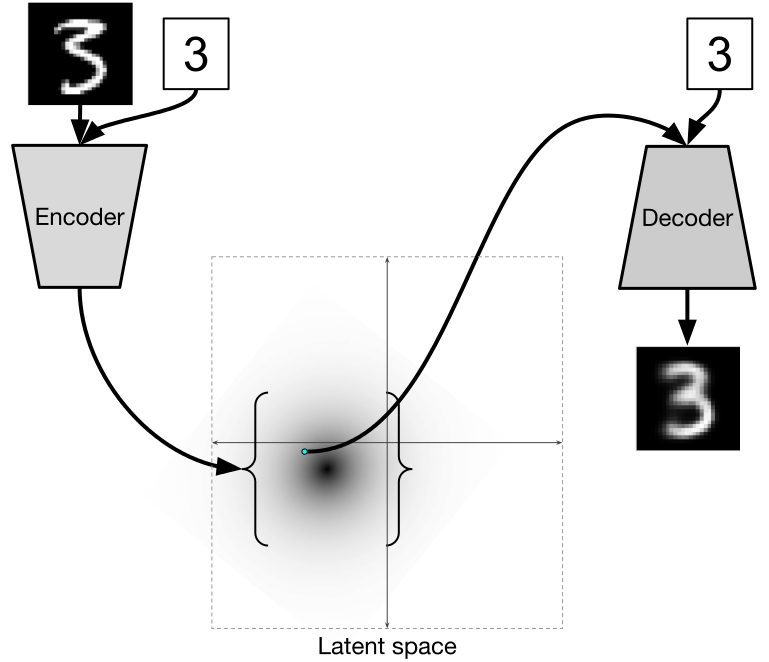
Now the model is free to learn completely different distributions in the latent space for different labels, and this produces all sorts of wonderful effects, has implications for style transfer, and so on.
In this paper, Ivanov et al. take conditioning up to eleven: they consider a situation where any subset of the input might be unknown and subject to generation conditioned on the available part. That is:
- along with the input x, we are given a binary mask b that shows which components (pixels) of x are known (where bi=0) and which are not (where bi=1);
- the goal is to construct a model for the conditional distribution p(xb|x1-b,b);
- as part of the problem setting, we are also given a prior distribution on the masks p(b) that shows which masks are more likely to appear and which, therefore, the model should concentrate on.
To solve this problem, Ivanov et al. propose a model they call Variational Autoencoder with Arbitrary Conditioning (VAEAC). A full consideration of VAEAC, its training and inference goes, alas, far beyond the scope of a NeuroNugget. But I do want to note the uses of the resulting model. The arbitrary conditioning setting is designed for problems such as:
- missing features imputation, i.e., reconstructing missing features in a dataset; in the wild, many datasets are rather dirty, but we cannot afford to simply discard all the incomplete data;
- image inpainting, i.e., reconstructing a hidden part of an image; this is an important problem for image manipulation, e.g., if you want to delete a random passerby from your photo, you can segment the person and cut them out with a segmentation model, but then you still need to inpaint the background in a natural way in place of the person.
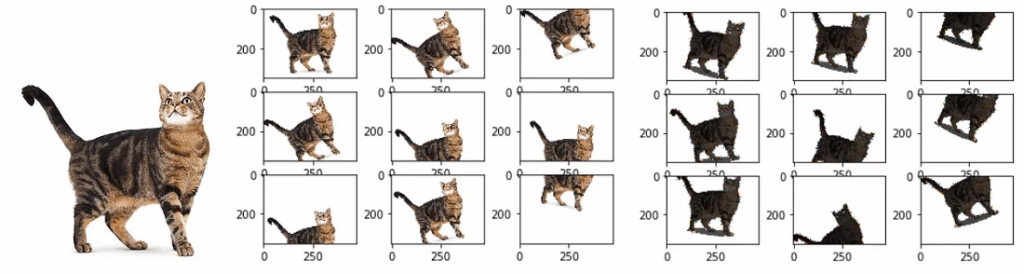
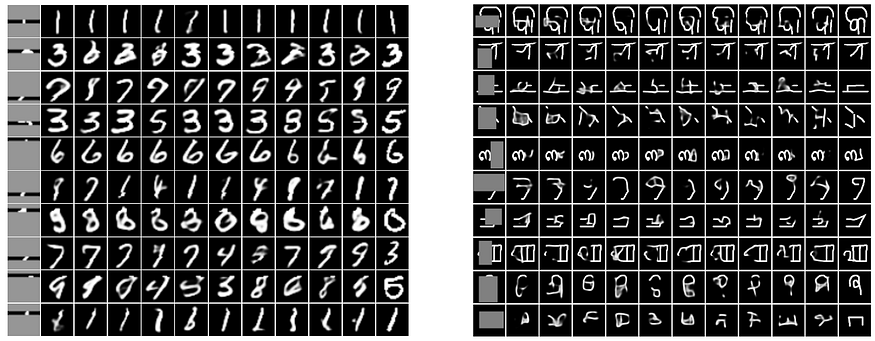
VAEAC solves both of these problems nicely. It especially shines on imputation, but that use-case is not flashy enough, so here are some inpainting results. The rightmost columns in the following images show the ground truth. Top to bottom: MNIST and Omniglot, CelebA, and CelebA with more interesting masks:


Stochastic Weight Averaging: A Simple Trick to Rule Your Networks
But wait, there is more! This is not an ICLR paper yet, but it’s a very recent work from Dmitry’s lab that might prove applicable to nearly everyone in the world of deep learning. In “Averaging Weights Leads to Wider Optima and Better Generalization”, Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson present a simple idea that can be embedded into many networks at virtually no cost… but quite possibly with a hefty profit!
It is common knowledge in machine learning that putting together a number of different models, in a procedure known as ensembling, helps improve performance. However, in deep learning ensembling is hard: training even one model is difficult, and getting a hundred meaningful networks together would be quite a computational feat.
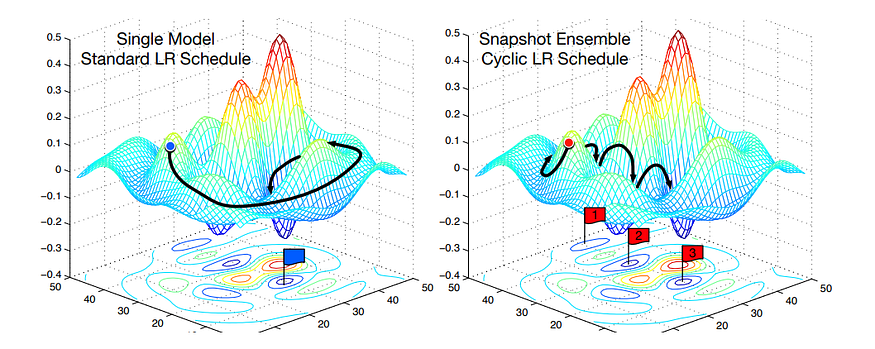
There have been some works on ensembling in deep learning, though. Inspired by the ideas of cyclical learning rates, Huang et al. in “Snapshot Ensembles: Train 1, get M for free” (2017) train a single neural network, but along the optimization path make sure to converge to several local minima and save the weights. Then they average these weights, getting basically an ensemble of multiple local minima from a single training pass. Like this:
The next step came in an earlier paper from Vetrov’s lab. In “Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs”, Garipov et al. showed that for a wide range of architectures, their local optima are actually connected by rather simple curves along which the loss remains near-constant! Here is an illustration:
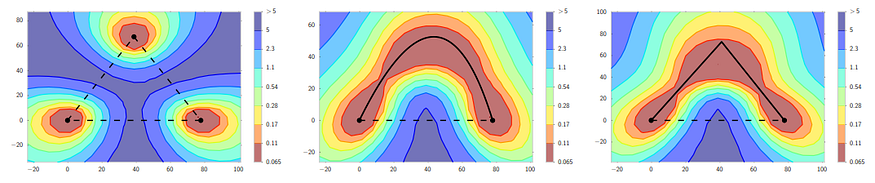
Garipov et al. show that if you train three different networks you’ll get a landscape like the one shown on the left, as you would expect. But if you then use their proposed mode connecting procedure, you can find curves of near-constant loss function that connect the dots. On the plots, the X-axis is always the same but Y-axes are different, and the procedure invariably finds a valley that connects the two optima.
Based on this observation, Garipov et al. proposed a new ensembling procedure, Fast Geometric Ensembling (FGE), which basically amounts to averaging the weights along such a mode connecting path.
Still, this was rather computationally intensive: you had to find several local optima, then connect them with a separate computational procedure. And, ultimately, it’s still an ensemble: you need to keep multiple models, run them all at inference time, and then average their answers. Stochastic Weight Averaging (SWA), proposed by Izmailov et al. in the paper in question, does away with most of these extra costs!
This time, the fundamental observation is that stochastic gradient descent with cyclical and constant learning rates actually traverses the regions in the weight space corresponding to high-performing networks, but it does not reach the central points of these regions. That is, three networks averaged out by FGE would most likely look something like this:
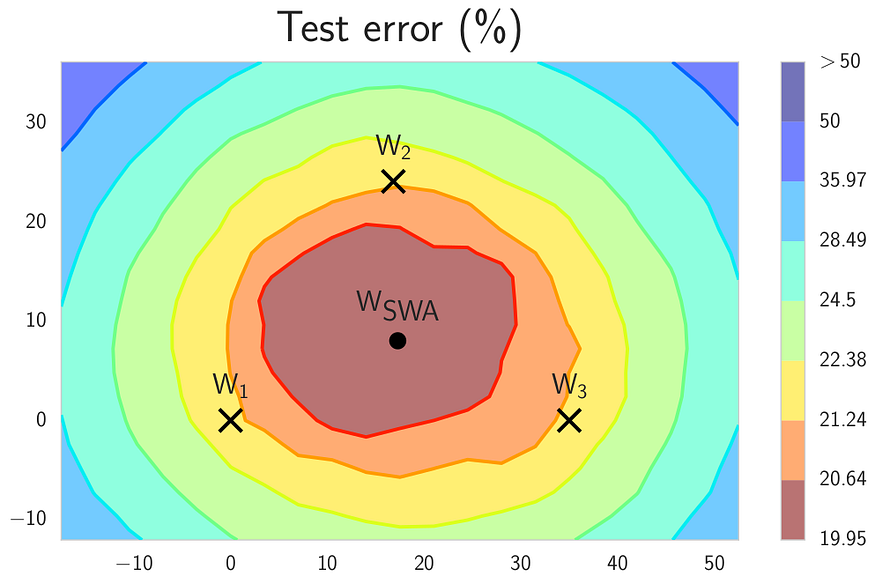
So instead of averaging their predictions, why not average the weights directly, getting to the wonderful wSWA point shown above?! That’s exactly what stochastic weight averaging does:
- start with a (somewhat) pretrained model;
- keep training with a cyclical or constant learning rate schedule;
- on every iteration of training, add the current vector to a separately accumulating running average.
And that’s it! The results are nothing short of amazing: with no additional cost at inference time and very little cost at training time, SWA actually manages to improve virtually all architectures across a wide variety of datasets and settings. Here is a sample of experimental results:
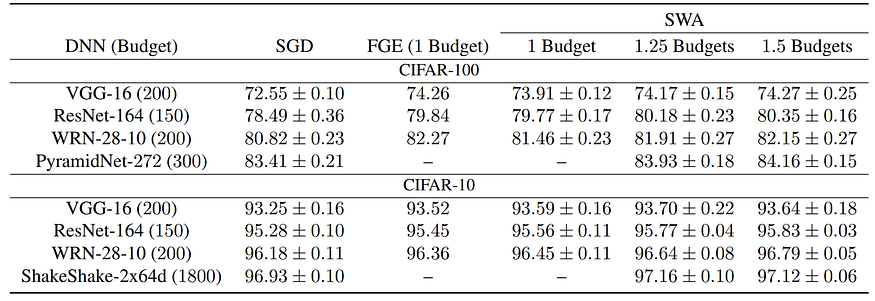
SWA is a straightforward drop-in replacement for stochastic gradient descent, and, naturally, it has an official github repository released by the authors. Try it out and share your results in the comments!
Conclusion
This has been a rather challenging NeuroNugget, I’m afraid, and we have only skimmed the surface of several latest papers by Dmitry Vetrov and his group.
I have tried to outline the main ideas that each paper brings to deep learning, but the most important thing I want to emphasize is the common thread: each paper we have considered today presents a novel idea that looks plausible, works well (at least on toy examples, sometimes more experiments are needed before it can be used in large-scale networks), and opens up a whole new direction of study, usually somewhere near the field of Bayesian deep learning.
That’s how Dmitry Vetrov has always done research: he has a vision and a knack for finding these “paths less traveled” in the forest of deep learning, a forest that by now might seem rather well-trodden. Still, he did it in 2009, he is doing it in 2019, and I’m sure he will still be finding completely novel ideas and uncovering new directions in 2049. Thank you Dmitry — and good luck!
Sergey Nikolenko
Chief Research Officer, Neuromation