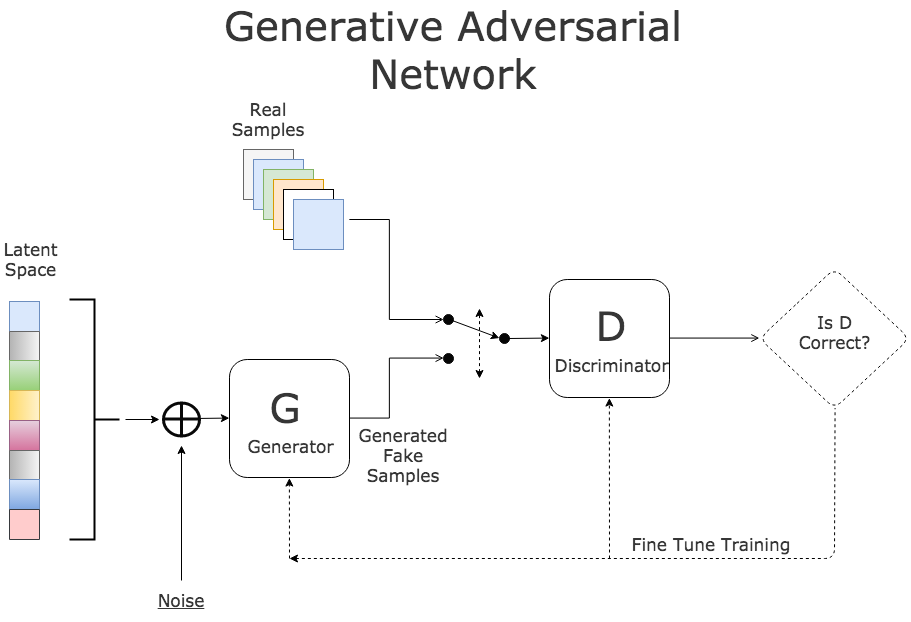
Where and how do people already use medical diagnostic systems based on AI algorithms?
Medical diagnostics is a very interesting case from the point of view of AI.
Indeed, medical tests and medical images are data where one is highly tempted to train some kind of machine learning model. One of the first truly successful applications of AI back in the 1970s was, actually, medical diagnostics: the rule-based expert system MYCIN aggregated the knowledge of real doctors and learned to diagnose from blood tests better than an average doctor.
But even this direct application has its problems. Often a correct diagnosis must not only analyze the data from tests/images but also use some additional information which is hard to formalize. For example, the same lesion on the X-ray of the lungs of a senior chain smoker and a ten-year-old kid is likely to mean two very different things. Theoretically we could train models that make use of this additional information but the training datasets don’t have it, and the model cannot ask an X-ray how many packs it goes through every day.
This is an intermediate case: you do have an image but it is often insufficient. True full-scale diagnostics is even harder: no neural network will be able to ask questions about your history that are most relevant for this case, process your answers to find out relevant facts, ask questions in such a way that the patient would answer truthfully and completely… This is a field where machine learning models are simply no match to biological neural networks in the doctors’ heads.
But, naturally, a human doctor can still make use of a diagnostic system. Nobody can remember and easily extract from memory the detailed symptoms of all diseases in the world. An AI model can help propose possible diagnoses, evaluate their probabilities, show which symptoms fit a given diagnosis or not, and so on.
Thus, despite the hard cases, I personally think that the medical community (including, medical insurance companies, courts, and so on) is being overly cautious in this case. I believe that most doctors would improve their results by using automated diagnostic systems, even at the current stage of AI development. And we should compare them not with some abstract idealized notion of “almost perfect” diagnostic accuracy but with real results produced by live people; I think it would be a much more optimistic outlook.
Is there a difference for a neural network between recognizing a human face on a photo and recognizing a tumor with a tomogram?
Indeed, many problems in medicine look very similar to computer vision tasks, and there is a large and ever growing field of machine learning for medical imaging. The models in that field are often very similar to regular computer vision but sometimes differences do arise.
A lot depends on the nature of the data. For instance, distinguishing between a melanoma and a birthmark given a photo of a skin area is exactly a computer vision problem, and we probably won’t have to develop completely novel models to solve it.
But while many kinds of medical data have spatial structure, they may be more complex than regular photos. For instance, I was involved in a project that processed imaging mass-spectrometry (IMS) datasets. IMS processes a section of tissue (e.g., from a tumor) and produces data which is at first glance similar to an image: it consists of spatially distributed pixels. But every “pixel” contains not one or three numbers, like a photo, but a long and diverse spectrum with thousands of different numbers corresponding to different substances found at this pixel. As a result, although this “data cube’’ has clear spatial structure, classical computer vision models designed for photos are not enough, we have to develop new methods.
What about CT and MRI scans? Will the systems that process them “outcompete” roentgenologists whose job is also to read the scans?
This field has always, since at least the 1990s, been a central application and one of the primary motivations for developing computer vision models.
Nowadays, such systems, together with the rest of computer vision, have almost completely migrated to convolutional neural networks (CNN); with the deep learning revolution CNNs have become the main tool to process any kind of images, medical included. Unfortunately, a detailed survey of this field would be too large to fit on the margins of this interview: e.g., a survey released in February 2017 contains more than 300 references, most of which appeared in 2016 and later — and a whole year has passed since…
Should the doctors be afraid that “the machine” will replace them? Why or why not?
It is still a very long way to go before AI models are able to fully replace human doctors even in individual medical specialties. To continue the above example, there already exist computer vision models that can tell a melanoma apart from a moleno worse or even better than an average doctor. But the real problem is usually not to differentiate pictures but to persuade a person to actually come in for a checkup (automated or not) and to make the checkup sufficiently thorough. It is easy to take a picture of a suspicious mark on your arm, but you will never notice a melanoma, e.g., in the middle of your back; live doctors are still as needed as ever to do the checkup. But a model that would even slightly reduce the error rate is still absolutely relevand and necessary, it will save people’s lives.
A similar situation has been arising in surgery lately. Over the last couple of years, we have seen a lot of news stories about robotic surgeons that cut flesh more accurately, do less damage, and stitch up better than humans. But it is equally obvious that for many years to come, these robots will not replace live surgeons but will only help them save more lives, even if the robots learn to perform an operation from start to finish. It is no secret that modern autopilots can perform virtually the entire flight from start to finish-but it doesn’t mean human pilots are moving out of the cabin anytime soon.
Machine learning models and systems will help doctors diagnose faster and more accurately, but now, while strong AI has not yet been created, they definitely cannot fully replace human doctors. There is no competition, only development of useful tools. Medicine is a very imprecise business, and there always are plenty of factors that an automated system simply cannot know about. We are always talking only about computer-aided diagnosis (CAD), not full automation.
What are the leading companies in Russia that drive the innovations in biomedical AI?
One company that does very serious research in Russia is Insilico Medicine, one of the world leaders in the development of anti-aging drugs and generally in the field of drug discovery with AI models. Latest results by Insilico include models that learn to generate molecules with given properties. Naturally, such models cannot replace clinical trials but they can narrow down the search from a huge number of all possible molecules and thus significantly speed up the work of “real” doctors.
Here at Neuromation, we are also starting projects in biomedical AI, especially in fields related to computer vision. For instance, one of our projects is to develop smart cameras that will track sleeping infants and check whether they are all right, whether they are sleeping in a safe position, and so on. It is still too early to talk about several other projects, they are still at a very early stage, but we are certain something interesting will come out of them very soon. Biomedical applications are one of the main directions of our future development; follow our news!
This is a translation of Sergey Nikolenko’s interview by Anna Khoruzhaya; see the Russian original on the NeuroNews website.