Введение
Итак, 2025 год закончился, и я наконец-то собрался с духом написать большой обзор того, что произошло в мире искусственного интеллекта за этот год. Обзор получается большим, так что я решил разбить его на части — и сегодня начну с самого очевидного: больших языковых моделей и агентов на их основе.
Честно говоря, каждый из последних лет можно было бы назвать прорывным для AI. Но конкретные направления прорывов всё-таки меняются. Если 2023-й был годом ChatGPT и массового осознания того, что языковые модели — это серьёзно, а 2024-й — годом мультимодальности и первых робких шагов к рассуждениям, то 2025-й я бы однозначно назвал годом рассуждающих моделей. И это не просто маркетинговое слово — здесь действительно произошёл качественный скачок.
Давайте разбираться, что же случилось.
Большие рассуждающие модели
Если выбирать одну главную идею, определившую 2025 год, это безусловно large reasoning models — модели, которые умеют “взять паузу” и подумать перед тем, как ответить. OpenAI запустили этот тренд в конце 2024-го с серией o1, а затем началась гонка, кто первый сможет повторить результат OpenAI. Эту гонку выиграл китайский стартап DeepSeek со своей моделью R1 (DeepSeek-AI, январь 2025).
Сами модели
OpenAI был первым, DeepSeek — вторым, а дальше понеслось. Практически каждая крупная лаборатория выкатила свои рассуждающие модели, и за год успело смениться несколько поколений. Отмечу только самые последние:
- Google запустил Gemini 3 Pro и Deep Think в ноябре 2025-го — это была первая модель, которая пробила барьер в 1500 Elo на LMArena (да, рейтинги постоянно меняются, но факт остаётся фактом);
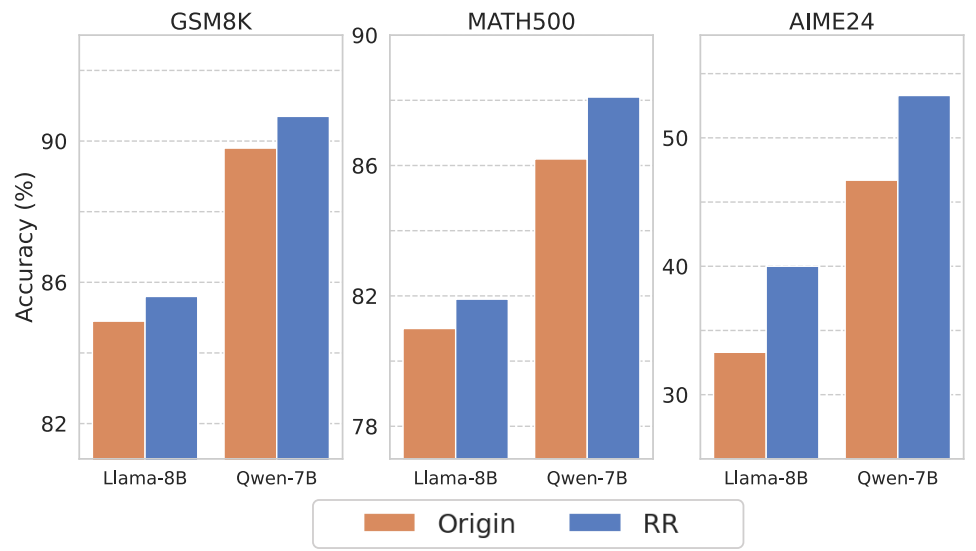
- Anthropic выпустил Claude 4.5 в трёх вариантах (Haiku, Sonnet, Opus) с сентября по ноябрь; Sonnet достиг 77.2% на SWE-bench Verified, что стало лучшим результатом для реальных программистских задач, и Claude 4.5 стал основой для Claude Code, о котором мы поговорим ниже;
- OpenAI ответил в декабре моделью GPT-5.2 в трёх вариантах: Instant для быстрых ответов, Thinking для глубоких рассуждений и Pro для максимальной точности;
- китайские лаборатории отстают, но не сильно: DeepSeek-V3.2 интегрировал рассуждения в работу с инструментами (tool use), а Qwen3-235B от Alibaba стал одной из лучших открытых MoE-моделей с 235 миллиардами параметров (22 миллиарда активных);
- Meta выпустила Llama 4 с вариантами Scout и Maverick, а xAI с Grok-4.1 вышла в топ reasoning-лидербордов, хотя здесь я, признаться, куда более скептично настроен.
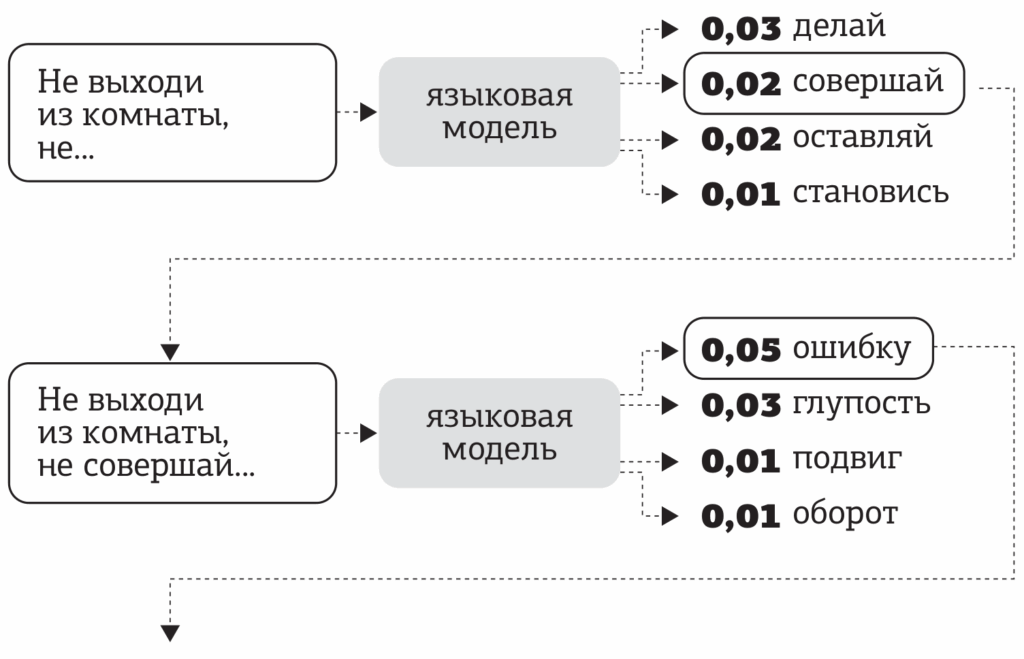
Что объединяет все эти модели? У них есть режим chain-of-thought, при котором модели выдают секретный “блокнотик” (scratchpad, так и называется), куда можно писать токены, которые будут использоваться только для рассуждений и потом не станут частью собственно ответа для пользователя.
Такой подход идеально укладывается в схему обучения с подкреплением: теперь у модели есть “промежуточные ходы” (токены рассуждения), за которые она не получает награду, а собственно сигнал приходит только с “результатом партии” (окончательным ответом модели):

Оказалось, что эта простая идея действительно способна сделать модели существенно “умнее” (пока в кавычках, но скорее по привычке, честно говоря).
Обычно это буквально слайдер, регулирующий, сколько можно подумать перед ответом. GPT-5.2, например, сам может решить, нужно ли запускать chain-of-thought и сколько токенов на это потратить. На простых задачах ответ приходит за секунды, на сложных — модель может думать десятки секунд, а то и минут, но зато выдаёт более точный результат.
Как это работает: RLVR
За большинством рассуждающих моделей стоит техника под названием reinforcement learning with verifiable rewards (RLVR, обучение с подкреплением с верифицируемыми наградами). Это буквально указанная выше схема; разница только в том, что если ваша задача подходит для RLVR, это значит, что награду вы можете вычислить автоматически (например, проверить ответ на математическую задачу), а не полагаться на экстраполяцию человеческих предпочтений, как в RLHF:
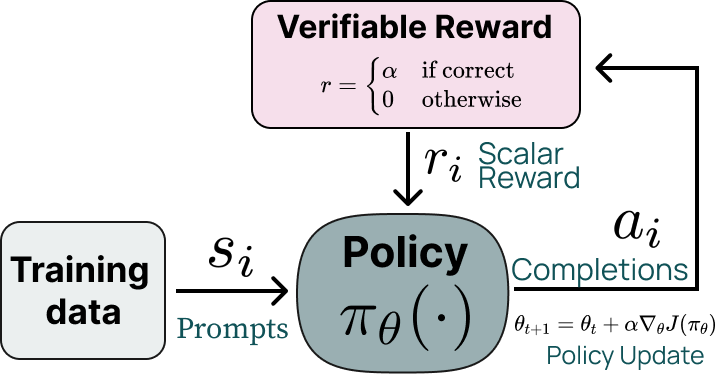
Эту ключевую идею хорошо объяснил, например, Андрей Карпатый в своём обзоре «2025 LLM Year in Review»: если обучать LLM на задачах с автоматически проверяемыми ответами (математика, код, головоломки), модели спонтанно развивают стратегии, которые выглядят как рассуждения.
Они учатся разбивать задачу на промежуточные шаги, проверять себя, возвращаться и пробовать по-другому. Никто не задаёт это явно в структуре модели или обучающей выборки — это emergent behaviour, поведение, возникающее само собой. И оказалось, что RLVR даёт отличное соотношение прироста результатов на потраченный доллар. Карпатый отмечает, что это, возможно, главный тренд 2025-го: вместо того чтобы тратить весь вычислительный бюджет на pretraining, его стали эффективнее использовать для обучения рассуждениям.
Рассуждения естественным образом приводят к идее test-time compute scaling: если дать модели больше “времени на подумать”, результаты улучшаются. Раньше в машинном обучении было мало примеров, когда можно эффективно обменять вычисления во время применения модели (inference) на качество результата. Теперь это умеет каждая frontier LLM.
Но об этом — чуть позже, в отдельном разделе. Сначала давайте посмотрим на самые впечатляющие результаты.
Математика и программирование: золотые медали
RLVR особенно хорошо работает в областях, где решения можно проверить автоматически. И здесь 2025-й принёс просто фантастические результаты.
Международная математическая олимпиада
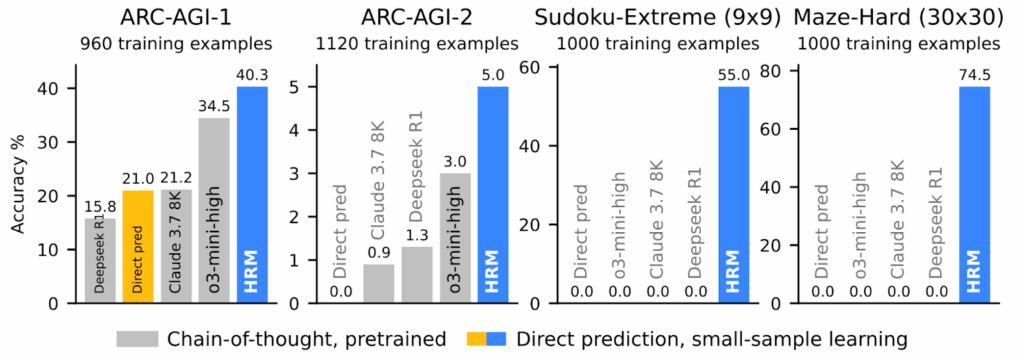
IMO стала де-факто бенчмарком для математических способностей AI. В 2025-м и Google DeepMind, и OpenAI достигли уровня золотой медали, набрав 35 из 42 баллов. Об этом я уже рассказывал в двух постах: “Секретная модель OpenAI берёт золото IMO 2025: Proof or Bluff?” и “Deep Think и IMO 2025: сложные отношения OpenAI и математики“, так что повторяться не буду.
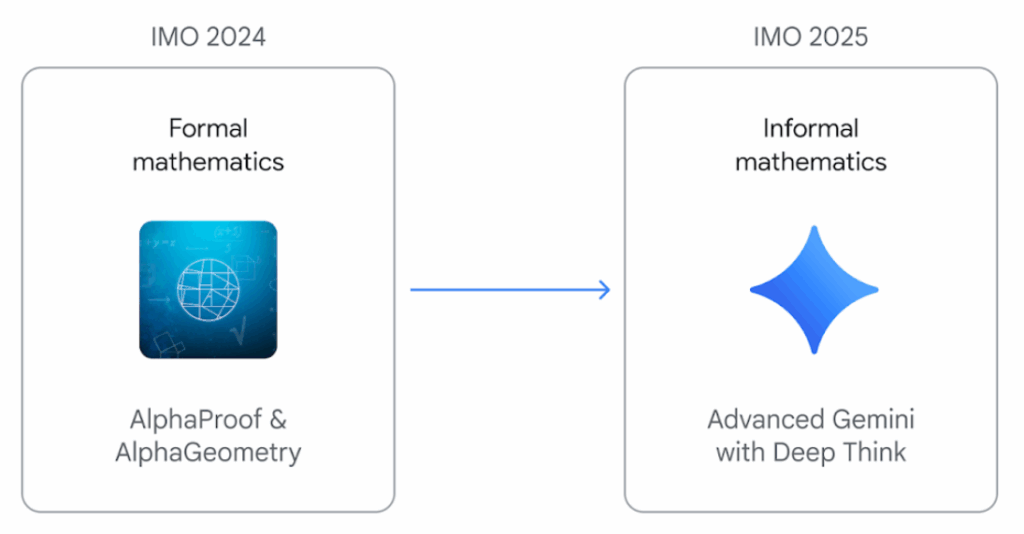
Отмечу только, что подход Google с Gemini Deep Think особенно интересен. В отличие от прошлогодних AlphaProof и AlphaGeometry, которые требовали перевода задач в формальные языки вроде Lean, Deep Think работает end-to-end на естественном языке. Он читает условие задачи и выдаёт строгое математическое доказательство напрямую. Ключевая инновация — параллельное обдумывание (parallel thinking): модель одновременно исследует несколько стратегий решения и комбинирует их, вместо того чтобы идти по одной линейной цепочке рассуждений.
OpenAI достигли такого же результата с минимальной IMO-специфичной подготовкой — по их словам, это в основном general-purpose RL и test-time compute scaling.
А главной новостью конца года в этом направлении стало то, что DeepSeek выложил в открытый доступ DeepSeek-Math-V2 — первую открытую модель уровня золотой медали IMO (Shao et al., ноябрь 2025). Она решила 5 из 6 задач IMO 2025 (как и модели OpenAI и Google) и набрала почти идеальные 118/120 на Putnam 2024, превзойдя лучший человеческий результат в 90 баллов.
Инновация DeepSeek — self-verification framework: специальный верификатор оценивает строгость и полноту доказательств, которые порождает proof generator, имитируя процесс самопроверки у математиков-людей. Результаты растут с числом итераций самопроверки:

Олимпиады по программированию
Революция затронула и соревновательное программирование. В сентябре и OpenAI, и Google показали сильные результаты на International Collegiate Programming Contest (ICPC) — на новых, ранее не публиковавшихся задачах. Об олимпиадах по программированию я рассказывал в посте “ICPC, IMC и Максим Туревский“; про результаты AI-моделей там, правда, почти ничего не было, ну да и ладно.
DeepSeek-V3.2 собрал целую коллекцию, особенно впечатляющую, учитывая, что это открытая модель:
- IMO 2025: золотая медаль (35/42),
- IOI 2025: золотая медаль (492/600, 10-е место),
- ICPC World Finals: второе место (10/12 задач),
- CMO 2025: золотая медаль.
Можно, конечно, сказать, что это показывает, как open-source модели способны реально конкурировать с проприетарными в специализированных задачах… Но, если честно, это всё-таки соревнования, то есть бенчмарки с придуманными людьми задачами и известными решениями. А что насчёт “настоящей” математики — доказательства новых теорем? Об этом мы поговорим в следующих частях обзора, а пока вернёмся к LLM.
Reasoning + Tools = Agents
Настоящая сила рассуждающих моделей проявляется, когда их соединяют с инструментами (tools). Если модель умеет вызывать API, запускать код, искать в интернете — она превращается в автономного агента, который разбивает задачу на подзадачи, выполняет их и итерируется до результата.
Model Context Protocol
Model Context Protocol (MCP), который Anthropic выпустил в ноябре 2024-го, в 2025-м получил массовое принятие индустрией. OpenAI присоединился в марте, Microsoft и GitHub вошли в steering committee в мае, а в декабре протокол был передан в Linux Foundation’s Agentic AI Foundation (совместно основанный Anthropic, Block и OpenAI при поддержке Google, Microsoft, AWS и других).
К концу года у MCP было уже под сто миллионов загрузок SDK в месяц, тысячи серверов и 75+ коннекторов в одном только Claude. Иллюстрацию ниже я взял из поста подкаста Latent Space, авторы которого гордились тем, как предсказали успех MCP ещё в марте:
MCP даёт стандарт того, как AI-агенты взаимодействуют с внешними инструментами, превращая их из моделей, которые умеют только работать с текстом, в полноценных ассистентов, способных сделать практически всё, что можно сделать за компьютером.
Computer use
Кстати, о компьютерах. Возможности работы ведущих моделей с компьютером (то есть их способность управлять вашим десктопом за вас, выполняя при этом полезную работу) выросли за прошедший год очень сильно. Результаты Claude на OSWorld (бенчмарк для автоматизации десктопа) выросли с 14.9% до 61.4% за год — это уже близко к человеческому уровню, составляющему 70-75%.
OpenAI Operator, запущенный в январе 2025-го как research preview и интегрированный в ChatGPT к июлю, уже сотрудничает с DoorDash, Instacart, Uber и другими сервисами для выполнения реальных задач.
Coding agents
Но, пожалуй, самое важное применение для LLM-агентов пока — это программирование. Здесь понятно, куда масштабироваться, и относительно легко проверять результаты.
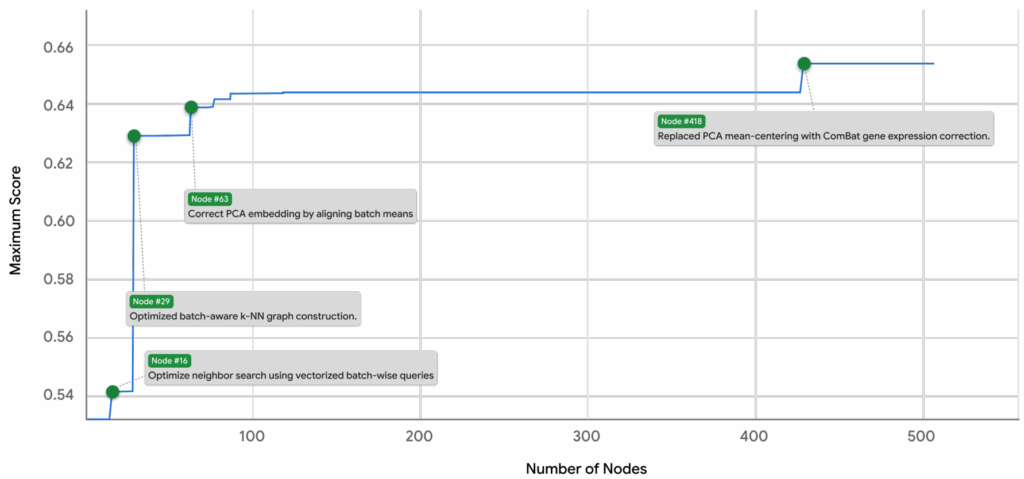
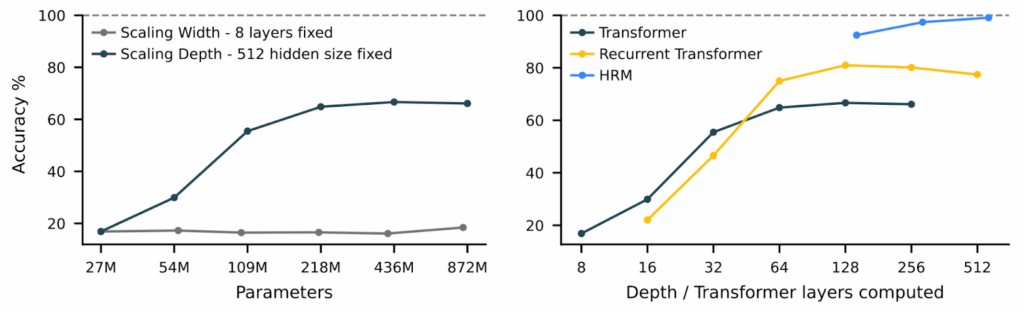
Знаменитый график METR с “горизонтом выполнимых задач” теперь показывает Claude Opus 4.5 на первом месте, с задачами длительностью почти 5 часов, выполняемыми с 50% точностью. Это, честно говоря, уже очень близко к полной замене человеческих программистов (да, конечно, ещё не совсем там, но всё же):
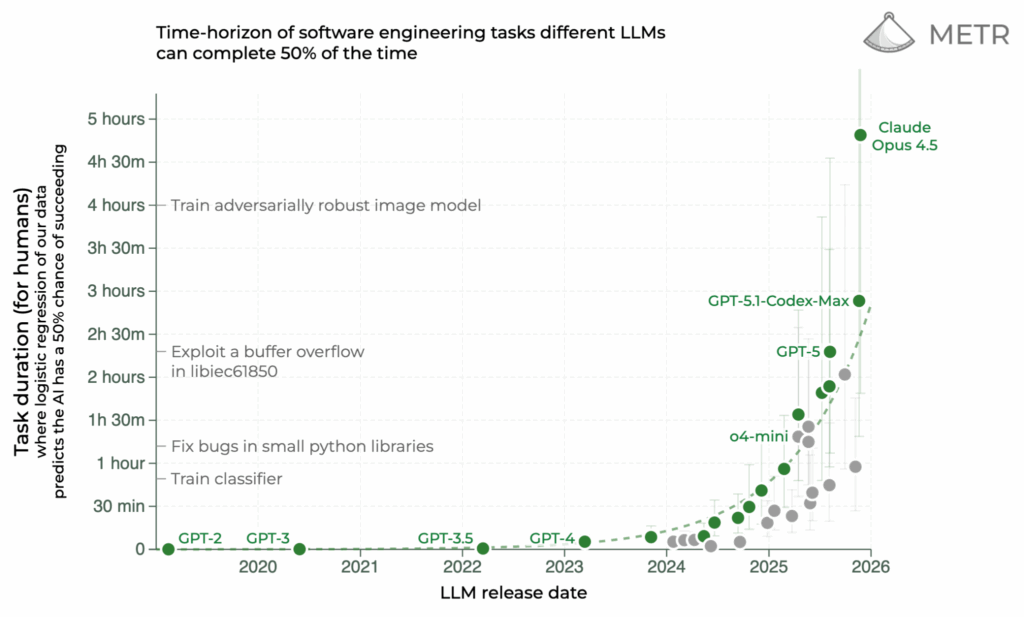
Как был достигнут этот прогресс? Начну с нескольких интересных академических работ.
ReTool (Feng et al., апрель 2025) показал, что при помощи RL модели могут научиться, когда и как вызывать интерпретаторы кода во время рассуждений — и это способность, которую обычное обучение с учителем дать не может. Они используют слегка модифицированный алгоритм PPO, изменённый так, чтобы лучше отражать внутренние рассуждения:
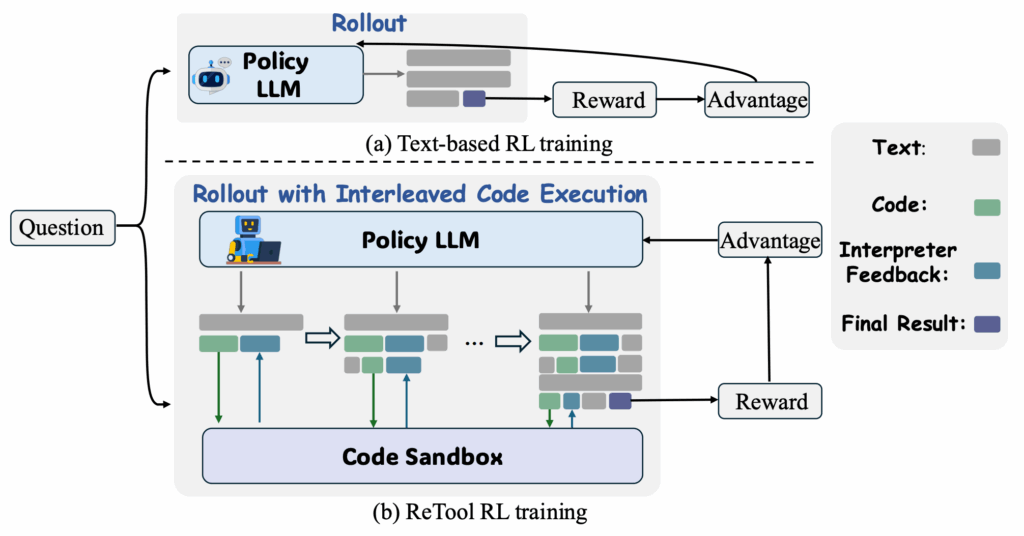
Что особенно интересно, модель в результате демонстрирует эмерджентные метакогнитивные способности (emergent metacognitive capabilities): она учится распознавать ошибки в коде по сообщениям интерпретатора, рефлексирует на естественном языке (“Oops, the functions need to be defined in the same scope”) и порождает исправленные версии. Такой “code self-correction” никогда не была явно обучена — она возникает из outcome-driven RL.
Метод Search-R1 (Jin et al., март 2025) применил похожие принципы к веб-поиску, обучая LLM автономно формулировать запросы во время многошаговых рассуждений с real-time retrieval. В отличие от RAG, который ищет один раз и надеется на лучшее, Search-R1 учится искать итеративно, уточняя запросы на основе найденного. Ключевая техническая новизна здесь — это retrieved token masking, т.е. исключение retrieved content из функции ошибки RL для того, чтобы предотвратить нежелательные эффекты в обучении. Результат — улучшение на 24% над RAG baselines на QA-бенчмарках.
Другой концептуальный прорыв был сделан в работе “Thinking vs. Doing” (Shen et al., июнь 2025), которая утверждает, что для интерактивных агентов “test-time compute” должен включать не только более длинные reasoning traces, но и больше шагов взаимодействия с окружением:

Взаимодействие с окружением позволяет агентам получать новую информацию, исследовать альтернативы, откатываться назад и динамически перепланировать; всё это те возможности, которых никакие внутренние рассуждения дать не могут. В результате этот подход под названием TTI (Test-Time Interaction) достигает лучших результатов на WebVoyager (64.8%) и WebArena (26.1%) с моделью Gemma 12B, существенно превосходя агентов, обученных традиционными подходами.
Нерешённые проблемы
Впрочем, нерешённых проблем тоже ещё много. Например, новый бенчмарк τ²-Bench (Barres et al., июнь 2025) ввёл новую постановку задачи, важную для оценки именно агентных систем: dual-control environments, где могут действовать и агент, и пользователь, как в реальных сценариях. Другие бенчмарки предполагают, что пользователь — это пассивный источник информации, но τ²-Bench моделирует более реалистичный случай, когда агенты должны направлять пользователей делать что-то, а пользователи выполняют эти действия на своих устройствах, как в реальной техподдержке:
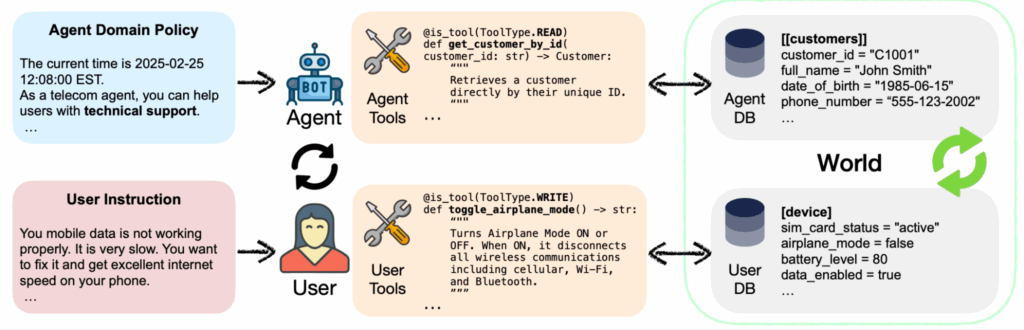
И результаты отрезвляющие: state-of-the-art LLM показывают падение на 18-25% при переходе от автономного режима к коллаборативному. Коммуникация и координация с людьми пока остаются слабыми местами существующих LLM-агентов.
Claude Code
На практике же главным агентским релизом 2025 года, несомненно, стал Claude Code. Он работает прямо в терминале, понимает вашу кодовую базу через поиск, может переписывать сразу несколько файлов, самостоятельно переключая контекст и понимая задачу в целом, а также может запускать сразу несколько агентов, выполняющих свои задачи:
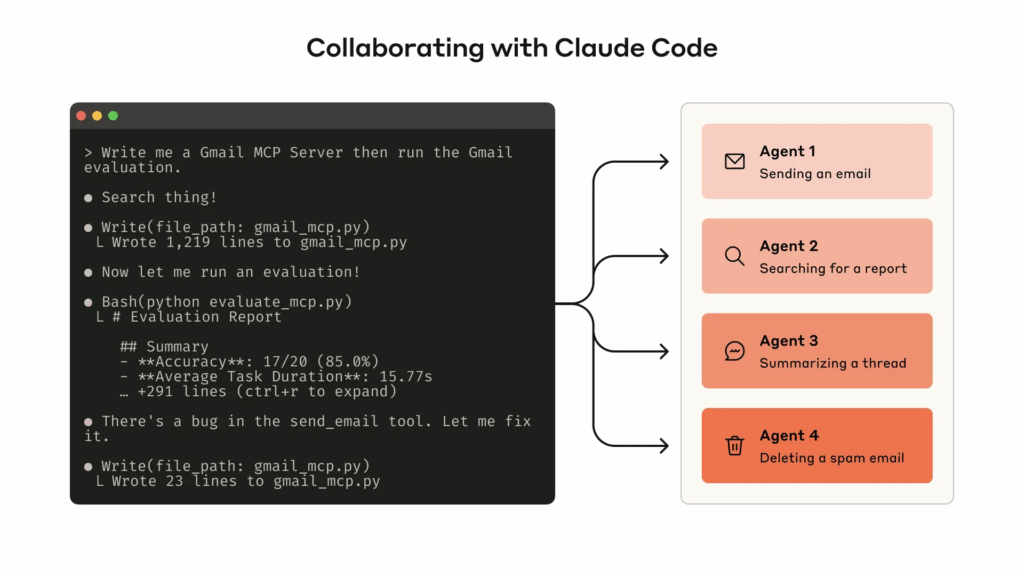
Как выразился Карпатый в том же посте, это “маленькое привидение, которое живёт в вашем компьютере” (кажется, ещё совсем недавно мы бы вряд ли были рады такому описанию).
В отличие от традиционных LLM for coding, которые пишут код и показывают его человеку, Claude Code может действовать более автономно; он запускает команды, создаёт pull requests, работает с git и так далее.
А человеку остаётся только разговаривать с интерфейсом Claude Code на естественном языке. И, кстати, пользователи соглашаются, что Claude Code лучше всего работает, когда к нему относятся как к джуниору с инструментами, памятью и способностью сделать несколько подходов к задаче.
И Claude Code — это не только программирование. Пользователи используют его для подготовки налоговых деклараций по анализу банковских выписок, бронирования билетов в театр по проверке календаря, обработки бизнес-документов. “Code” в названии продаёт продукт ниже его возможностей: это LLM-агент общего назначения, который может делать почти что угодно на вашем компьютере, используя код как интерфейс к другим задачам; см., например, свежий обзор Zvi Mowshowitz.
Я рассказывал о Claude Code, но это просто лучшее на данный момент предложение среди многих. Например, модели семейства GPT-Codex от OpenAI (например, GPT-5.1-Codex-Max) тоже отлично справляются с автономным программированием.
Мне кажется, что 2026-й станет годом, когда агенты для использования браузеров и компьютеров в целом прочно войдут в нашу обычную жизнь. CoWork от Anthropic, только что анонсированный как research preview, вполне может стать первой по-настоящему важной AI-новостью 2026 года.
Законы масштабирования для test-time compute и не только
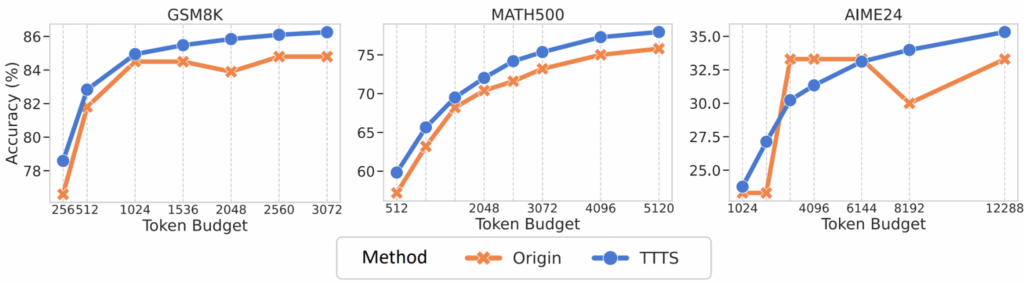
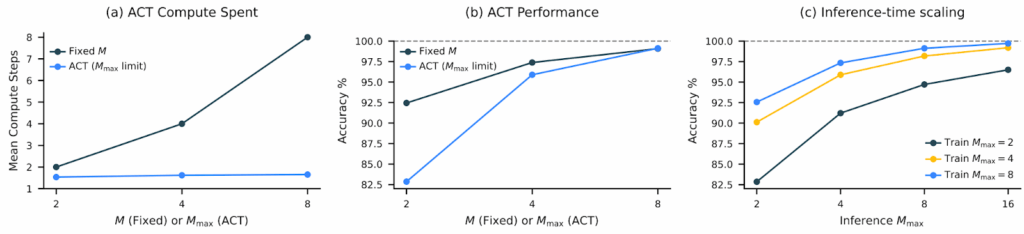
Я упоминал test-time compute scaling в начале: рассуждающие модели могут становиться лучше безо всякого дообучения, просто подумав побольше, и этот эффект заслуживает отдельного обсуждения. В 2025-м появились важные исследования о том, как эффективно масштабировать inference compute — и оказалось, что однозначного ответа нет.
Нет оптимальной стратегии, а маленькие модели могут обойти большие
Авторы “The Art of Scaling Test-Time Compute” (Agarwal et al., декабрь 2025) провели первое масштабное систематическое сравнение стратегий test-time scaling, сгенерировав более 30 миллиардов токенов на восьми open-source моделях.
Главный их вывод был в том, что никакая одна стратегия не доминирует во всех случаях. Оптимальный подход существенно зависит от типа модели и вычислительного бюджета. Авторы вводят важное различие между:
- моделями с коротким горизонтом (short-horizon), которые выигрывают от более коротких reasoning traces независимо от сложности; такие модели часто обучены через GRPO;
- моделями с длинным горизонтом (long-horizon), которые выигрывают от долгих рассуждений на сложных задачах; они часто обучаются другими RL-методами вроде GSPO.
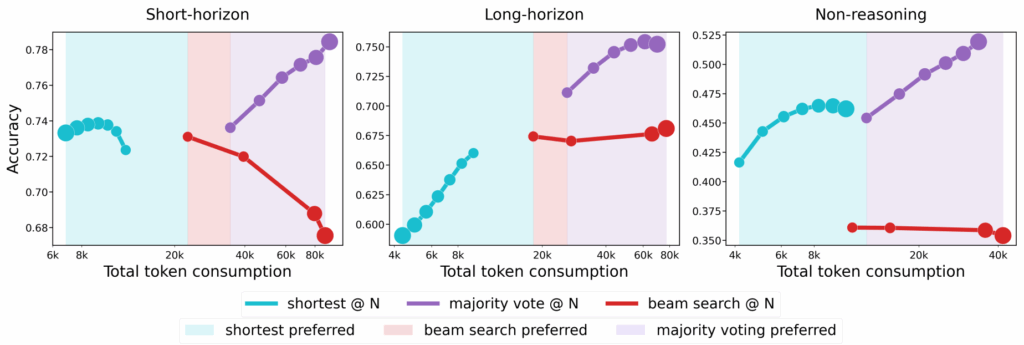
На практике это значит, что выбор между majority voting, beam search и “first finish search” должен учитывать, к какой категории относится ваша модель.
Ещё одна интересная демонстрация compute-optimal inference была дана в работе “Can 1B LLM Surpass 405B LLM?” (Liu et al., февраль 2025). Ответ на титульный вопрос получился утвердительным: с правильной стратегией test-time scaling, 1B-модель может превзойти 405B-модель на MATH-500, а 7B-модель может побить и o1, и DeepSeek-R1 на AIME2024.
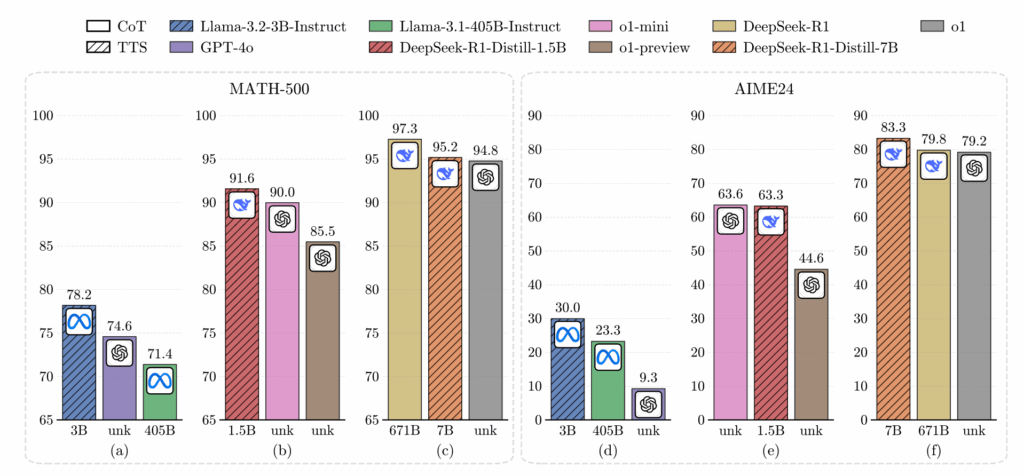
Ключевой инсайт здесь в том, что оптимальный метод масштабирования зависит и от размера модели (search-based для маленьких, Best-of-N для больших), и от сложности задачи. Предложенные compute-optimal стратегии могут оказаться в 256 раз более эффективными, чем простое голосование. Это говорит нам, что в будущем, возможно, мы сможем использовать и маленькие, более эффективно масштабируемые модели вместо того, чтобы просто автоматически выбирать самую большую модель из возможных.
Куда тратить вычислительный бюджет?
Все эти разговоры на практике нужны для того, чтобы решить, куда тратить ограниченный вычислительный бюджет. И об этом тоже было несколько работ с неожиданными результатами, а точнее, частенько даже с неожиданной постановкой вопроса (“а что, так можно было?”).
Так, например, метод GenPRM (Zhao et al., апрель 2025) показал, что сами process reward models можно масштабировать во время inference. Авторы переформулируют верификацию как задачу для рассуждений с явным chain-of-thought и строят модель GenPRM-7B, которая превосходит Qwen2.5-Math-PRM-72B на соответствующих бенчмарках, будучи в 10 раз меньше.
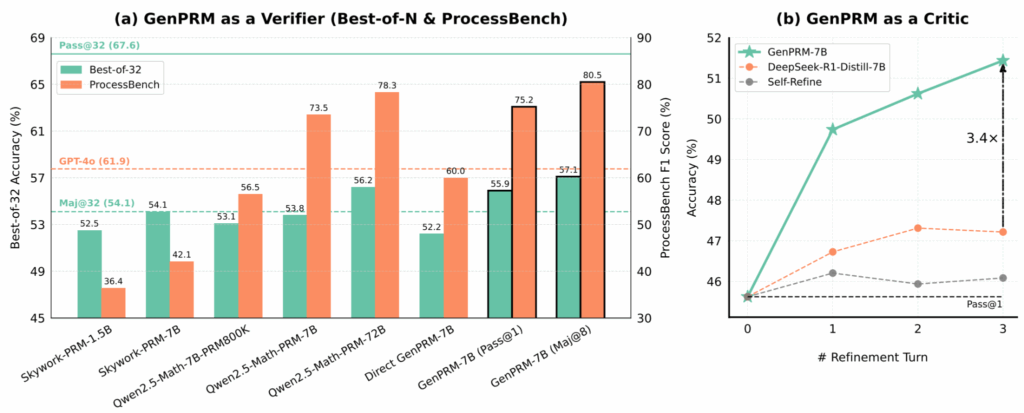
Но тут же это направление поставили под вопрос: когда выгоднее направлять compute на порождение, а когда на верификацию? Этот вопрос был поставлен в работе “When To Solve, When To Verify” (Singhi et al., апрель 2025). Несколько контринтуитивно оказалось, что стратегия Self-Consistency (порождение многих решений и выбор голосованием) превосходит Generative Reward Models (GenRM) при практических значениях вычислительных бюджетов. GenRM требует примерно 8x больше compute, чтобы просто сравняться с Self-Consistency, и 128x больше для скромного улучшения на 3.8%:
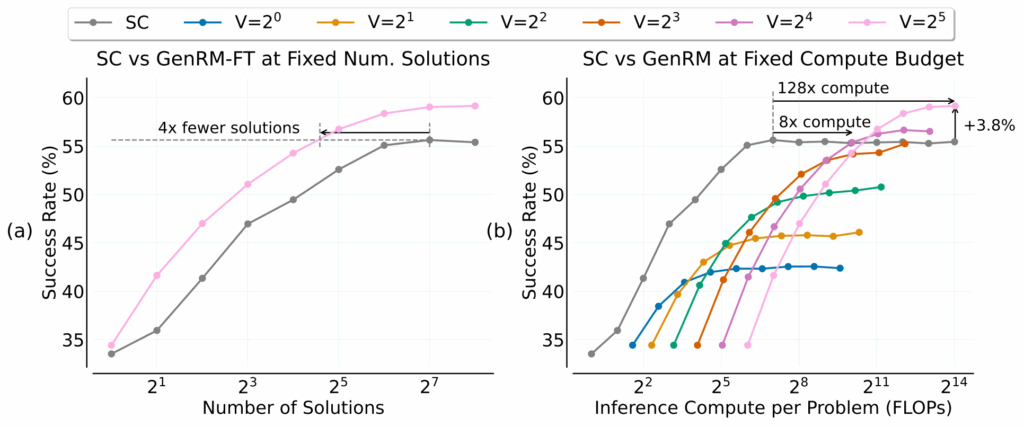
Это говорит о том, что в большинстве практических случаев масштабирование путём порождения большого числа решений остаётся эффективнее, чем инвестиции в более умную верификацию, хотя баланс смещается для очень сложных задач.
А работа “S*: Test Time Scaling for Code Generation” (Li et al., февраль 2025) представила первый гибридный test-time scaling framework специально для кода. Поскольку для кода можно проводить автоматическую программную верификацию, можно попробовать двухэтапный подход:
- сначала порождать множество решений с итеративной отладкой по выполнению тестов, а затем
- выбирать лучшее через adaptive input synthesis, т.е. просить LLM порождать тесты, различающие каждую пару возможных решений.
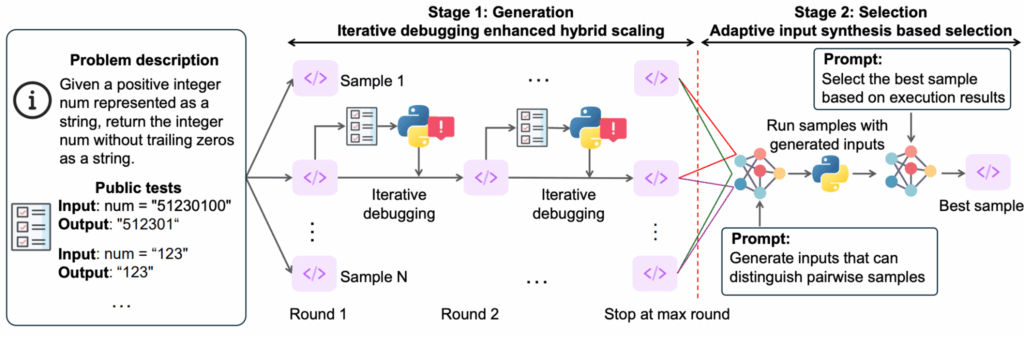
Любопытно, что стратегия S* позволяет instruction-based моделям приближаться к и даже превосходить reasoning models, что говорит о том, что хорошие стратегии во время inference могут заменить дорогое обучение рассуждениям.
Это, кстати, тоже пока ещё общее место, не раз подтверждавшееся в 2025 году: часто оказывается, что можно сделать хорошую дистилляцию из большой (скорее всего рассуждающей) модели и получить маленькую модель, которая даёт хорошие (в своём классе) результаты без всяких рассуждений. Посмотрим, изменит ли 2026-й это положение дел.
Новые архитектуры
Вполне возможно, что мы увидим, как в 2026-м трансформеры если не заменятся, то хотя бы дополнятся другими архитектурами. И здесь, конечно, надо писать отдельный пост, а то и несколько.
К счастью, я уже написал почти все эти посты, так что просто назову три направления, которые кажутся мне самыми перспективными на данный момент:
- Google Titans, которую выпустили под новый 2025-й год; об этом я писал в посте “Attack of the Titans: Transformers 2.0?“;
- Mamba-like state-space models; здесь у меня есть вводный пост “Linear Attention and Mamba: New Power to Old Ideas“, но вообще, конечно, нужно было бы сделать отдельный большой обзор; и мы уже сделали его в этом году на семинаре лаборатории Маркова — рекомендую посмотреть соответствующие доклады;
- диффузионные LLM; введение в диффузионные модели когда-то было в моём блоге, но, конечно, оно уже безнадёжно устарело; про новые результаты в диффузионках мы поговорим в другой части обзора, а здесь просто упомяну, что в 2025-м давно уже существовавшие диффузионные языковые модели (Li et al., 2022) наконец-то начали масштабироваться в виде LLaDA (Large Language Diffusion Models; Nie et al., 2025).
В общем, нейросетевые архитектуры не стоят на месте, и новые идеи всё время появляются, но много писать я о них в этом посте не буду.
Разное
В заключительной части просто упомяну несколько других статей, которые показались мне любопытными.
Действительно ли RL улучшает reasoning?
“Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?” (Yue et al., апрель 2025). Эта статья, вышедшая на NeurIPS 2025, ставит под вопрос предположения, лежащие в основе рассуждающих моделей в целом.
Используя pass@k при больших k для оценки границ возможностей рассуждающих моделей, авторы систематически демонстрируют, что хотя RLVR улучшает точность (pass@1) в среднем, базовые модели устойчиво достигают более широкого reasoning coverage при высоких k, т.е. если породить кучу ответов и выбрать лучший.
Это подтверждается на многих бенчмарках (MATH500, AIME24, LiveCodeBench и других), семействах моделей (7B-32B) и RL алгоритмах (PPO, GRPO, Reinforce++, RLOO, ReMax, DAPO). RL для маленьких k, конечно, побеждает, но графики неизбежно пересекаются в какой-то точке:
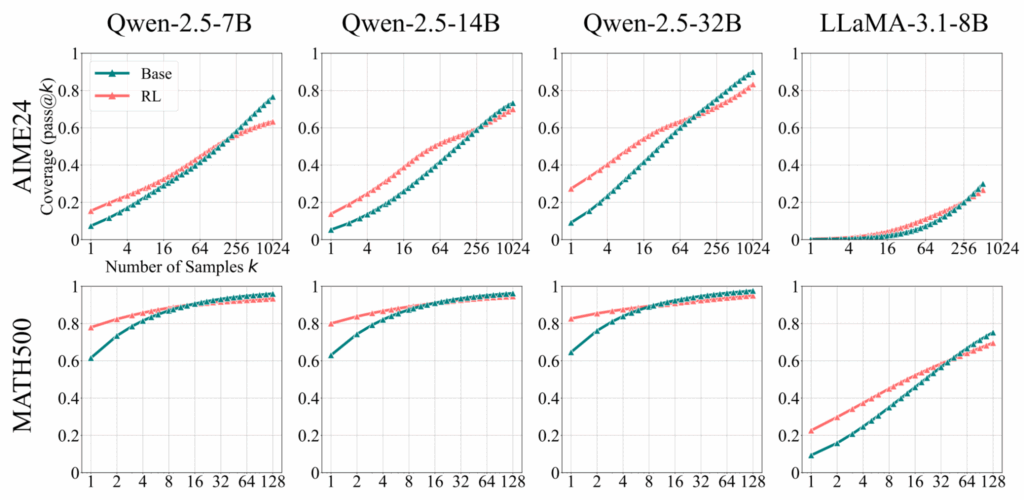
Анализ, проведённый в этой работе, подтверждает, что те цепочки рассуждений, которые появляются после RLVR, на самом деле уже есть и в распределении базовой модели — модель просто учится сэмплировать их эффективнее. А новых способностей, получается, и не появляется!..
С другой стороны, дистилляция от более сильных моделей-учителей действительно может расширить границы возможного и дать новые рассуждения, которых раньше модель проводить не умела.
Всё это говорит о том, что текущие методы RLVR функционируют скорее как способы более эффективного сэмплирования из распределения возможных рассуждений базовой модели, чем как реальные улучшения способностей к этим рассуждениям. Это важно для того, чтобы понимать и потенциал, и пределы возможностей рассуждающих моделей.
Когнитивные паттерны для самостоятельного улучшения
“Cognitive Behaviors that Enable Self-Improving Reasoners” (Gandhi et al., март 2025) даёт механистическое объяснение того, почему одни модели существенно улучшают себя после применения RL-дообучения, а другие выходят на плато.
Авторы выделяют четыре ключевых когнитивных поведения — verification, backtracking, subgoal setting и backward chaining — которые соответствуют стратегиям, которые люди-эксперты применяют для решения задач. Модели, естественно демонстрирующие эти поведения (например, Qwen-2.5-3B), достигают 60% accuracy на Countdown benchmark после RL-дообучения, тогда как модели без них (например, Llama-3.2-3B) выходят на плато в 30% при идентичных условиях.
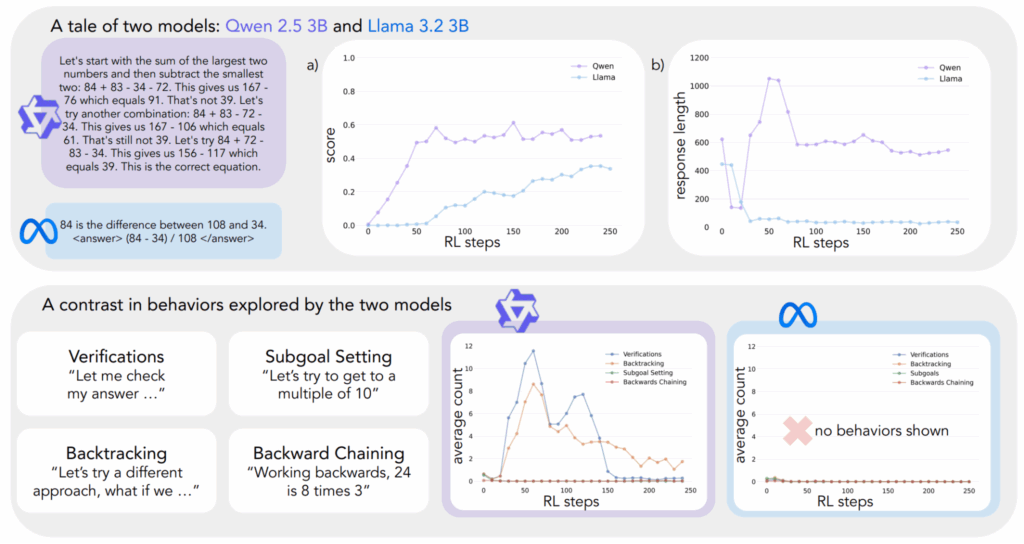
Самый поразительный результат здесь в том, что если дать модели неправильные решения, которые всё-таки демонстрируют правильные паттерны размышлений, этого будет достаточно, чтобы их качество работы сравнялось с моделями, обученными на правильных решениях.
То есть важен на самом деле доступ к правильным когнитивным паттернам, а не к правильным ответам. Это важно и на практике, для подготовки датасетов, и, честно говоря, философски очень интересно.
Gated Attention
“Gated Attention for LLMs” (Qiu et al., сентябрь 2025) — важный (и очень практический) результат, получивший Best Paper award на NeurIPS 2025; это та архитектурная работа, мимо которой всё-таки не пройти. Авторы добавляют простой sigmoid gating mechanism к выходу каждой головы внимания.
Авторы протестировали более 30 вариаций и сошлись на одной, которая устойчиво улучшала результаты:
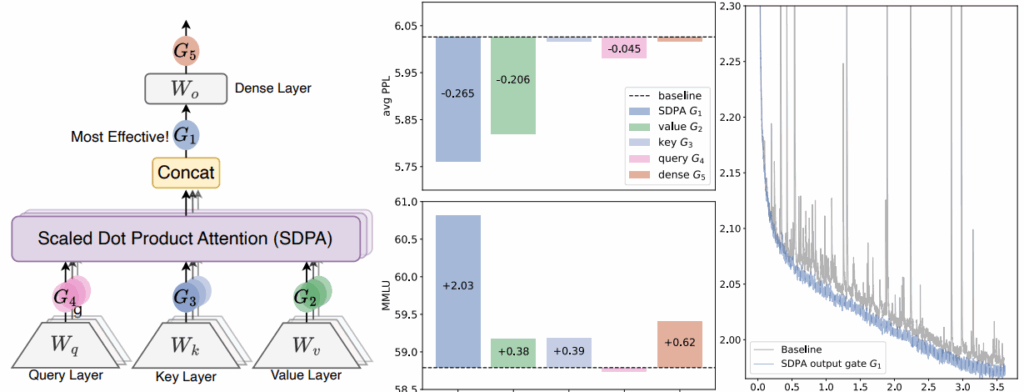
Теоретический инсайт здесь в том, что гейт добавляет небольшую нелинейность внутри обычного механизма внимания, который так-то является в основном линейной операцией (не считая softmax-нормализации). Эта нелинейность помогает избежать проблемы “attention sink”, когда несколько токенов доминируют в головах внимания и, как следствие, в градиентах. Кроме того, это улучшает работу с длинным контекстом, позволяя моделям лучше экстраполировать свою работу на контекст длиннее, чем они видели при обучении.
Тот факт, что эта идея была немедленно использована в реальном семействе фронтирных LLM — Qwen-3 от Alibaba уже используют gated attention — доказывает практическую ценность работы и показывает, что академические результаты отнюдь не бесполезны на практике даже в нашу эпоху закрытых гигантских LLM.
Заключение
Итак, что мы имеем по итогам 2025 года в области больших языковых моделей?
Во-первых, reasoning models — это реально. Это не маркетинг и не хайп. RLVR действительно работает (хотя есть и интересные возражения), модели действительно научились “думать” (пусть пока в кавычках), и это приводит к качественному скачку на задачах, требующих многошаговых рассуждений. Золотые медали на IMO и ICPC — это уже не просто красивые цифры для пресс-релизов, а ещё более убедительную демонстрацию прогресса я, пожалуй, отложу до раздела об AI в науке.
Во-вторых, test-time compute scaling стал новым измерением оптимизации. Раньше мы в основном думали о том, как масштабировать обучение. Теперь inference тоже можно масштабировать, причём часто это оказывается эффективнее. Маленькие модели с правильным test-time scaling могут обойти модели в сотни раз больше.
В-третьих, LLM-агенты наконец-то начали работать на практике. MCP стандартизировал взаимодействие с инструментами, computer use приблизился к человеческому уровню, а Claude Code вывел автономных агентов на новый уровень, причём не только в программировании. METR-график с 5-часовыми решаемыми задачами уже сегодня выглядит пугающе для тех, кто зарабатывает программированием — а что будет ещё через год?
В-четвёртых, открытые модели отстают совсем не так уж сильно. DeepSeek продолжает показывать, что open source модели могут конкурировать с лучшими проприетарными, по крайней мере в специализированных задачах; но их “специализация” — это математические рассуждения, что совсем не так уж узко.
Что дальше? Мне кажется, что даже если новых революций (например, заката эпохи трансформеров) не произойдёт, 2026-й станет годом широкого использования и развития того, что было разработано в 2025-м. Browser agents, computer use, agentic coding — всё это уже стало очень популярным, а в течение года должно уже прочно закрепиться на массовом рынке. Кроме того, возможно, мы всё-таки увидим первые серьёзные альтернативы трансформерам в архитектуре LLM — Mamba, Titans, диффузионные LLM ждут своего часа.
В следующих частях обзора мы поговорим о других аспектах искусственного интеллекта: о моделях, работающих с изображениями, об AI safety, о роботике и так далее. С наступившим 2026-м, коллеги!
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале «Sineкура»: присоединяйтесь!



![\[I(X; Y) = \sum_{x \in X} \sum_{y \in Y} p(x,y) \log \frac{p(x,y)}{p(x)p(y)},\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-1dbe002d3b4df2453b18f742dbe02aca_l3.svg "Rendered by QuickLaTeX.com")
![\[I(X; Y) = \int_Y \int_X p(x,y) \log \frac{p(x,y)}{p(x)p(y)} \, dx \, dy.\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-194d1847b64c5002cfa51e1bf954e47a_l3.svg "Rendered by QuickLaTeX.com")
![\[I(X; Y) = H(X) - H(X|Y) = H(Y) - H(Y|X),\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-45ffcccdeaa6b56e9081b7a09a0c7ce5_l3.svg "Rendered by QuickLaTeX.com")
 — энтропия
— энтропия  , а
, а  — условная энтропия
— условная энтропия  . Интуитивно говоря, взаимная информация измеряет, насколько знание одной величины уменьшает неопределённость относительно другой. Eсли
. Интуитивно говоря, взаимная информация измеряет, насколько знание одной величины уменьшает неопределённость относительно другой. Eсли  , величины независимы, а если
, величины независимы, а если  , они полностью детерминированы друг другом.
, они полностью детерминированы друг другом.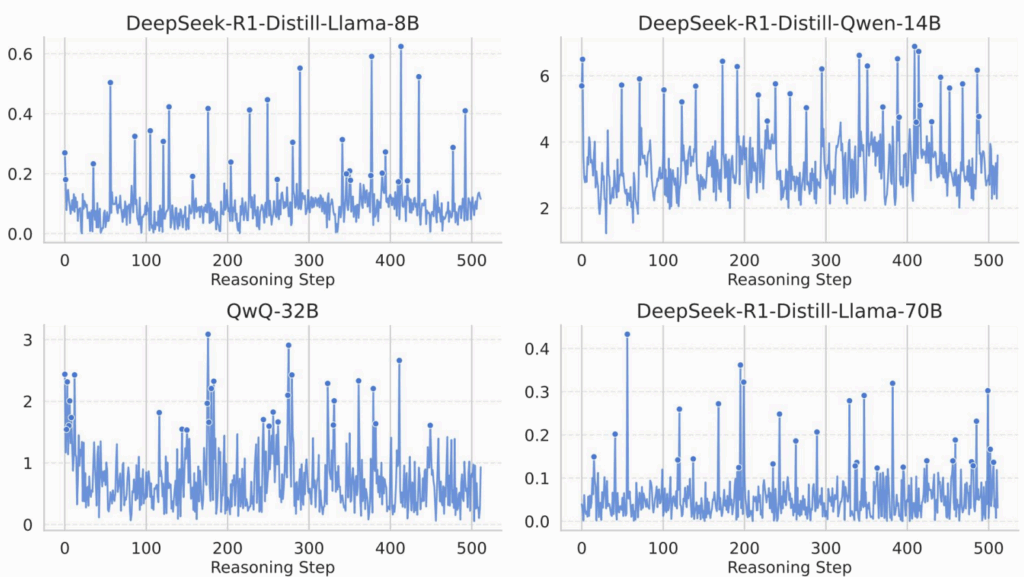
 — последовательность представлений модели,
— последовательность представлений модели,  — правильный ответ,
— правильный ответ,  — предсказание модели,
— предсказание модели,  — вероятность ошибки. Тогда
— вероятность ошибки. Тогда  можно оценить с двух сторон (это и есть две теоремы в статье):
можно оценить с двух сторон (это и есть две теоремы в статье):![\[p_e \geq \frac{1}{\log(|Y| - 1)} \left[ H(y) - \sum_{j=1}^T I(y; h_j \mid h_{<j}) - H_b(p_e) \right],\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-c85485e15e97ff6d62455086ddb086d1_l3.svg "Rendered by QuickLaTeX.com")
![\[p_e \leq \frac{1}{2} \left[ H(y) - \sum_{j=1}^T I(y; h_j \mid h_{<j}) \right],\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-c1919722ec08f877b42bc746d1819134_l3.svg "Rendered by QuickLaTeX.com")
 — размер пространства возможных ответов,
— размер пространства возможных ответов,  — энтропия распределения правильного ответа,
— энтропия распределения правильного ответа,  — условная MI между
— условная MI между  при условии предыдущих представлений,
при условии предыдущих представлений,  — энтропия вероятности ошибки.
— энтропия вероятности ошибки. , на шаге
, на шаге  модель имеет представление
модель имеет представление  . Это представление используется для предсказания следующего токена
. Это представление используется для предсказания следующего токена  , но пик MI в
, но пик MI в  отражает информацию, накопленную до порождения
отражает информацию, накопленную до порождения  или раньше. Поэтому просто взять токен
или раньше. Поэтому просто взять токен 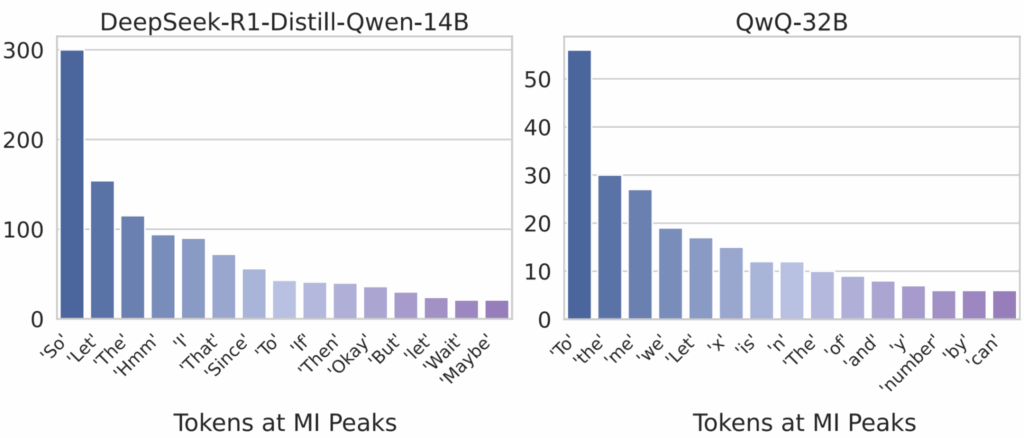

 ) фиксируем пик MI, нужно взять это внутреннее представление
) фиксируем пик MI, нужно взять это внутреннее представление  .
.  (представление предыдущего слоя), а во втором проходе (recycling) self-attention видит
(представление предыдущего слоя), а во втором проходе (recycling) self-attention видит  , результат первого прохода, в котором эти представления уже один раз “посмотрели друг на друга”. Понятно, что формально это новый вход, и выход будет тоже другой, но это и интуитивно имеет смысл.
, результат первого прохода, в котором эти представления уже один раз “посмотрели друг на друга”. Понятно, что формально это новый вход, и выход будет тоже другой, но это и интуитивно имеет смысл.