
The Plucky Squire — это игра, у которой очень много на первый взгляд положительных сторон: красивый визуальный стиль, разнообразный геймплей, мета-нарратив, который сразу же ломает четвёртую стену; в игре несколько типов загадок, про каждому из которых можно было бы сделать отдельную крутую игру… Но, увы, каждый из этих пунктов (кроме разве что визуала) откровенно недожат; давайте посмотрим в деталях.
История создания и разработчики
The Plucky Squire — дебютный проект инди-студии All Possible Futures, основанной в июне 2022 года двумя ветеранами игровой индустрии: британским дизайнером Джеймсом Тёрнером и креативным директором Джонатаном Биддлом.
Тёрнер пришёл в игровую индустрию из анимации: сначала он делал телерекламу, а потом восемь лет работал над играми серии Pokémon. Собственно, настоящую известность Тёрнер приобрёл после перехода в Game Freak в 2009 году — он стал первым западным дизайнером, официально создававшим покемонов, а потом даже стал арт-директором основной серии в играх Pokémon Sword и Shield.

А Джонатан Биддл был совладельцем и директором по дизайну издательства Curve Digital, а в 2015 году основал собственную студию Onebitbeyond и создал The Swords of Ditto — roguelike RPG с очаровательным визуальным стилем, но плохими оценками; я не играл, но критиковали The Swords of Ditto за скучный повторяющийся геймплей… и к этому мы ещё вернёмся.

В общем, с артом и дизайном в The Plucky Squire всё должно было быть хорошо. Проект начался с концептуальной идеи Тёрнера о трёхмерной книге, и главные персонажи были им созданы ещё до начала работы над игрой. А первый анонс в июне 2022 года на летнем показе Devolver Digital произвёл фурор — механика переключения между 2D-книгой и 3D-миром мгновенно привлекла внимание. По словам Биддла, после выхода трейлера студия даже беспокоилась, что кто-то реализует похожую идею быстрее, но вышло наоборот: именно этот ролик помог привлечь новых разработчиков в команду, и в итоге игра вышла в сентябре 2024 года.
Отличные идеи
Хотя это очень детская игра по визуалу, настроению и всему остальному, по сути она очень интересно играет с четвёртой стеной. Спойлерить сильно не буду, но здесь и не надо, слом происходит в самом начале. Кстати, если бы это было не так, обзор написать было бы очень сложно — до сих пор не представляю, например, как написать обзор Doki Doki Literature Club (но поиграть очень рекомендую!).
Здесь всё начинается с того, что твоего персонажа (the plucky squire по имени Jot) представляют как главного героя сказочного королевства, которого все знают, все хвалят и считают главной надеждой на будущее королевства.




Сказочная страна, кстати, сделана нарочито по-детски, но весело и разнообразно. Королевство Artia состоит из пародий на великих художников:




А на горе живут тролли-викинги, которые логично любят металл:



Но быстро выясняется, что действие игры действительно происходит в книге сказок. Более того, многие персонажи понимают это! Четвёртая стена сначала ломается, а потом её обломки сметают в сторону, и больше про неё уже никто не вспоминает.


Центральная механика игры построена на уникальной способности главного персонажа, собственно plucky squire по имени Jot: он может выйти из книги и попасть в трёхмерный мир, а именно в комнату мальчика Сэма, которому принадлежит книга. Именно она должна вдохновить Сэма стать писателем в будущем, и герой должен сохранить историю, чтобы не разрушить творческое будущее ребёнка.
Трёхмерный мир действительно красивый: письменный стол с разбросанными игрушками, полки с книгами и поделками — всё это очень детально проработано и создаёт отличную атмосферу. Вау-эффект действительно есть:






Более того, герой может не просто повоевать в 3D с трёхмерными версиями тех же врагов и добраться до какого-то нужного предмета (такие эпизоды в игре встречаются регулярно), но и взаимодействовать с самой книгой: перелистывать страницы, манипулировать объектами на столе, использовать предметы из “реального” мира для решения головоломок в книге.



Но и это ещё не всё! Сражения с боссами представляют собой очень круто оформленные мини-игры: первый босс — это пародия на классический Punch-Out!!, дальше встречаются ритм-игры, шутеры… Каждый босс удивляет новой механикой.





А кроме загадок с четвёртой стеной, здесь есть ещё и детская версия Baba Is You! Некоторые загадки представляют собой предложения, из которых можно вынимать слова, и когда на их место вставляешь другие слова, окружение меняется в соответствии с новым описанием:



В общем, звучит как мечта: и красиво, и разнообразно, и без четвёртой стены, и несколько необычных типов загадок, про каждый из которых можно было бы сделать отдельную крутую игру! Но здесь начинаются минусы.
Посредственная реализация
К сожалению, при всей визуальной привлекательности и изобретательности концепции, The Plucky Squire на всём своём протяжении страдает от одной и той же проблемы: разработчики как будто побоялись сделать игру требующей хоть каких-то усилий. Это не просто “лёгкая игра” — это игра, где практически отсутствует любое сопротивление.
Начнём с боевой системы: она есть, но непонятно зачем. Игра предлагает два уровня сложности, но это ничего не меняет — враги наносят минимальный урон, их атаки легко предсказуемы и ещё легче избегаются, а сами бои занимают считанные секунды. У Jot есть меч, уклонение и несколько разблокируемых способностей, но использовать их тактически не требуется — достаточно просто отмахиваться оружием от врагов. Ни разу за всё прохождение я не умер в обычном бою.
Но это полбеды: если бы разработчики сделали боевую систему действительно сложной и превратили бы игру в souls-like, это тоже был бы шаг в неверном направлении; суть игры всё-таки не в этом. Пожалуй, лучше было бы бои вообще убрать, или превратить их в головоломки.
Кстати, про головоломки — вот здесь, увы, катастрофа. Блестящая идея с использованием книги, переворачиванием страниц и даже ещё кое-какими механиками практически не используется совсем. Только в самом конце игры начали появляться хоть немного интересные загадки с переворачиванием страниц, где хоть до чего-то нужно догадаться. До этого всё абсолютно тривиально.
Механика со словами — та самая условная Baba Is You — разработана ещё хуже: до самого финала загадки остаются на уровне “замени слово dark на light“. Нет ни одной головоломки, где нужно было бы подумать о цепочке замен или о неочевидном использовании слов.
Разработчики явно не доверяют игроку. Каждая головоломка сопровождается избыточными подсказками, персонажи прямым текстом объясняют, что нужно сделать, а ещё при каждой головоломке сидит Minibeard, готовый дать дополнительные подсказки (это как раз не страшно, но страшно, что они совсем-совсем никогда не нужны). Можно было бы сказать, что игру делали для детей младшего школьного возраста… но ведь, несмотря на детскую стилистику, юмор в игре происходит из метанарратива и явно рассчитан на взрослый взгляд.
Я прошёл игру за 7-8 часов, что для такого проекта совсем немного. Но ощущалось это как гораздо более долгое прохождение, потому что в геймплее так и не появилось ничего интересного. Время от времени появляются новые способности, но используются они всё так же тривиально.
Сюжет тоже разочаровывает. Злодей Humgrump осознаёт, что он персонаж книги и всегда обречён проигрывать, поэтому выбрасывает героя из книги и пытается переписать историю. Звучит очень интересно! Но на деле интересного развития метанарратива или неожиданных поворотов я так и не дождался (кроме буквально одного момента, который не буду спойлерить).
Детская стилистика совершенно не мешает сделать крутую глубокую игру, особенно когда вы выходите на мета-уровень (Undertale, anyone?), но, увы, не в этом случае. Студия All Possible Futures не оправдала своего названия.
Отдельно отмечу технические недостатки. У меня (судя по отзывам, не только у меня) в какой-то момент игра начала жутко тормозить: постоянные заикания и фризы, которые буквально не давали проходить платформинг-части и мешали боям. И это на RTX 3080 Ti! Сначала я грешил на оптимизацию трёхмерного мира, но потом ближе к концу игры всё нормализовалось, так что, вероятно, это какой-то баг в конкретных локациях.
Но не всё так плохо
Справедливости ради, нужно отметить, что игра действительно сделана с любовью и вниманием к деталям. Визуальный стиль безупречен: двухмерная часть в книге выглядит как качественная детская иллюстрация, со своим стилем и обаянием, а трёхмерный мир детской комнаты наполнен деталями и отсылками. Переходы между измерениями зрелищные, музыка приятная.






Отсылки к истории видеоигр и поп-культуре действительно остроумные — от пародий на классические аркады до милых намёков на другие игры. Мир разнообразен: от пасторальных лугов до индустриальных заводов, от снежных гор до вулканов. Персонажи обаятельные, диалоги часто забавные.
Кроме того, я говорил выше об основном геймплее и загадках, но в остальном надо признать, что игра очень старается быть разнообразной. Часто попадаются необычные вставки из разных жанров: то тебе предлагают небольшую ритм-игру, то пиксельный платформер, то скролл-шутер, то “три в ряд”… Каждый из этих сегментов действительно прикольно сделан; но они занимают 2-3 минуты каждый, а основной геймплей, увы, недоработан.
И тем не менее, в первые пару часов игра постоянно удивляет и радует. И основная идея, и каждый новый трюк с четвёртой стеной воспринимаются очень круто, каждая смена геймплея интересна. Проблема в том, что есть и следующие шесть часов, когда что-то интересное происходит уже весьма редко.
Заключение
К сожалению, должен признать, что The Plucky Squire — это игра упущенных возможностей. Здесь множество крутых идей, красивый визуальный стиль, обаятельный мир… но многие из этих элементов так и остались на уровне концепции. The Plucky Squire вводит новую механику, логично даёт пару простых примеров, чтобы игрок разобрался в ней… но на этом всё, дальше будут примеры на том же уровне, а потом новая механика.
Если вы ищете лёгкую, расслабленную игру, которая не требует вовлечения и просто приятно смотрится — The Plucky Squire подойдёт. Первые два часа действительно вдохновляют и удивляют. Но будьте готовы к тому, что дальше может оказаться не так круто; эту книгу интересно полистать, но вряд ли захочется перечитывать.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!







")























![\[I(X; Y) = \sum_{x \in X} \sum_{y \in Y} p(x,y) \log \frac{p(x,y)}{p(x)p(y)},\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-1dbe002d3b4df2453b18f742dbe02aca_l3.svg "Rendered by QuickLaTeX.com")
![\[I(X; Y) = \int_Y \int_X p(x,y) \log \frac{p(x,y)}{p(x)p(y)} \, dx \, dy.\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-194d1847b64c5002cfa51e1bf954e47a_l3.svg "Rendered by QuickLaTeX.com")
![\[I(X; Y) = H(X) - H(X|Y) = H(Y) - H(Y|X),\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-45ffcccdeaa6b56e9081b7a09a0c7ce5_l3.svg "Rendered by QuickLaTeX.com")
 — энтропия
— энтропия  , а
, а  — условная энтропия
— условная энтропия  . Интуитивно говоря, взаимная информация измеряет, насколько знание одной величины уменьшает неопределённость относительно другой. Eсли
. Интуитивно говоря, взаимная информация измеряет, насколько знание одной величины уменьшает неопределённость относительно другой. Eсли  , величины независимы, а если
, величины независимы, а если  , они полностью детерминированы друг другом.
, они полностью детерминированы друг другом.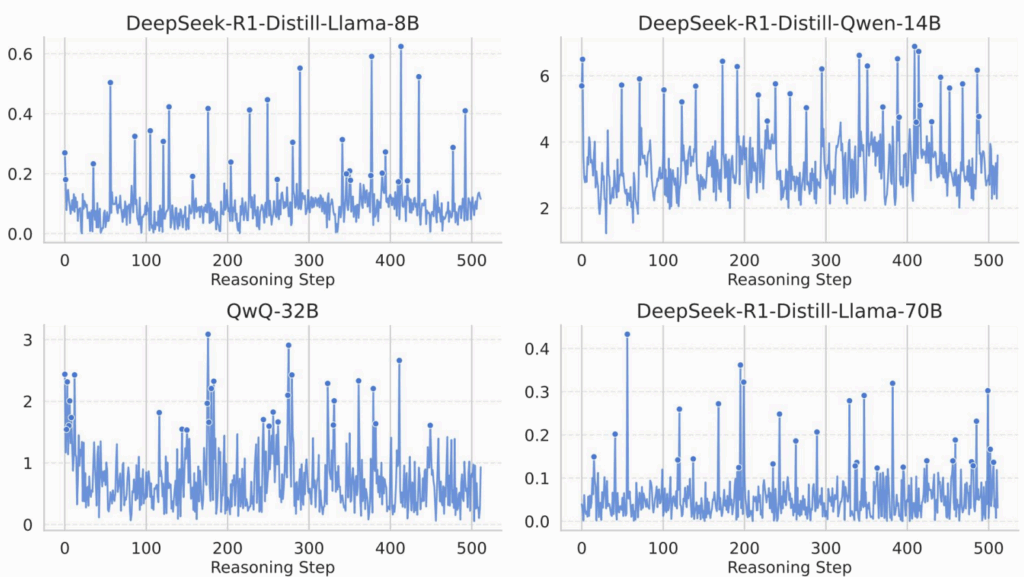
 — последовательность представлений модели,
— последовательность представлений модели,  — правильный ответ,
— правильный ответ,  — предсказание модели,
— предсказание модели,  — вероятность ошибки. Тогда
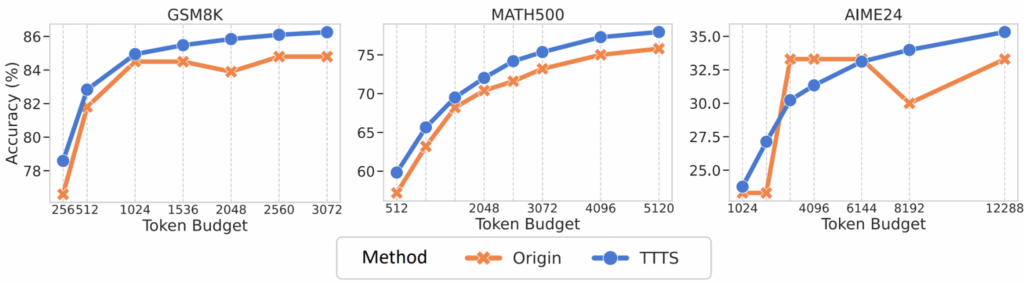
— вероятность ошибки. Тогда  можно оценить с двух сторон (это и есть две теоремы в статье):
можно оценить с двух сторон (это и есть две теоремы в статье):![\[p_e \geq \frac{1}{\log(|Y| - 1)} \left[ H(y) - \sum_{j=1}^T I(y; h_j \mid h_{<j}) - H_b(p_e) \right],\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-c85485e15e97ff6d62455086ddb086d1_l3.svg "Rendered by QuickLaTeX.com")
![\[p_e \leq \frac{1}{2} \left[ H(y) - \sum_{j=1}^T I(y; h_j \mid h_{<j}) \right],\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-c1919722ec08f877b42bc746d1819134_l3.svg "Rendered by QuickLaTeX.com")
 — размер пространства возможных ответов,
— размер пространства возможных ответов,  — энтропия распределения правильного ответа,
— энтропия распределения правильного ответа,  — условная MI между
— условная MI между  при условии предыдущих представлений,
при условии предыдущих представлений,  — энтропия вероятности ошибки.
— энтропия вероятности ошибки. , на шаге
, на шаге  модель имеет представление
модель имеет представление  . Это представление используется для предсказания следующего токена
. Это представление используется для предсказания следующего токена  , но пик MI в
, но пик MI в  отражает информацию, накопленную до порождения
отражает информацию, накопленную до порождения  или раньше. Поэтому просто взять токен
или раньше. Поэтому просто взять токен 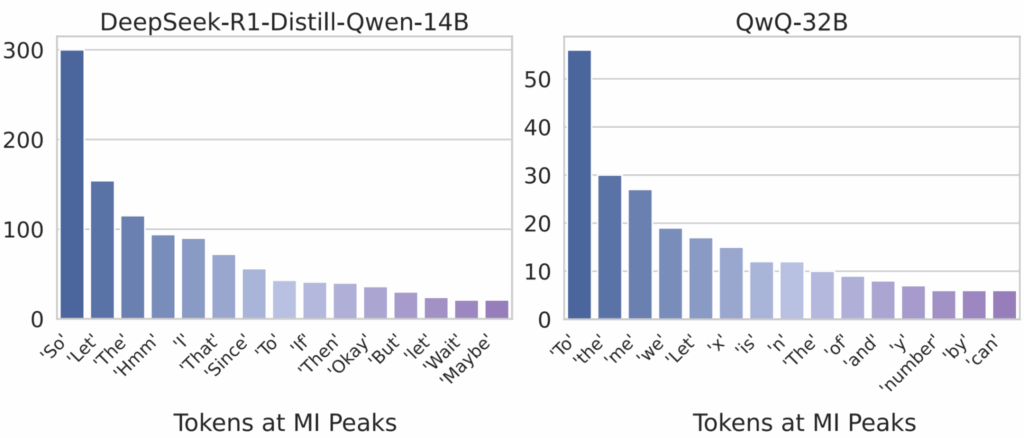

 ) фиксируем пик MI, нужно взять это внутреннее представление
) фиксируем пик MI, нужно взять это внутреннее представление  .
.  (представление предыдущего слоя), а во втором проходе (recycling) self-attention видит
(представление предыдущего слоя), а во втором проходе (recycling) self-attention видит  , результат первого прохода, в котором эти представления уже один раз “посмотрели друг на друга”. Понятно, что формально это новый вход, и выход будет тоже другой, но это и интуитивно имеет смысл.
, результат первого прохода, в котором эти представления уже один раз “посмотрели друг на друга”. Понятно, что формально это новый вход, и выход будет тоже другой, но это и интуитивно имеет смысл. 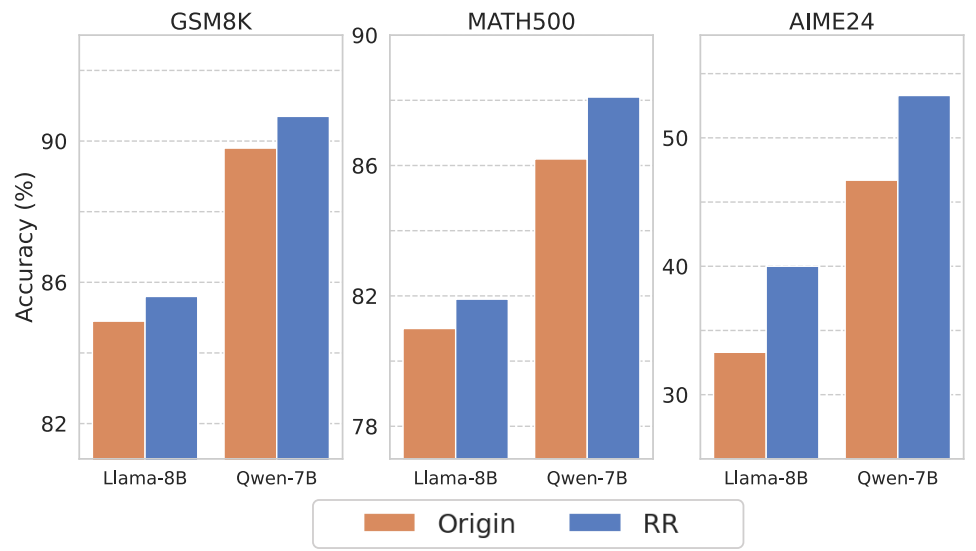










")















")
")
")























")
")
")








































")













 0-20 screenshot")
 0-47 screenshot")
 0-55 screenshot")
 0-56 screenshot")
 1-2 screenshot")
 1-7 screenshot")
 2-16 screenshot")
 2-36 screenshot")
 3-32 screenshot")
 3-35 screenshot")
 3-37 screenshot")
 3-56 screenshot")
 2-17-29 screenshot")
 2-17-33 screenshot")
 2-17-37 screenshot")
 2-17-41 screenshot")
 2-17-43 screenshot")
 2-17-46 screenshot")
 2-17-46 screenshot (1)")
 2-11-30 screenshot")
 24-11 screenshot")
 2-0-42 screenshot")
 34-31 screenshot")
 1-25-2 screenshot")












 (No Commentary, 100%) 5-52 screenshot")
 (No Commentary, 100%) 5-57 screenshot")
 (No Commentary, 100%) 5-55 screenshot")
 (No Commentary, 100%) 5-59 screenshot")
 (No Commentary, 100%) 6-19 screenshot")
 (No Commentary, 100%) 6-25 screenshot")
 (No Commentary, 100%) 6-28 screenshot")
 (No Commentary, 100%) 6-37 screenshot")





































































