На новый 2026 год я сделал в канале “Sinекура” небольшой проект 12 Games of Christmas: 12 дней, 12 маленьких игр, 12 обзоров. Выкладываю в блоге эти обзоры тоже, в виде трёх статей по четыре игры; собрал их не хронологически, а по смыслу.
Сегодня третья, заключительная часть: хорроры и игры, вызывающие эмоции. Четыре раздела (а игр гораздо больше!): игры Евгения Зубко Press Any Button и Knight of the Lions, антология Violent Horror Stories (V.H.S.), The Lightkeeper и игры студии Playables (Time Flies, Plug & Play и другие).
tl;dr: если первая из этих игр не заставит вас плакать, запустите вторую
Press Any Button мне рекомендовал Сергей Янукович; сказал, что его проняло. И действительно, это крутая история. Занимает меньше часа, геймплей там есть (простой, но довольно любопытный), но главное не в геймплее, а в сюжете. Вы якобы проходите тест, который устраивает для вас искусственный интеллект, и этот искусственный интеллект в процессе теста начинает рассказывать свою историю. Спойлерить не буду, просто поиграйте, много времени это не займёт.
Когда мне понравилась Press Any Button, я, естественно, зашёл посмотреть, кто её сделал. Оказалось, что это инди-разработчик Евгений Зубко, и у него буквально в 2025-м вышла новая игра: Knight of the Lions. Разумеется, её я тоже попробовал.
Визуальный стиль вы видите на скриншотах, он очень крутой, и выдержан по всей игре безупречно. По жанру Knight of the Lions — это платформер, причём там (несколько неожиданно) платформинг нестандартный и интересный: способности вроде прыжка вы получаете на небольшое время, и за это время надо успеть ими воспользоваться. Пожалуй, получилось даже немного слишком сложно, учитывая, что не геймплей здесь главное. Впрочем, за два часа справился даже криворукий я.
Но дело тут, конечно, не в геймплее, а в истории. И про сюжет Knight of the Lions я вам вообще ничего не скажу. Просто скажу, что играть надо обязательно всем. Я не так часто могу по-настоящему заплакать над игрой или фильмом, но здесь именно тот случай…
tl;dr: четыре симпатичных хоррора, а ещё есть вторая часть…
И снова даже в рамках “игры на один день” приходится говорить про сразу несколько игр; антология представляет собой интерфейс с “видеокассетами” для выбора мини-хорроров. Поэтому о каждой игре очень кратко; сразу скажу, что разрабатывали в основном наши люди, так что во все игры лучше играть на русском языке.
I ate old man’s liver now this bitch is mine — сюрреалистическое творение польских авторов из Bober Bros (где-то я это название слышал, но в списке их игр вроде ничего знакомого). Польские-то польские, но вайб у игры чрезвычайно русский. Дед офигенный, смело включайте русский текст, там самая мякотка. Игра на 15 минут, но очень смешная.
Sensation — это, пожалуй, единственная игра, которая откровенно не понравилась. Хотели сделать квест-новеллу в японском духе, а получилось претенциозно и неинтересно.
All along the toon tower — игра-головоломка про перестановку комнат в стиле раннего Диснея с крутым вайбом. И шутеечки хорошие, и загадки вполне на уровне, и финал симпатичный. Конечно, с этими механиками можно было сделать ещё много чего, но и так неплохо вышло.
No, I’m not a human — а здесь разработчики как раз сделали “ещё много чего”, и об этой игре вы наверняка слышали, это один из громких инди-релизов прошлого года. В антологии, очевидно, ранняя и очень короткая версия, но и в неё тоже играть вполне интересно.
В целом антология мне весьма зашла, и я такой, очевидно, был не один, так что вскоре вышел и второй сборник, Violent Horror Stories 2. Его я тоже попробовал посмотреть, но там уже отдельного обзора писать не буду — игр в антологии уже гораздо больше, я позапускал несколько, и они в основном выглядели как приключения на несколько часов, но при этом они этих часов вряд ли заслуживали.
Down the Stairs — выделю только одну, как раз зарисовку минут на 10-15. Это игра, которая пытается показать жизнь человека с деменцией. Как мне кажется, зарисовка хорошая, за душу действительно берёт.
Надо будет попробовать As Long As You’re Here, там эта тема разработана явно глубже.
tl;dr: очень красивый и очень короткий кинематографичный хоррор
Я не люблю хорроры: мне страшно.) Особенно если со скримерами. Если нужно произведение с тяжёлыми эмоциями, я предпочту что-нибудь эмоциональное, где можно прослезиться от эмпатии, а не от избытка адреналина; такие игры в этом проекте уже были, кстати говоря.
The Lightkeeper — это очень классический хоррор. В нём всё собрано из банальностей: герой приезжает работать смотрителем маяка, но у него тёмное прошлое из первой мировой, а предыдущие три смотрителя умерли при странных обстоятельствах, а зловещие птицы кружат над мёртвыми сородичами… в общем, вы поняли. Скримеры здесь тоже есть в немаленьком количестве. Да ещё и визуал, кажется, целиком стащен у Роберта Эггерса.
Но как стащен! Просто посмотрите на скриншоты — это действительно очень красивая игра. Кинематографичная в хорошем смысле этого слова. Когда-то мне нравились хорроры от Supermassive Games (The Dark Pictures Anthology, я играл в три, кажется, из них) за их кинематографичный стиль и качество графики, но The Lightkeeper — это прямо следующий шаг, хоть и недорогое инди вроде бы.
История банальная, но неплохая, даже с твистом небольшим в конце. Особенно круто, что вся она разворачивается примерно за час; на такой срок её более чем хватает, игра держит в напряжении, нерв не пропадает. Задания простые, но не скучные, долго бегать и искать неизвестно что здесь не нужно, темп поддерживается высокий. В общем, мне очень понравилось; хотя подозреваю, что отчасти это потому, что рядом сидела и смотрела Ира. Вместе бояться куда веселее, это ещё котёнок по имени Гав отмечал.
Рекомендую The Lightkeeper и любителям хорроров, и нелюбителям вроде меня — потеряете максимум час-полтора, а вдруг понравится.
tl;dr: набор концептуальных зарисовок в общей стилистике
Швейцарская студия Playables выпускает даже не мини-, а микро-игры, и завершить 12 Games of Christmas хотелось как раз чем-нибудь этаким: набор внутри набора. Проекты все очень короткие, и у них в основном весьма похожая стилистика; собственно, вы всё видите на скриншотах. Но оказалось, что это всё-таки довольно разные игры.
Time Flies — это головоломка про муху. Ты вылетаешь в мир с bucket list’ом из абстрактных жизненных целей вроде “разбогатей”, “соверши революцию” или “найди Бога” — и должен успеть всё выполнить за одну короткую жизнь. Любопытная фишка в том, что время даётся в секундах, равных ожидаемой продолжительности жизни в выбранной стране: японская муха живёт 84,5 секунды, российская — 70, а какая-нибудь африканская и того меньше. Управление максимально простое: ты просто летаешь и врезаешься в предметы. Задачи интерпретируются буквально и с юмором: чтобы “совершить революцию”, надо проехать один круг (revolution) на грампластинке, чтобы “напиться” — найти каплю вина, чтобы “оставить след” — ну, вы поняли. Элегантное минималистичное высказывание, упакованное в двухчасовую игру.
А другие игры Playables, которые я успел попробовать — это даже и не игры, а скорее этакие интерактивные инсталляции. CARS — набор сценок о том, как машины падают в пропасть, следуют друг за другом, сталкиваются и тому подобное.
KIDS — по всей видимости, ровно то же самое (начало такое же, проходить не стал), но с фигурками людей, а не машин.
Plug & Play — концептуальная инсталляция о людях, у которых вместо головы электрическая вилка или, соответственно, розетка. С ними там периодически происходят очень концептуальные вещи. В общем, Playables: connecting people. Лично мне там очень понравился диалог где-то в середине игры.
Pocket Boss — забавная зарисовка о корпоративном буллшите. Суть почти всего, что там происходит, в том, что нужно взять график и привести его в нужный вид. При этом ты не меняешь ничего в собственно деятельности компании и каком бы то ни было “реальном мире”, а просто перетаскиваешь элементы гистограмм или других графиков так, чтобы они выглядели “хорошо”.
My Exercise — это буквально кликер, нужно просто нажимать на пробел и типа делать отжимания при этом. Но, конечно, процесс тренировки пресса обёрнут в кучу забавных анимаций со сценками про разных животных; я такие совсем уж пустые зарисовки не очень люблю, так что после первого же сета выключил, но то, что успел увидеть, сделано хорошо.
В итоге Time Flies и Plug & Play я точно рекомендую, а остальные под настроение. Но учитывая, что больше 15 минут ни одна из них (кроме Time Flies) не занимает, почему бы и нет. Лично мне очень нравится, что на свете есть люди, которые разрабатывают такие странные, но любопытные вещи.
Заключение
На этом проект 12 Games of Christmas заканчивается! Мне в целом понравилось, разве что, пожалуй, двенадцать — это чересчур. Но в целом маленькие игры, которые легко закончить за 1-2 дня — это мой любимый “жанр”. Так что в блоге будет ещё много обзоров мини-игр. Спасибо за внимание!
На новый 2026 год я сделал в канале “Sinекура” небольшой проект 12 Games of Christmas: 12 дней, 12 маленьких игр, 12 обзоров. Выкладываю в блоге эти обзоры тоже, в виде трёх статей по четыре игры; собрал их не хронологически, а по смыслу.
Сегодня вторая часть: головоломки и детективы. Обозреваем NODE: The Last Favor of the Antarii, Mind Diver, Éalú и The Trolley Solution.
tl;dr: компьютерная версия Roborally c отличным стилем позднего СССР и интересной историей
В знаменитой классической настолке Roborally вы управляете роботом, готовя для него рудиментарную программу из карточек с командами. Каждый игрок “пишет” программу своего робота втёмную, а потом все роботы начинают им следовать одновременно, мешая друг другу, с непредсказуемыми результатами. Фото для ясности прилагается:
Хотя у Roborally есть очевидные недостатки (очень затянуто, например), а сама идея безумно крутая, клонов и римейков Roborally в мире настолок совсем немного.
NODE — это буквально компьютерная версия Roborally. Ты управляешь роботом, выкладывая цепочку команд: ехать вперёд 3.4 секунды, развернуться, запустить интерактивный объект и так далее (механик не очень много, но они хорошо взаимодействуют). Когда нажал “пуск”, дальше уже ничего изменить нельзя. Загадки сделаны отлично — не затянуты, но и не тривиальны: почти каждая требует пару минут подумать, но не превращается в занудный перебор. Ну ладно, иногда превращается, потому что часто надо что-то подправить на три десятых секунды; но это здесь не душно.
В отличие от настолок, здесь ещё есть лор, стиль и история. И они тоже очень крутые! Дело происходит на секретной советской ядерной станции под названием “Тоска”, которую сделали ещё при Брежневе, а Андропов решил её законсервировать, переключив основные усилия на не такой секретный и куда более безопасный Чернобыль (да, шуточек про СССР здесь много). После Андропова прошло уже 50 лет, и вот что-то, кажется, пошло не так. Вы — маленький, но весьма разумный робот, который должен спасти человечество от ядерной зимы; на станции вы знакомитесь с разумной системой PRIZMA (СССР и в AI был впереди планеты всей!), с которой тоже надо наладить отношения. А потом появляется ещё много интересного…
Стиль крутейший, дух позднего СССР пойман безупречно; я очень удивился, когда в титрах оба соавтора игры из Lapsus Games оказались испанцами. История тоже не без твистов, которые я спойлерить, конечно, не буду. Игра получилась для меня на 5 часов, а не на 3 (хотя вроде не очень тупил), но не пожалел ни о секунде. Рекомендую!
tl;dr: детектив с погружением в чужую память и хорошими загадками
Эта игра понравилась. Суть её в том, что вы специально обученный дайвер, который исследует воспоминания и пытается разобраться в детективной истории, восстанавливая воспоминания её центрального персонажа.
Кажется очень банальным. И действительно, таких игр было много: Remember Me, Get Even, Observer, да хоть Psychonauts и серия Persona.
Но здесь это хорошо сделано! Сама история связана с той самой технологией погружения в память, но это было бы даже и не обязательно, обычный детективный сюжет тоже хорошо бы зашёл. Главное — хорошо сделанный детективный геймплей. Загадки состоят в том, чтобы подобрать нужный предмет на место “провала в памяти”, но методика “применить всё на всё” работает плохо, потому что предметов довольно много, и их часто нужно носить довольно далеко, а инвентаря как такового нет, предмет “в руках” только один. Так что поневоле приходится именно думать, разбираться в том, чего от тебя хотят — и оказывается, что хотят обычно довольно логичных, но не то чтобы совсем очевидных вещей. Хорошо настроен уровень сложности, в общем.
Основной минус на мой личный взгляд — визуальный стиль. Он здесь, честно говоря, вообще никакой: авторы вроде как и постарались сделать с выдумкой, типа чтобы производило впечатление, а получилось генерическое инди, в котором ещё и многое размыто и плохо видно. Но, может, это мой личный вкус, посмотрите скриншоты.
Зато мне понравилось, что там есть настоящие фотографии, и вообще артефакты, встречающиеся в игре, довольно разнообразны и работают на атмосферу: записки, газетные вырезки, личные вещи — всё это действительно добавляет объём.
В любом случае, это отличный дебют для маленькой инди-студии, причём такой дебют, который можно ещё развивать и развивать. Я бы точно попробовал и другие расследования в этой вселенной. Рекомендую.
tl;dr: плохо сделанный point-and-click квест с уникальной stop-motion анимацией
Проект начался сразу тремя отличными играми, но так не могло продолжаться бесконечно. Éalú — это квест про мышь в лабиринте. Главная его фишка в том, как это сделано: это настоящая stop-motion анимация. Авторы фотографировали реальную деревянную мышку, и все её приключения тоже были реализованы в реальности. По вайбу должно напоминать Neverhood и Harold Halibut, который я когда-то обозревал, но здесь, конечно, всё куда дешевле и неказистее.
И всё равно это сильная сторона проекта. Остальное скорее минусы. Загадки — классические головоломки, но их очень мало; понятно, что в реальной жизни делать такие вещи сложно, но за гуж ведь уже взялись. Большую часть времени ты проводишь в пустых коридорах, где ничего нет.
Игра заняла у меня около часа, и это было гораздо больше, чем надо. Мало того, что надо ходить по пустым коридорам с долгими анимациями; в дизайне игры есть и ещё один очень странный недостаток. Время от времени твою мышку что-то убивает; это симпатично сделано, посмотреть на это хочется, и даже есть дверь, которая откроется после 24 смертей (нет, я в неё не зашёл). Но после смерти… решённые пазлы возвращаются в исходное состояние! И их надо опять решать, что занимает существенное время, даже когда уже знаешь как. Уже это меня очень раздражало, а когда игра ещё и потребовала от меня фактически нарисовать карту своего лабиринта на бумажке (нужно было расставить пазлы на сетке), я плюнул и посмотрел в прохождение, о чём совершенно не жалею.
Удивляют меня две вещи. Во-первых, хорошие обзоры: Metacritic пока пустой, но вот, например. Как этой игре можно дать положительную рецензию, решительно не понимаю. Во-вторых, это внезапно ирландская игра. Там все тексты на ирландском (дублированы по-английски, конечно). Я понял, что ирландскую игру сделали ирландцы, но что ирландского в этой деревянной мышке и её нехитрых приключениях — решительно непонятно.
В общем, не рекомендую ни в каком виде; даже любопытный визуальный стиль проще и лучше будет посмотреть на youtube.
tl;dr: набор шутеек о вагонетках, иногда околофилософских, но скорее не очень
В 1967 году британский философ Филиппа Фут придумала всем известную дилемму вагонетки. Она это сделала как часть дискуссии об абортах в контексте доктрины двойного эффекта, восходящей ещё к Фоме Аквинскому. По этому принципу, можно совершать действия с хорошими и плохими (двойными) последствиями, если: (1) само действие морально хорошо или нейтрально, (2) плохой эффект не является средством для достижения хорошей цели, (3) намерение именно благое, а вред — побочный эффект, и (4) хорошее перевешивает плохое или по крайней мере соразмерно ему.
Например, как пишет нам даже не Филиппа Фут, а предисловие к её статье с введением в тему, доктрина двойного эффекта говорит, что было бы аморальным делать аборт для спасения жизни матери, потому что убивать невинного человека всегда плохо, даже с благой целью (условие 1), и убийство здесь является средством для спасения (условие 2). А вот если у беременной женщины обнаружили рак матки, то удалить матку вместе с плодом уже морально хорошо, ведь теперь цель именно в удалении опухоли, а не в убийстве (условие 1), а плод погибает как побочный эффект (условия 2 и 3). Автор предисловия подытоживает: “In this case, the woman is really lucky to have a cancerous uterus (rather than a pregnancy-related life-threatening condition)”. Понимаете логику? Я тоже не очень, и дальше проще не становится.
The Trolley Solution могла бы оказаться глубокой философской игрой, обучающей вас тому, что происходило в этике в последние полвека. Вы бы начали с классической проблемы вагонетки, получили ачивку “Utilitarianist” или “Deontologist” в зависимости от выбора (ровно так в игре и происходит), а потом начали бы углубляться в многочисленные разветвления этической философии, в которых тоже есть подобные примеры. Даже если бы в игре не было новых высказываний, это было бы отличное введение в тему, примерно как прекрасная игра Soma вводит в тему философских проблем сознания и опыта.
Но здесь, к сожалению или к счастью, ничего подобного нет. Это просто набор шутеек про вагонетки с возрастающим градусом абсурда. А ещё в The Trolley Solution куча пародий на самые разные жанры игр и не только игр. Здесь вы будете давить кота Шрёдингера, играть в раннер и визуальную новеллу, ездить на вагонетке от первого лица, выбирать между папой и мамой и всё такое прочее. И сама Филиппа Фут появляется. В общем, забавно, часа полтора покликать самое то, рекомендую.
На новый 2026 год я сделал в канале “Sinекура” небольшой проект 12 Games of Christmas: 12 дней, 12 маленьких игр, 12 обзоров. Выкладываю в блоге эти обзоры тоже, в виде трёх статей по четыре игры; собрал их не хронологически, а по смыслу.
tl;dr: Inside с транспортным средством и без головоломок
Вайб этой игры чертовски напоминает Limbo (по жанру и простоте) и Inside (по стилю и внешнему виду). Героиня живёт в постапокалиптическом мире с видом сбоку и движется слева направо. Мир сделан очень стильно и весь дышит запустением и распадом. Общая продолжительность — три часа, за которые вы доберётесь до правого края, где зажжёте факел надежды.
Главная новая деталь этой игры по сравнению с другими подобными — транспорт. Сухопутный корабль, который в игре называют “окомотивом” (крутое слово! студия-разработчик тоже называется Okomotive), сделан с любовью: есть двигатель, который надо кормить топливом (всяким подобранным по пути хламом), кнопка газа, парус для попутного ветра, тормоз и клапан для сброса пара. Бегаешь внутри, жмёшь кнопки, следишь за состоянием машины — поначалу это даже увлекательно.
Но мне здесь чего-то не хватает; точнее, ничего не хватает.) Во-первых, геймплей здесь подаёт большие надежды, но совершенно их не оправдывает. Физика честно работает, окомотив приятно скрипит и раскачивается, но все загадки сводятся к “найди красную кнопку” или “перетащи ящик”. Ни одна из механик не развивается: парус остаётся на уровне “подними, когда дует ветер”, топливо никогда не становится дефицитом, а препятствия на пути — это почти буквально “выйди, нажми рычаг, вернись”. А жаль, потому что физика реализована хорошо, и с этими вводными можно было бы сделать много интересного.
Во-вторых, очень не хватило сюжета. Нет ничего плохого в симуляторе ходьбы с нажиманием на кнопки и простенькими задачками с физикой. Но если в нём ещё и истории никакой не рассказывают, то что остаётся?.. А здесь нет буквально ничего, как в тех же Limbo и Inside: ты видишь пришедший в запустение мир, встречаешь разные индустриальные объекты и транспортные средства, понимаешь один бит семейной истории, поданный в форме пары картинок… и всё.
Но сделано действительно стильно и атмосферно. Если бы было всё то же самое, но ещё с записочками, рассказывающими что-нибудь интересное, была бы игра на 8 из 10. А так всё-таки скорее не понравилось.
tl;dr: очень красивый симулятор ходьбы с синдромом поиска глубинного смысла
Вы просыпаетесь неизвестно где, встречаете непонятно кого, и он проводит вас к таинственному Мастеру, который начинает переносить вас из одной сцены в другую. Сцены представляют собой вроде бы ваши собственные воспоминания, но это не точно. По крайней мере, начинаются они с детства, а потом… а потом какая-то тюрьма? корабль? война? И всё время комментарии Мастера, на которые вы отвечаете вроде бы даже впопад, но эти диалоги ровным счётом ничего не проясняют.
Caligo — это чистейший симулятор ходьбы длиной в час; его сделала красноярская студия Krealit, предыдущие игры которой носили заманчивые названия вроде Guns’n’Zombies. И вдруг Caligo, состоящий из нескольких статических сцен, через которые вы идёте, смотрите по сторонам и слушаете диалоги с Мастером. В диалогах прямо очень запущенный случай синдрома поиска глубинного смысла (СПГС): они написаны максимально расплывчато, буквально оптимизированы на то, чтобы их можно было интерпретировать как угодно. В общем, мне кажется, что если вам кажется, что вы что-то там поняли, то это вам кажется. И эти тексты ещё и озвучены плохо. Отсутствие внятной истории — главный минус игры.
Но Caligo можно многое простить за визуал. Столько скриншотов за час я ещё, наверное, никогда не делал. Несколько вот прилагаю, но поверьте, их было очень трудно выбрать. Визуальный стиль и проработка сцен здесь просто великолепные, действительно хочется гулять и рассматривать.
А за Бродского я вообще всё сразу простил. Поскольку я играл по-английски (не знал заранее, что Caligo наши люди делали), я даже не сразу узнал Иосифа Александровича. А потом как узнал. И значит, остались только иллюзия и дорога. Об этом и игра — но это не точно.
tl;dr: психоделический почти детектив про музыкантов
Игры про музыку и музыкантов почему-то всегда странненькие и психоделические. Вспоминается, например, грустный и красивый симулятор ходьбы The Forest Quartet, или смешной и безумный Jazzpunk (если вы не играли в Jazzpunk, рекомендую этот пробел восполнить, это интересный опыт). Но ещё больше эта игра похожа на Tales from Off-Peak City, которую я тоже очень даже рекомендую. Кстати, порадовался тому, что сначала сам вспомнил про Tales from Off-Peak City, а потом уже прочитал, что это игры от одной студии, которые происходят в одной вселенной.
The Norwood Suite не добирается до Jazzpunk’овского уровня high weirdness, но здесь тоже есть интересный психоделический визуал и слегка безумная история. Формально это детектив: ты приезжаешь в отель, сделанный из дома, где много лет назад пропал великий музыкант Питер Норвуд. Но его исчезновение расследовать не надо; нужно просто ходить по отелю, выполнять задания постояльцев, рассматривать разные закоулки и слушать странную музыку.
Рассматривать здесь очень даже есть что, скриншоты вот прилагаю. Как уже говорил, психоделично и симпатично. Загадок как таковых особо нет, посылают делать прямолинейные понятные вещи, а в награду дают возможность больше исследовать особняк. И отдельно, конечно, нужно сказать про музыку: она и правда интересная и разнообразная, хотя тут я совсем не специалист и вряд ли что-то могу оценить.
В общем, это хоть и не совсем симулятор ходьбы, но скорее такой визуальный и аудиальный опыт, чем игра с серьёзным геймплеем. И тем не менее, мне понравилось, как и Tales from Off-Peak City. Рекомендую к этой серии присмотреться.
tl;dr: красивое музыкальное инди во всех цветах радуги
В предыдущем обзоре я удивлялся, почему игры про музыкантов неизменно какие-то психоделические. Вселенная меня услышала, и следующая игра про музыканта в моём списке оказалась… ну ооочень психоделической.
Начну с истории, она тут интересная. The Artful Escape — это по сути проект одного человека, Johnny Galvatron (на самом деле Jonathan Mole, но, как он сам говорит, “с таким именем рок-н-ролл не сыграешь”). Он был фронтменом австралийской глэм-рок группы The Galvatrons, гастролировал по миру, возненавидел гастрольную жизнь и ушёл делать игру о той версии рок-н-ролла, которую представлял себе в 17 лет — с космосом, монстрами и бесконечным соло. Кикстартер провалился, но Annapurna увидела демо и на следующий день подписала договор.
На первый взгляд The Artful Escape выглядит как классическое инди в духе Annapurna Interactive. Шрифты и подача диалогов очень похожи на Oxenfree (да, я знаю, что они сами себя издавали), общая атмосфера напоминает Sayonara Wild Hearts и так далее. Но какие тут пейзажи! Инопланетные леса, гигантские светящиеся грибы, космические киты — посмотрите на скриншоты, я их тут очень много сделал.
Геймплей тоже обычный — симулятор ходьбы, разбавленный мини-ритм-игрой: периодически нужно повторять последовательности нот в музыкальных “баттлах” с инопланетными существами. Механика элементарная и никак не развивается, но и не мешает.
История — стандартный coming-of-age: парень живёт в тени знаменитого дяди, списанного с Боба Дилана фолк-музыканта, и должен найти собственный голос. Абсолютно предсказуемо, но космическое развитие добавляет безумия, шутейки в диалогах неплохие, а озвучка звёздная.
И всё-таки ещё раз вернёмся к главному: стиль у этой игры потрясающий, и не только в хорошем смысле. Всё это выглядит как если бы Дэвид Боуи поехал в Вудсток, там съел не тот кекс, а потом пересмотрел “Космическую одиссею” под Pink Floyd. Каждый пейзаж залит всеми цветами радуги, неоновыми, кислотными, переливающимися — и радужный спектр здесь, конечно же, тоже не случаен. Игра ведь по сути о том, как найти себя, и хотя в истории нет ничего кроме музыки, аллюзии тут довольно прозрачные.
В общем, если вас приложенные картинки радуют или хотя бы интригуют, рекомендую. Если нет, не стоит и пробовать, там вся игра такая.
Итак, 2025 год закончился, и я наконец-то собрался с духом написать большой обзор того, что произошло в мире искусственного интеллекта за этот год. Обзор получается большим, так что я решил разбить его на части — и сегодня начну с самого очевидного: больших языковых моделей и агентов на их основе.
Честно говоря, каждый из последних лет можно было бы назвать прорывным для AI. Но конкретные направления прорывов всё-таки меняются. Если 2023-й был годом ChatGPT и массового осознания того, что языковые модели — это серьёзно, а 2024-й — годом мультимодальности и первых робких шагов к рассуждениям, то 2025-й я бы однозначно назвал годом рассуждающих моделей. И это не просто маркетинговое слово — здесь действительно произошёл качественный скачок.
Давайте разбираться, что же случилось.
Большие рассуждающие модели
Если выбирать одну главную идею, определившую 2025 год, это безусловно large reasoning models — модели, которые умеют “взять паузу” и подумать перед тем, как ответить. OpenAI запустили этот тренд в конце 2024-го с серией o1, а затем началась гонка, кто первый сможет повторить результат OpenAI. Эту гонку выиграл китайский стартап DeepSeek со своей моделью R1 (DeepSeek-AI, январь 2025).
Сами модели
OpenAI был первым, DeepSeek — вторым, а дальше понеслось. Практически каждая крупная лаборатория выкатила свои рассуждающие модели, и за год успело смениться несколько поколений. Отмечу только самые последние:
Google запустил Gemini 3 Pro и Deep Think в ноябре 2025-го — это была первая модель, которая пробила барьер в 1500 Elo на LMArena (да, рейтинги постоянно меняются, но факт остаётся фактом);
Anthropic выпустил Claude 4.5 в трёх вариантах (Haiku, Sonnet, Opus) с сентября по ноябрь; Sonnet достиг 77.2% на SWE-bench Verified, что стало лучшим результатом для реальных программистских задач, и Claude 4.5 стал основой для Claude Code, о котором мы поговорим ниже;
OpenAI ответил в декабре моделью GPT-5.2 в трёх вариантах: Instant для быстрых ответов, Thinking для глубоких рассуждений и Pro для максимальной точности;
китайские лаборатории отстают, но не сильно: DeepSeek-V3.2 интегрировал рассуждения в работу с инструментами (tool use), а Qwen3-235B от Alibaba стал одной из лучших открытых MoE-моделей с 235 миллиардами параметров (22 миллиарда активных);
Meta выпустила Llama 4 с вариантами Scout и Maverick, а xAI с Grok-4.1 вышла в топ reasoning-лидербордов, хотя здесь я, признаться, куда более скептично настроен.
Что объединяет все эти модели? У них есть режим chain-of-thought, при котором модели выдают секретный “блокнотик” (scratchpad, так и называется), куда можно писать токены, которые будут использоваться только для рассуждений и потом не станут частью собственно ответа для пользователя.
Такой подход идеально укладывается в схему обучения с подкреплением: теперь у модели есть “промежуточные ходы” (токены рассуждения), за которые она не получает награду, а собственно сигнал приходит только с “результатом партии” (окончательным ответом модели):
Оказалось, что эта простая идея действительно способна сделать модели существенно “умнее” (пока в кавычках, но скорее по привычке, честно говоря).
Обычно это буквально слайдер, регулирующий, сколько можно подумать перед ответом. GPT-5.2, например, сам может решить, нужно ли запускать chain-of-thought и сколько токенов на это потратить. На простых задачах ответ приходит за секунды, на сложных — модель может думать десятки секунд, а то и минут, но зато выдаёт более точный результат.
Как это работает: RLVR
За большинством рассуждающих моделей стоит техника под названием reinforcement learning with verifiable rewards (RLVR, обучение с подкреплением с верифицируемыми наградами). Это буквально указанная выше схема; разница только в том, что если ваша задача подходит для RLVR, это значит, что награду вы можете вычислить автоматически (например, проверить ответ на математическую задачу), а не полагаться на экстраполяцию человеческих предпочтений, как в RLHF:
Эту ключевую идею хорошо объяснил, например, Андрей Карпатый в своём обзоре «2025 LLM Year in Review»: если обучать LLM на задачах с автоматически проверяемыми ответами (математика, код, головоломки), модели спонтанно развивают стратегии, которые выглядят как рассуждения.
Они учатся разбивать задачу на промежуточные шаги, проверять себя, возвращаться и пробовать по-другому. Никто не задаёт это явно в структуре модели или обучающей выборки — это emergent behaviour, поведение, возникающее само собой. И оказалось, что RLVR даёт отличное соотношение прироста результатов на потраченный доллар. Карпатый отмечает, что это, возможно, главный тренд 2025-го: вместо того чтобы тратить весь вычислительный бюджет на pretraining, его стали эффективнее использовать для обучения рассуждениям.
Рассуждения естественным образом приводят к идее test-time compute scaling: если дать модели больше “времени на подумать”, результаты улучшаются. Раньше в машинном обучении было мало примеров, когда можно эффективно обменять вычисления во время применения модели (inference) на качество результата. Теперь это умеет каждая frontier LLM.
Но об этом — чуть позже, в отдельном разделе. Сначала давайте посмотрим на самые впечатляющие результаты.
Математика и программирование: золотые медали
RLVR особенно хорошо работает в областях, где решения можно проверить автоматически. И здесь 2025-й принёс просто фантастические результаты.
Отмечу только, что подход Google с Gemini Deep Think особенно интересен. В отличие от прошлогодних AlphaProof и AlphaGeometry, которые требовали перевода задач в формальные языки вроде Lean, Deep Think работает end-to-end на естественном языке. Он читает условие задачи и выдаёт строгое математическое доказательство напрямую. Ключевая инновация — параллельное обдумывание (parallel thinking): модель одновременно исследует несколько стратегий решения и комбинирует их, вместо того чтобы идти по одной линейной цепочке рассуждений.
OpenAI достигли такого же результата с минимальной IMO-специфичной подготовкой — по их словам, это в основном general-purpose RL и test-time compute scaling.
А главной новостью конца года в этом направлении стало то, что DeepSeek выложил в открытый доступ DeepSeek-Math-V2 — первую открытую модель уровня золотой медали IMO (Shao et al., ноябрь 2025). Она решила 5 из 6 задач IMO 2025 (как и модели OpenAI и Google) и набрала почти идеальные 118/120 на Putnam 2024, превзойдя лучший человеческий результат в 90 баллов.
Инновация DeepSeek — self-verification framework: специальный верификатор оценивает строгость и полноту доказательств, которые порождает proof generator, имитируя процесс самопроверки у математиков-людей. Результаты растут с числом итераций самопроверки:
Олимпиады по программированию
Революция затронула и соревновательное программирование. В сентябре и OpenAI, и Google показали сильные результаты на International Collegiate Programming Contest (ICPC) — на новых, ранее не публиковавшихся задачах. Об олимпиадах по программированию я рассказывал в посте “ICPC, IMC и Максим Туревский“; про результаты AI-моделей там, правда, почти ничего не было, ну да и ладно.
DeepSeek-V3.2 собрал целую коллекцию, особенно впечатляющую, учитывая, что это открытая модель:
IMO 2025: золотая медаль (35/42),
IOI 2025: золотая медаль (492/600, 10-е место),
ICPC World Finals: второе место (10/12 задач),
CMO 2025: золотая медаль.
Можно, конечно, сказать, что это показывает, как open-source модели способны реально конкурировать с проприетарными в специализированных задачах… Но, если честно, это всё-таки соревнования, то есть бенчмарки с придуманными людьми задачами и известными решениями. А что насчёт “настоящей” математики — доказательства новых теорем? Об этом мы поговорим в следующих частях обзора, а пока вернёмся к LLM.
Reasoning + Tools = Agents
Настоящая сила рассуждающих моделей проявляется, когда их соединяют с инструментами (tools). Если модель умеет вызывать API, запускать код, искать в интернете — она превращается в автономного агента, который разбивает задачу на подзадачи, выполняет их и итерируется до результата.
Model Context Protocol
Model Context Protocol (MCP), который Anthropic выпустил в ноябре 2024-го, в 2025-м получил массовое принятие индустрией. OpenAI присоединился в марте, Microsoft и GitHub вошли в steering committee в мае, а в декабре протокол был передан в Linux Foundation’s Agentic AI Foundation (совместно основанный Anthropic, Block и OpenAI при поддержке Google, Microsoft, AWS и других).
К концу года у MCP было уже под сто миллионов загрузок SDK в месяц, тысячи серверов и 75+ коннекторов в одном только Claude. Иллюстрацию ниже я взял из поста подкаста Latent Space, авторы которого гордились тем, как предсказали успех MCP ещё в марте:
MCP даёт стандарт того, как AI-агенты взаимодействуют с внешними инструментами, превращая их из моделей, которые умеют только работать с текстом, в полноценных ассистентов, способных сделать практически всё, что можно сделать за компьютером.
Computer use
Кстати, о компьютерах. Возможности работы ведущих моделей с компьютером (то есть их способность управлять вашим десктопом за вас, выполняя при этом полезную работу) выросли за прошедший год очень сильно. Результаты Claude на OSWorld (бенчмарк для автоматизации десктопа) выросли с 14.9% до 61.4% за год — это уже близко к человеческому уровню, составляющему 70-75%.
OpenAI Operator, запущенный в январе 2025-го как research preview и интегрированный в ChatGPT к июлю, уже сотрудничает с DoorDash, Instacart, Uber и другими сервисами для выполнения реальных задач.
Coding agents
Но, пожалуй, самое важное применение для LLM-агентов пока — это программирование. Здесь понятно, куда масштабироваться, и относительно легко проверять результаты.
Знаменитый график METR с “горизонтом выполнимых задач” теперь показывает Claude Opus 4.5 на первом месте, с задачами длительностью почти 5 часов, выполняемыми с 50% точностью. Это, честно говоря, уже очень близко к полной замене человеческих программистов (да, конечно, ещё не совсем там, но всё же):
Как был достигнут этот прогресс? Начну с нескольких интересных академических работ.
ReTool (Feng et al., апрель 2025) показал, что при помощи RL модели могут научиться, когда и как вызывать интерпретаторы кода во время рассуждений — и это способность, которую обычное обучение с учителем дать не может. Они используют слегка модифицированный алгоритм PPO, изменённый так, чтобы лучше отражать внутренние рассуждения:
Что особенно интересно, модель в результате демонстрирует эмерджентные метакогнитивные способности (emergent metacognitive capabilities): она учится распознавать ошибки в коде по сообщениям интерпретатора, рефлексирует на естественном языке (“Oops, the functions need to be defined in the same scope”) и порождает исправленные версии. Такой “code self-correction” никогда не была явно обучена — она возникает из outcome-driven RL.
Метод Search-R1 (Jin et al., март 2025) применил похожие принципы к веб-поиску, обучая LLM автономно формулировать запросы во время многошаговых рассуждений с real-time retrieval. В отличие от RAG, который ищет один раз и надеется на лучшее, Search-R1 учится искать итеративно, уточняя запросы на основе найденного. Ключевая техническая новизна здесь — это retrieved token masking, т.е. исключение retrieved content из функции ошибки RL для того, чтобы предотвратить нежелательные эффекты в обучении. Результат — улучшение на 24% над RAG baselines на QA-бенчмарках.
Другой концептуальный прорыв был сделан в работе “Thinking vs. Doing” (Shen et al., июнь 2025), которая утверждает, что для интерактивных агентов “test-time compute” должен включать не только более длинные reasoning traces, но и больше шагов взаимодействия с окружением:
Взаимодействие с окружением позволяет агентам получать новую информацию, исследовать альтернативы, откатываться назад и динамически перепланировать; всё это те возможности, которых никакие внутренние рассуждения дать не могут. В результате этот подход под названием TTI (Test-Time Interaction) достигает лучших результатов на WebVoyager (64.8%) и WebArena (26.1%) с моделью Gemma 12B, существенно превосходя агентов, обученных традиционными подходами.
Нерешённые проблемы
Впрочем, нерешённых проблем тоже ещё много. Например, новый бенчмарк τ²-Bench (Barres et al., июнь 2025) ввёл новую постановку задачи, важную для оценки именно агентных систем: dual-control environments, где могут действовать и агент, и пользователь, как в реальных сценариях. Другие бенчмарки предполагают, что пользователь — это пассивный источник информации, но τ²-Bench моделирует более реалистичный случай, когда агенты должны направлять пользователей делать что-то, а пользователи выполняют эти действия на своих устройствах, как в реальной техподдержке:
И результаты отрезвляющие: state-of-the-art LLM показывают падение на 18-25% при переходе от автономного режима к коллаборативному. Коммуникация и координация с людьми пока остаются слабыми местами существующих LLM-агентов.
Claude Code
На практике же главным агентским релизом 2025 года, несомненно, стал Claude Code. Он работает прямо в терминале, понимает вашу кодовую базу через поиск, может переписывать сразу несколько файлов, самостоятельно переключая контекст и понимая задачу в целом, а также может запускать сразу несколько агентов, выполняющих свои задачи:
Как выразился Карпатый в том же посте, это “маленькое привидение, которое живёт в вашем компьютере” (кажется, ещё совсем недавно мы бы вряд ли были рады такому описанию).
В отличие от традиционных LLM for coding, которые пишут код и показывают его человеку, Claude Code может действовать более автономно; он запускает команды, создаёт pull requests, работает с git и так далее.
А человеку остаётся только разговаривать с интерфейсом Claude Code на естественном языке. И, кстати, пользователи соглашаются, что Claude Code лучше всего работает, когда к нему относятся как к джуниору с инструментами, памятью и способностью сделать несколько подходов к задаче.
И Claude Code — это не только программирование. Пользователи используют его для подготовки налоговых деклараций по анализу банковских выписок, бронирования билетов в театр по проверке календаря, обработки бизнес-документов. “Code” в названии продаёт продукт ниже его возможностей: это LLM-агент общего назначения, который может делать почти что угодно на вашем компьютере, используя код как интерфейс к другим задачам; см., например, свежий обзор Zvi Mowshowitz.
Я рассказывал о Claude Code, но это просто лучшее на данный момент предложение среди многих. Например, модели семейства GPT-Codex от OpenAI (например, GPT-5.1-Codex-Max) тоже отлично справляются с автономным программированием.
Мне кажется, что 2026-й станет годом, когда агенты для использования браузеров и компьютеров в целом прочно войдут в нашу обычную жизнь. CoWork от Anthropic, только что анонсированный как research preview, вполне может стать первой по-настоящему важной AI-новостью 2026 года.
Законы масштабирования для test-time compute и не только
Я упоминал test-time compute scaling в начале: рассуждающие модели могут становиться лучше безо всякого дообучения, просто подумав побольше, и этот эффект заслуживает отдельного обсуждения. В 2025-м появились важные исследования о том, как эффективно масштабировать inference compute — и оказалось, что однозначного ответа нет.
Нет оптимальной стратегии, а маленькие модели могут обойти большие
Авторы “The Art of Scaling Test-Time Compute” (Agarwal et al., декабрь 2025) провели первое масштабное систематическое сравнение стратегий test-time scaling, сгенерировав более 30 миллиардов токенов на восьми open-source моделях.
Главный их вывод был в том, что никакая одна стратегия не доминирует во всех случаях. Оптимальный подход существенно зависит от типа модели и вычислительного бюджета. Авторы вводят важное различие между:
моделями с коротким горизонтом (short-horizon), которые выигрывают от более коротких reasoning traces независимо от сложности; такие модели часто обучены через GRPO;
моделями с длинным горизонтом (long-horizon), которые выигрывают от долгих рассуждений на сложных задачах; они часто обучаются другими RL-методами вроде GSPO.
На практике это значит, что выбор между majority voting, beam search и “first finish search” должен учитывать, к какой категории относится ваша модель.
Ещё одна интересная демонстрация compute-optimal inference была дана в работе “Can 1B LLM Surpass 405B LLM?” (Liu et al., февраль 2025). Ответ на титульный вопрос получился утвердительным: с правильной стратегией test-time scaling, 1B-модель может превзойти 405B-модель на MATH-500, а 7B-модель может побить и o1, и DeepSeek-R1 на AIME2024.
Ключевой инсайт здесь в том, что оптимальный метод масштабирования зависит и от размера модели (search-based для маленьких, Best-of-N для больших), и от сложности задачи. Предложенные compute-optimal стратегии могут оказаться в 256 раз более эффективными, чем простое голосование. Это говорит нам, что в будущем, возможно, мы сможем использовать и маленькие, более эффективно масштабируемые модели вместо того, чтобы просто автоматически выбирать самую большую модель из возможных.
Куда тратить вычислительный бюджет?
Все эти разговоры на практике нужны для того, чтобы решить, куда тратить ограниченный вычислительный бюджет. И об этом тоже было несколько работ с неожиданными результатами, а точнее, частенько даже с неожиданной постановкой вопроса (“а что, так можно было?”).
Так, например, метод GenPRM (Zhao et al., апрель 2025) показал, что сами process reward models можно масштабировать во время inference. Авторы переформулируют верификацию как задачу для рассуждений с явным chain-of-thought и строят модель GenPRM-7B, которая превосходит Qwen2.5-Math-PRM-72B на соответствующих бенчмарках, будучи в 10 раз меньше.
Но тут же это направление поставили под вопрос: когда выгоднее направлять compute на порождение, а когда на верификацию? Этот вопрос был поставлен в работе “When To Solve, When To Verify” (Singhi et al., апрель 2025). Несколько контринтуитивно оказалось, что стратегия Self-Consistency (порождение многих решений и выбор голосованием) превосходит Generative Reward Models (GenRM) при практических значениях вычислительных бюджетов. GenRM требует примерно 8x больше compute, чтобы просто сравняться с Self-Consistency, и 128x больше для скромного улучшения на 3.8%:
Это говорит о том, что в большинстве практических случаев масштабирование путём порождения большого числа решений остаётся эффективнее, чем инвестиции в более умную верификацию, хотя баланс смещается для очень сложных задач.
А работа “S*: Test Time Scaling for Code Generation” (Li et al., февраль 2025) представила первый гибридный test-time scaling framework специально для кода. Поскольку для кода можно проводить автоматическую программную верификацию, можно попробовать двухэтапный подход:
сначала порождать множество решений с итеративной отладкой по выполнению тестов, а затем
выбирать лучшее через adaptive input synthesis, т.е. просить LLM порождать тесты, различающие каждую пару возможных решений.
Любопытно, что стратегия S* позволяет instruction-based моделям приближаться к и даже превосходить reasoning models, что говорит о том, что хорошие стратегии во время inference могут заменить дорогое обучение рассуждениям.
Это, кстати, тоже пока ещё общее место, не раз подтверждавшееся в 2025 году: часто оказывается, что можно сделать хорошую дистилляцию из большой (скорее всего рассуждающей) модели и получить маленькую модель, которая даёт хорошие (в своём классе) результаты без всяких рассуждений. Посмотрим, изменит ли 2026-й это положение дел.
Новые архитектуры
Вполне возможно, что мы увидим, как в 2026-м трансформеры если не заменятся, то хотя бы дополнятся другими архитектурами. И здесь, конечно, надо писать отдельный пост, а то и несколько.
К счастью, я уже написал почти все эти посты, так что просто назову три направления, которые кажутся мне самыми перспективными на данный момент:
диффузионные LLM; введение в диффузионные модели когда-то было в моём блоге, но, конечно, оно уже безнадёжно устарело; про новые результаты в диффузионках мы поговорим в другой части обзора, а здесь просто упомяну, что в 2025-м давно уже существовавшие диффузионные языковые модели (Li et al., 2022) наконец-то начали масштабироваться в виде LLaDA (Large Language Diffusion Models; Nie et al., 2025).
В общем, нейросетевые архитектуры не стоят на месте, и новые идеи всё время появляются, но много писать я о них в этом посте не буду.
Разное
В заключительной части просто упомяну несколько других статей, которые показались мне любопытными.
Действительно ли RL улучшает reasoning?
“Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?” (Yue et al., апрель 2025). Эта статья, вышедшая на NeurIPS 2025, ставит под вопрос предположения, лежащие в основе рассуждающих моделей в целом.
Используя pass@k при больших k для оценки границ возможностей рассуждающих моделей, авторы систематически демонстрируют, что хотя RLVR улучшает точность (pass@1) в среднем, базовые модели устойчиво достигают более широкого reasoning coverage при высоких k, т.е. если породить кучу ответов и выбрать лучший.
Это подтверждается на многих бенчмарках (MATH500, AIME24, LiveCodeBench и других), семействах моделей (7B-32B) и RL алгоритмах (PPO, GRPO, Reinforce++, RLOO, ReMax, DAPO). RL для маленьких k, конечно, побеждает, но графики неизбежно пересекаются в какой-то точке:
Анализ, проведённый в этой работе, подтверждает, что те цепочки рассуждений, которые появляются после RLVR, на самом деле уже есть и в распределении базовой модели — модель просто учится сэмплировать их эффективнее. А новых способностей, получается, и не появляется!..
С другой стороны, дистилляция от более сильных моделей-учителей действительно может расширить границы возможного и дать новые рассуждения, которых раньше модель проводить не умела.
Всё это говорит о том, что текущие методы RLVR функционируют скорее как способы более эффективного сэмплирования из распределения возможных рассуждений базовой модели, чем как реальные улучшения способностей к этим рассуждениям. Это важно для того, чтобы понимать и потенциал, и пределы возможностей рассуждающих моделей.
Когнитивные паттерны для самостоятельного улучшения
“Cognitive Behaviors that Enable Self-Improving Reasoners” (Gandhi et al., март 2025) даёт механистическое объяснение того, почему одни модели существенно улучшают себя после применения RL-дообучения, а другие выходят на плато.
Авторы выделяют четыре ключевых когнитивных поведения — verification, backtracking, subgoal setting и backward chaining — которые соответствуют стратегиям, которые люди-эксперты применяют для решения задач. Модели, естественно демонстрирующие эти поведения (например, Qwen-2.5-3B), достигают 60% accuracy на Countdown benchmark после RL-дообучения, тогда как модели без них (например, Llama-3.2-3B) выходят на плато в 30% при идентичных условиях.
Самый поразительный результат здесь в том, что если дать модели неправильные решения, которые всё-таки демонстрируют правильные паттерны размышлений, этого будет достаточно, чтобы их качество работы сравнялось с моделями, обученными на правильных решениях.
То есть важен на самом деле доступ к правильным когнитивным паттернам, а не к правильным ответам. Это важно и на практике, для подготовки датасетов, и, честно говоря, философски очень интересно.
Gated Attention
“Gated Attention for LLMs” (Qiu et al., сентябрь 2025) — важный (и очень практический) результат, получивший Best Paper award на NeurIPS 2025; это та архитектурная работа, мимо которой всё-таки не пройти. Авторы добавляют простой sigmoid gating mechanism к выходу каждой головы внимания.
Авторы протестировали более 30 вариаций и сошлись на одной, которая устойчиво улучшала результаты:
Теоретический инсайт здесь в том, что гейт добавляет небольшую нелинейность внутри обычного механизма внимания, который так-то является в основном линейной операцией (не считая softmax-нормализации). Эта нелинейность помогает избежать проблемы “attention sink”, когда несколько токенов доминируют в головах внимания и, как следствие, в градиентах. Кроме того, это улучшает работу с длинным контекстом, позволяя моделям лучше экстраполировать свою работу на контекст длиннее, чем они видели при обучении.
Тот факт, что эта идея была немедленно использована в реальном семействе фронтирных LLM — Qwen-3 от Alibaba уже используют gated attention — доказывает практическую ценность работы и показывает, что академические результаты отнюдь не бесполезны на практике даже в нашу эпоху закрытых гигантских LLM.
Заключение
Итак, что мы имеем по итогам 2025 года в области больших языковых моделей?
Во-первых, reasoning models — это реально. Это не маркетинг и не хайп. RLVR действительно работает (хотя есть и интересные возражения), модели действительно научились “думать” (пусть пока в кавычках), и это приводит к качественному скачку на задачах, требующих многошаговых рассуждений. Золотые медали на IMO и ICPC — это уже не просто красивые цифры для пресс-релизов, а ещё более убедительную демонстрацию прогресса я, пожалуй, отложу до раздела об AI в науке.
Во-вторых, test-time compute scaling стал новым измерением оптимизации. Раньше мы в основном думали о том, как масштабировать обучение. Теперь inference тоже можно масштабировать, причём часто это оказывается эффективнее. Маленькие модели с правильным test-time scaling могут обойти модели в сотни раз больше.
В-третьих, LLM-агенты наконец-то начали работать на практике. MCP стандартизировал взаимодействие с инструментами, computer use приблизился к человеческому уровню, а Claude Code вывел автономных агентов на новый уровень, причём не только в программировании. METR-график с 5-часовыми решаемыми задачами уже сегодня выглядит пугающе для тех, кто зарабатывает программированием — а что будет ещё через год?
В-четвёртых, открытые модели отстают совсем не так уж сильно. DeepSeek продолжает показывать, что open source модели могут конкурировать с лучшими проприетарными, по крайней мере в специализированных задачах; но их “специализация” — это математические рассуждения, что совсем не так уж узко.
Что дальше? Мне кажется, что даже если новых революций (например, заката эпохи трансформеров) не произойдёт, 2026-й станет годом широкого использования и развития того, что было разработано в 2025-м. Browser agents, computer use, agentic coding — всё это уже стало очень популярным, а в течение года должно уже прочно закрепиться на массовом рынке. Кроме того, возможно, мы всё-таки увидим первые серьёзные альтернативы трансформерам в архитектуре LLM — Mamba, Titans, диффузионные LLM ждут своего часа.
В следующих частях обзора мы поговорим о других аспектах искусственного интеллекта: о моделях, работающих с изображениями, об AI safety, о роботике и так далее. С наступившим 2026-м, коллеги!
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале «Sineкура»: присоединяйтесь!
Расскажу вам сегодня об ещё одном своём хобби. Точнее, хобби это трудно назвать, потому что это не занимает никакого постоянного времени в жизни. Но это крутая активность, которую я всем рекомендую: мы с друзьями иногда собираемся и читаем по ролям пьесы.
Звучит максимально уныло, но на самом деле это практически всегда получается огненно и очень нравится в итоге буквально всем, кто приходит:
За саму идею того, что так можно было, большое спасибо Маше Абих, которая проводит читки более серьёзно, не на дому, с открытым входом для всех и так далее.
Но у такого более открытого формата есть и свои недостатки. Главный в том, что ты в итоге можешь прийти на читку и так никакой роли и не получить — Маша выбирает пьесы заранее, и ролей там столько, сколько есть. Прийти куда-то на целый вечер и так и не почитать или сказать “Кушать подано” — вот это уже действительно максимально уныло.)
Поэтому я перешёл на домашний формат, с друзьями в тёплой компании. При таком подходе мы сначала смотрим, сколько человек реально собрались, а потом уже выбираем пьесу с соответствующим числом ролей. Вчера, например, читка была прямо рекордная; первую пьесу читали на 18 человек, вторую чуть поменьше. С таким количеством, конечно, были и маленькие роли, но обычно людей гораздо меньше, а пьесы, как вы понимаете, бывают на любое число ролей; меньше даже лучше, потому что каждому точно достанется немало текста.
И пьесы в этот раз подобрались хорошие. Сначала “Блондинка” Александра Володина; это советская классика, которая вполне современно воспринимается до сих пор.
А потом “Очень-очень-очень тёмное дело” Мартина Макдоны. Последняя оказалась совсем огненной: Макдона всегда великолепен, а тут это было ещё и внезапно не про ирландскую хтонь (а про бельгийскую, но не без твистов).
Если вы думали, чем заняться с друзьями, рекомендую попробовать. Пьес в интернете выложено великое множество, и классических, и современных, на любой вкус; главный сайт для этого дела называется “Театральная библиотека Сергея Ефимова“, там большая база.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура“: присоединяйтесь!
Дорогие подписчики! Пока куранты ещё не пробили, давайте подведём итоги первого года существования канала. Мы с Клодом сделали для вас немного нехитрого data science с симпатичными графиками.
Постов становится больше
За 2025 год в канале “Sineкура” вышло 284 поста. Это примерно 0.78 поста в день, или, если угодно, один пост каждые 30 часов. Возможно, название канала не то чтобы соответствует действительности…
Посмотрите на график роста — здесь тренд несомненный!
В январе я робко выложил 14 постов, в феврале вообще ушёл в творческий кризис, а потом всё-таки решил, что вести канал надо, и к декабрю мы вышли на 39 постов (это сороковой) — устойчиво по одному посту в день, иногда больше.
Если экстраполировать эту линию в будущее, то к 2027 году я буду выкладывать по сто-двести постов и покупать по двадцать свадебных тортов в месяц. Но пока всё под контролем.
Реакции подписчиков — спасибо вам за них!
А вы оставили 10 308 реакций — то есть в среднем по 36 реакций на пост. Спасибо, что не ленитесь тыкать в кнопочки! Каждый ваш огонёчек и каждое ваше сердечко греют моё сердце.
Безусловные лидеры — сердечко (36.8% всех реакций) и огонёчек (31.3%). Кажется, вам нравится мой канал — или, по крайней мере, вы убедительно притворяетесь, и за это вам тоже спасибо.
Временные срезы
Этот график показывает, в какое время в канале обычно появляются посты. Пик активности — с 11 до 15 часов. Это ниоткуда не следует, но как-то так получается, что я большую часть года старался писать около полудня. Возможно, это и неправильно, надо будет поэкспериментировать.
По дням недели картина такая: среда — абсолютный чемпион, потому что по средам был семинар лаборатории Маркова, и получалось, что к обычному ежедневному посту добавлялась фоточка. По пятницам тоже немало выходило, потому что традиция пятничного поста сформировалась ещё весной.
Для особенно дотошных есть даже heatmap, объединяющий оба параметра:
Хэштеги и темы
Примерно с сентября я начал проставлять хэштеги, и по ним тоже уже накопилась некоторая статистика:
По количеству, понятное дело, #spsu — безусловный лидер (80 постов!). Ну да, я работаю в СПбГУ и именно оттуда выкладываю большинство лекций.
А вот по реакциям безоговорочно побеждает #lifestyle — всего 5 постов, но реакций в среднем почти 100! Вывод очевиден: вам интереснее моя жизнь, чем мои лекции. Думаю, что всего хорошо в меру, но постараюсь почаще использовать этот тег в наступающем году.
Ещё один график, на который мне было интересно посмотреть — зависимость числа реакций от длины поста. Как вы уже заметили, я люблю порастекаться по древу, и было у меня подозрение, что в телеграм-канале так лучше не делать.
Оказалось, что нет, всё в порядке; корреляция, конечно, отрицательная, но очень слабенькая, почти никакой:
Так что не буду себя ограничивать. Да и вообще, я же не для SEO пишу свои посты, а для себя и для вас.
Как видите, в топ попали в основном посты с тегом #lifestyle — точно придётся почаще включать, как говорили много лет назад, лытдыбр.
Можно посмотреть и на распределение реакций:
Получается, большинство постов собирает 15-40 реакций, а вот вырваться за сотню — это уже надо постараться.
С Новым годом!
Год заканчивается, и хочется сказать что-то умное про итоги и выводы. Но на самом деле главный вывод простой: спасибо, что вы есть.
Спасибо, что читаете мои длинные посты про искусственный интеллект и короткие посты про жизнь. Что ставите сердечки и огоньки. Что иногда пишете в комментариях что-то хорошее — это правда очень важно.
Этот канал начинался как эксперимент, а стал чем-то важным для меня. И это благодаря вам.
Пусть в новом году у вас будет поменьше неудач и побольше инсайтов. Пусть близкие будут рядом, а дедлайны — далеко. Пусть находится время на то, что по-настоящему важно.
С Новым 2026 Годом, дорогие подписчики!
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!
Это статья из новогоднего выпуска журнала “Деловой Петербург”, посвящённого итогам первой четверти XXI века. Выкладываю также полную свёрстанную версию в pdf:
Двадцать пять лет назад, на пороге нового тысячелетия, сильный искусственный интеллект казался далёкой, а то и несбыточной мечтой. Нейронные сети существовали только в академической среде, передним краем искусственного интеллекта были рекомендательные системы и поиск в интернете, а идея машины, способной поддержать осмысленный разговор или создать произведение искусства, оставалась уделом фантастов.
Сегодня AI-системы пишут код, ставят медицинские диагнозы, создают музыку и изображения, ведут переговоры и даже помогают в научных исследованиях. Более того, они уже начинают участвовать в разработке следующего поколения AI-систем.
В этом головокружительном скачке можно выделить три революции, каждая из которых меняла наши представления о возможностях искусственного интеллекта. Сегодня мы поговорим и о них, и о контурах следующей, четвёртой революции, которые уже можно различить в тумане будущего.
Революция глубокого обучения: когда нейросети наконец заработали
Начало пути
История искусственных нейронных сетей началась ещё до того, как AI оформился как научная дисциплина. Первые математические модели нейронов и их взаимодействий появились уже в 1940-х годах, а перцептрон Розенблатта, который в 1958 году стал одной из первых реализованных на практике моделей машинного обучения, был по сути моделью одного нейрона. Метод обратного распространения ошибки, которым обучаются глубокие нейросети, представляет собой просто дифференцирование сложной функции, и к нейросетям был успешно применён уже в 1970-х.
Но в XX веке нейросети оставались скорее предметом академических исследований, чем практическим инструментом. Они работали на игрушечных задачах и демонстрировали принципиальную возможность своего обучения, но неизменно проигрывали более простым методам. “Нейросети — это второй лучший способ сделать всё что угодно”, — говорил в начале девяностых Джон Денкер.
Революция глубокого обучения
Всё изменилось в середине 2000-х. С математической, идейной стороны Джеффри Хинтон и его коллеги представили новый способ, который позволял обучать глубокие нейронные сети; аналогичный прорыв произошёл и в группе Йошуа Бенджи.
Но даже важнее, чем новые алгоритмические идеи, было то, что технологическая база к этому времени тоже созрела для успеха нейросетей. Графические процессоры (GPU), изначально созданные для трёхмерной графики в видеоиграх, оказались идеальным инструментом для обучения нейросетей. Матричные операции, составляющие основу вычислений в нейронных сетях, выполнялись на GPU в десятки и сотни раз быстрее, чем на обычных процессорах. Одновременно развитие интернета породило огромный поток данных: миллионы изображений, тысячи часов видео, терабайты текста. У нейросетей наконец-то появилось и достаточно мощное “железо”, и пища для обучения.
Нейросети шагают по планете
Первой практически важной областью применения нейросетей стало тогда распознавание речи: появившиеся в начале 2010-х голосовые ассистенты были бы невозможны без обработки речевых сигналов теми самыми глубокими сетями Хинтона.
Символическим моментом революции стал 2012 год, когда на главном соревновании по распознаванию изображений (на датасете ImageNet) команда Джеффри Хинтона представила свёрточную нейронную сеть AlexNet. Она не просто победила, она уничтожила конкурентов, снизив лучший показатель ошибки с 26% до примерно 14%. Это был огромный качественный скачок, и с тех пор каждый год победителями этого соревнования становились исключительно нейронные сети (архитектуры которых, конечно, менялись и улучшались со временем).
А в 2016 году AlphaGo, основанная на глубоких нейронных сетях, победила Ли Седоля, одного из ведущих профессионалов в игре го. Ранее эта игра всегда считалась слишком сложной для компьютеров из-за астрономического числа возможных позиций (поиск по дереву в го не работает совсем), и победу AlphaGo не ожидал практически никто — ни профессионалы го, ни специалисты по искусственному интеллекту.
За эти 10 лет глубокие нейросети стали доминирующей парадигмой в машинном обучении. Но у них были свои ограничения. Свёрточные сети хорошо работали с изображениями, рекуррентные — с последовательностями вроде текста или временных рядов, но каждая архитектура была заточена под свой тип данных, обучение оставалось медленным, а масштабирование — проблематичным.
Революция трансформеров
Что такое трансформер
В 2017 году группа исследователей из Google опубликовала статью с провокационным названием “Attention is All You Need” (“Внимание — это всё, что вам нужно”). В ней описывалась новая архитектура нейронных сетей — трансформер (Transformer). На первый взгляд это была просто ещё одна архитектура для обработки последовательностей, конкурент для классических рекуррентных нейронных сетей. Но быстро стало ясно, что это нечто большее.
Ключевая идея трансформеров — механизм самовнимания (self-attention). Представьте, что вы читаете предложение: “Кошка, которая жила у соседей и которую я часто видел во дворе, убежала”. Чтобы понять, кто именно убежал, вам нужно связать слово “убежала” со словом “кошка”, хотя между ними много других слов. Рекуррентные сети обрабатывали текст последовательно, слово за словом, и с трудом могли обрабатывать даже такие связи в пределах одного предложения, не говоря уже о более далёких. Самовнимание позволяет каждому слову “смотреть” на все остальные слова одновременно и решать, какие из них важны для понимания контекста.
От языка к другим модальностям
Эта простая идея оказалась невероятно плодотворной. В 2018 году появилась модель BERT, которая могла читать тексты и понимать их гораздо глубже, чем все предыдущие; здесь “понимать” означает преобразовывать в семантически богатые представления, при помощи которых потом можно решать разные задачи. В пару к BERT появилось и семейство моделей GPT, о которых мы поговорим ниже.
Но революция трансформеров оказалась шире, чем просто обработка текста. Исследователи быстро поняли, что та же архитектура работает и для изображений (в 2020 году вышел Vision Transformer, который стал основой для очень многих архитектур), и для звука, и для видео. Идея самовнимания оказалась универсальной. Более того, трансформеры можно было комбинировать с другими типами сетей, создавая гибридные архитектуры.
Масштабирование
Но, пожалуй, самое важное свойство трансформеров — это их способность к масштабированию. Трансформеры можно разделить на тысячи параллельных вычислений и обучать на сотнях и тысячах GPU одновременно. И исследователи обнаружили удивительный эмпирический закон: качество работы трансформеров предсказуемо растёт с увеличением размера модели, объёма данных и вычислительных ресурсов.
Эти законы масштабирования (scaling laws) перевернули индустрию. Раньше прогресс в машинном обучении достигался в основном за счёт новых архитектурных решений, новых моделей. А теперь появилась простая, почти механическая формула успеха: больше параметров, больше данных, больше вычислений — лучше результат, причём предсказуемо лучше. Это породило “гонку вооружений”, результаты которой мы видим сегодня.
Революция языковых моделей
Откуда взять данные?
Но и это ещё не всё. То самое масштабирование привело к тому, что размеченных данных для обучения стало категорически не хватать. Когда модели стали содержать миллиарды параметров, большие датасеты “обычного” глубокого обучения, вроде ImageNet, перестали казаться большими.
Решение пришло из неожиданной области. Вместо того чтобы размечать данные вручную, можно использовать задачи с саморазметкой (self-supervision), где правильные ответы получаются автоматически, без участия людей. Самая естественная такая задача для текста — языковое моделирование (language modeling): предсказание следующего слова по предыдущим.
Возьмите любой текст из интернета, оборвите в случайном месте и попросите модель предсказать следующее слово — и вот у вас уже есть обучающий пример. А в интернете триллионы слов.
Языковые модели
Задача языкового моделирования, кстати, тоже была всегда. Ещё в 1913 году Андрей Андреевич Марков построил вероятностную модель последовательностей букв в “Евгении Онегине” — первую языковую модель в истории. Простые языковые модели десятилетиями использовались в распознавании речи и машинном переводе, помогая выбрать более вероятный вариант интерпретации. Но, конечно, никто не ожидал, что они смогут писать связный текст или отвечать на сложные вопросы.
И здесь сработало масштабирование трансформеров. В 2018 году OpenAI выпустила GPT — первую большую языковую модель на основе трансформеров. В 2019 появилась GPT-2 с полутора миллиардами параметров, которая уже могла порождать довольно убедительные тексты. Исследователи из OpenAI даже побоялись выкладывать её в открытый доступ. В 2020 вышла GPT-3 со 175 миллиардами параметров — и тут стало окончательно ясно, что происходит что-то экстраординарное.
GPT-3 могла не просто порождать убедительный текст. Она могла переводить, резюмировать, отвечать на вопросы, писать код, сочинять стихи — и всё это без дополнительного обучения на конкретных задачах, просто на основе нескольких примеров в запросе. Модель могла обобщаться на новые задачи прямо во время использования.
Всё это уже произвело революцию в академических кругах, но на публику она вышла только в ноябре 2022 года, когда OpenAI выпустила ChatGPT. Это была та же GPT-3, но дообученная на диалогах и с использованием обратной связи от людей (reinforcement learning from human feedback, RLHF). ChatGPT мог поддерживать связный разговор, помнить контекст, признавать ошибки, отвечать на поставленные вопросы и отказываться от неподходящих запросов. И им могли пользоваться все, через простой веб-интерфейс.
Скорость прогресса
За пять дней ChatGPT набрал миллион пользователей. За два месяца — сто миллионов. Это была самая быстрорастущая потребительская технология в истории. Дальше были GPT-4 и GPT-5 от OpenAI, семейства Claude от Anthropic и Gemini от Google, семейства открытых моделей вроде Llama или DeepSeek и многое другое. Началась гонка больших языковых моделей (large language models, LLM).
Сегодня LLM помогают программистам писать код, юристам анализировать договоры, врачам формулировать диагнозы, студентам учиться, писателям бороться с творческим кризисом. Они встроены в поисковики, текстовые редакторы, системы разработки. Большими языковыми моделями так или иначе пользуются сотни миллионов людей ежедневно.
И прогресс не останавливается. В 2022 году GPT-3 было нелегко справиться с задачами для третьеклассников вроде “У Васи было три теннисных мячика, и он купил ещё две упаковки по четыре; сколько у него теперь мячиков?” А в 2025-м GPT-5 и Gemini 2.5 Pro уже способны самостоятельно решать сложные математические задачи, как олимпиадные, так и исследовательские. Важным прорывом здесь стали рассуждающие модели (reasoning models), которые сначала “обдумывают” задачу на “черновике”, а только потом начинают выдавать ответ. На основе современных LLM уже создаются системы, которые способны производить новые научные результаты — и это только начало пути.
Пожалуй, самое поразительное здесь не конкретные достижения, а как раз скорость прогресса. Закон Мура для AI работает с удвоением производительности не каждые два года, а каждые несколько месяцев. Задачи, которые казались серьёзным вызовом год назад, сегодня решаются почти идеально. Количество вычислений, требующееся для обучения передовых моделей, удваивается примерно каждые шесть месяцев. Мы живём в эпоху языковых моделей, которые прямо сейчас меняют мир в самых разных областях, и экспоненциальный прогресс никак не хочет останавливаться…
Какой будет четвёртая революция?
Заглянуть в будущее всегда сложно, но кое-что мы уже видим. Четвёртая революция в AI, похоже, будет обеспечена не одним прорывом, а несколькими параллельными направлениями, которые могут сойтись неожиданным образом.
Новые архитектуры
Несмотря на доминирование трансформеров, у них есть фундаментальные ограничения. Главное — квадратичная сложность механизма внимания: каждый токен должен “посмотреть” на все остальные токены, что означает, что вычисления растут пропорционально квадрату длины текста. Для контекста в миллионы токенов это становится вычислительно невозможным. Кроме того, у трансформеров нет настоящей памяти — они всегда обрабатывают весь контекст заново.
В последние годы появляются альтернативы: SSM (State Space Models) вроде Mamba с линейной сложностью и встроенной памятью, архитектуры с разреженным вниманием, семейство JEPA (Joint Embedding Predictive Architecture) от Яна Лекуна и так далее. Пока неясно, какая из этих идей “выстрелит”, но поиск архитектуры следующего поколения уже идёт полным ходом.
Мультимодальность и воплощённый AI
Сегодняшние модели всё ещё в основном работают с текстом и изображениями. Но человеческий интеллект развивался во взаимодействии с физическим миром — через прикосновения, движение, манипуляцию объектами. Есть гипотеза, что для создания по-настоящему общего интеллекта нужен воплощённый AI (embodied AI) — искусственный интеллект, который учится через непосредственный опыт некоего физического агента.
Уже появляются модели мира (world models), которые учатся предсказывать последствия действий в визуальной или тактильной среде. Роботы с AI-управлением начинают справляться со сложными задачами манипуляции. Многие компании сейчас работают над человекоподобными роботами, управляемыми большими мультимодальными моделями. Возможно, следующий прорыв придёт именно отсюда, когда AI научится не просто рассуждать о мире, но и действовать в нём.
Агентные системы
Современные LLM отвечают на запросы, но в основном пассивны. Агентные системы должны быть способны ставить себе цели, планировать, использовать инструменты, взаимодействовать с окружающей средой и другими агентами для достижения долгосрочных целей. Уже существуют прототипы, которые могут пользоваться компьютером и браузером, выполнять последовательности действий, реализовывать целые программистские проекты.
Но настоящие агенты потребуют решения проблем надёжности, безопасности и согласования (alignment) целей AI с человеческими ценностями. Агент, который может действовать автономно, потенциально гораздо опаснее, чем пассивный помощник.
AI для науки
И здесь мы подходим к самому головокружительному сценарию. В 2024 году появились системы вроде FunSearch от Google DeepMind, открывшей новые математические результаты, или AI Scientist от Sakana AI, способной проводить полный цикл научного исследования, от гипотез через эксперименты до готовой статьи. LLM уже помогают доказывать теоремы, предсказывать структуры белков, искать новые материалы.
Что будет, когда AI станет не просто помощником учёного, а самостоятельным исследователем? А что будет, когда AI-системы начнут проводить исследования в области самого искусственного интеллекта?
Многие слышали о технологической сингулярности, моменте, когда прогресс становится настолько быстрым, что люди уже не могут уследить за ним. До недавних пор эти рассуждения были чистой фантастикой. Но сейчас кажется, что если AI сможет лучше людей проводить исследования в области AI, то такая система сможет улучшать сама себя, создавая следующее поколение ещё более мощных систем, и этот процесс сможет развиваться экспоненциально без участия людей — та самая сингулярность.
Что будет в таком случае, не знает никто. Есть и утопические варианты прогнозов — решение всех научных и технологических проблем человечества, изобилие, даже потенциальное бессмертие, — и экзистенциальные риски: если мы создадим системы умнее нас самих, и их цели вдруг окажутся несовместимы с человеческим выживанием, человечество может и не сохранить контроль за будущим. Но важно, что все эти прогнозы и варианты очень, очень близки; в сфере искусственного интеллекта пессимистами считаются те, кто откладывает свой прогноз достижения сверхчеловеческого интеллекта на середину 2030-х, а оптимисты предсказывают это уже в нашем десятилетии…
Мы живём в уникальное время — возможно, самое важное в истории человечества. За четверть века искусственный интеллект прошёл путь от набора разрозненных методов с достаточно узкой сферой применимости до технологий, которые трансформируют все аспекты нашей жизни. Три революции — глубокого обучения, трансформеров и языковых моделей — изменили не только наши технологии, но и наше представление о возможном.
Следующие несколько лет будут определяющими. Четвёртая революция уже началась, но мы ещё не знаем её имени. Выборы, которые мы сделаем сейчас — как исследователи, разработчики, регуляторы, пользователи — могут определить траекторию развития не только AI как науки, но и человечества в целом. У нас есть уникальная возможность сознательно направить развитие самой мощной технологии в истории. Будем ли мы достаточно мудры, чтобы воспользоваться ею?
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!
Когда я запускал Wanderstop, я не знал, чего ожидать от этой игры. Знал только, что это тот самый Дэйви Риден. Но оказалось, что попадание вышло стопроцентное: это буквально игра про меня прямо сейчас, в конце очень тяжёлого семестра. Давайте об этом и поговорим; сразу предупреждаю, обзор вышел длинный.
Игры Дэйви Ридена
Нельзя не начать обзор Wanderstop с личности её главного разработчика, Дэйви Ридена (Davey Wreden). Почему-то некоторые пишут по-русски “Вреден”, но это мы категорически порицаем — видимо, у таких авторов самолёт изобрели братья Врайт, а собор святого Павла построил Кристофер Врен.
Знаменит Дэйви в первую очередь игрой The Stanley Parable. Если вы читаете этот обзор, вы наверняка о ней слышали:
Про The Stanley Parable написано и сказано очень много (одна из самых влиятельных инди-игр десятилетия, метакомментарий к самой природе видеоигр, высказывание о свободе воли… продолжать можно долго), поэтому я на ней останавливаться не буду. Скажу только, что если вы не играли в The Stanley Parable Ultra Deluxe (2022) — очень рекомендую, даже если знакомы с исходной игрой. Это не просто ремастер, а полноценное продолжение, которое добавляет кучу нового контента; и да, ведро — это гениально.
Подсвечу лучше вторую игру Ридена, The Beginner’s Guide. Это произведение, которое выглядит очень личным — пишу “выглядит”, потому что, конечно, не могу знать наверняка, и даже подробные интервью Ридена вполне могут оказаться продолжением художественного произведения. Это игра о том, как делать игры, игра в виде диалога между автором и его якобы другом по имени Кода, и это очень эмоциональная и круто сделанная игра.
The Beginner’s Guide устроена так: Дэйви (персонаж, озвученный самим Риденом) проводит нас через серию незаконченных игр своего друга Коды, комментируя каждую из них, пытаясь понять личность создателя через его работы. Постепенно выясняется, что Дэйви модифицировал эти игры, добавлял к ним фонарные столбы, чтобы у них было “окончание”, показывал их другим людям без разрешения… И в финале Кода прямым текстом просит его прекратить.
Есть ли у Коды реальный прототип или это альтер-эго самого Ридена? Некоторые думают, что есть; кстати, это очень крутой обзор, обязательно прочитайте. Но что хотел сказать автор этим конфликтом? Ответов у меня нет, каждый решит для себя, но в любом случае всем очень рекомендую The Beginner’s Guide; игра буквально на два часа, но если вы придёте в неё без спойлеров, то сможете испытать настоящий катарсис. А уже потом почитайте и обзоры-анализы тоже, самому с первого “прочтения” не так просто вникнуть во всё то, что там происходит.
Завязка: как люди выгорают
И вот этот самый Дэйви Риден, мастер метанарратива, берёт и делает… cozy-игру про чайный магазин, фактически ферму?.. Да нет, конечно, всё не так просто, и метанарратив здесь появляется буквально сразу, но кое-что действительно подаётся очевидно и в лоб.
Главная героиня — Альта, непобеждённая воительница, чемпионка арены, посвятившая всю жизнь совершенствованию боевого мастерства. Её принцип прост в формулировке, но для реализации требует постоянной работы над собой (like everything that matters):
И вот три года постоянных побед, сотни поверженных противников… а потом — поражение. И ещё одно. И ещё. Альта не понимает, что происходит — она ведь всё делает правильно! Значит, нужно ещё больше тренировок, больше дисциплины, больше усилий?
Это тоже не работает, и Альта отправляется на поиски легендарной Master Winters (“мастерицы Винтерс”? иногда феминитивы звучат так, что лучше бы их вовсе не было), единственной воительницы, которая могла бы ей посоветовать, что делать. Master Winters искать не нужно, известно, что она живёт в большом лесу на краю света, и именно туда Альта и направляется.
Но по дороге, посреди леса, её оставляют силы. Она буквально не может поднять свой собственный меч. Первое действие которое ты совершаешь в игре — выбор, остановиться ли уставшей Альте передохнуть или бежать дальше. Разумеется, он ни на что не влияет, и ты падаешь без сил:
Я так подробно описал завязку потому, что именно она даёт нам главную тему всего происходящего: выгорание. И это не тонкая метафора или аллюзия, здесь всё говорится в лоб и выкручено на максимум. Мастер метанарратива, двойных посланий и недосказанностей Дэйви Риден вдруг решил поговорить с нами прямым текстом. Наверное, это что-то да значит.
Начало игры: метафора продолжается
Когда Альта приходит в себя, рядом оказывается Боро — добродушный великан, хозяин чайной лавки Wanderstop посреди лесной поляны. Он предлагает Альте остаться и отдохнуть, помочь с магазином. “Заваривание чая полезно для души и тела”, — говорит он и рассказывает, как здесь всё устроено.
Альта, разумеется, в ярости (ты можешь выбирать варианты ответов, но поначалу между ними не так уж много разницы). Она не собирается застревать в какой-то дурацкой уютной игре про чай! Она — воительница! Её место — на арене, а не за заварочным чайником (пусть даже таким крутым и необычным)!
Но каждый раз, когда она пытается уйти в лес, силы покидают её, и она просыпается обратно у Боро. Застряла.
Да, здесь всё ещё продолжается прямолинейное описание выгорания. Кстати, хотя Боро изображается как добродушный, прямолинейный и на первый взгляд не самый умный персонаж, вскоре становится ясно, что он очень непрост:
Боро — не психотерапевт, а метафора того самого unconditional support, который обычно очень нужен, чтобы справиться с выгоранием. Хотя он время от времени действительно делает проницательные и важные замечания, по сути поначалу главный его месседж в том, что Альте просто нужно отдохнуть. А лучший отдых — это, конечно, не сидеть на пенёчке и пережёвывать грустные мысли, а сменить модальность и помогать Боро с его чайным магазином:
Но через все объяснения механик и все предложения с чем-нибудь помочь по хозяйству красной нитью проходит главное — Альте нужно отдохнуть. No pressure. Like, absolutely. Do it if you feel like it; if not, that’s okay too.
Вы уже поняли, что завязка игры очень отозвалась в моём сердечке. Но что же сама игра, что там делать-то надо в этом чайном магазине?
Игра: геймплей здесь не главное
Геймплей Wanderstop очень (даже удивительно!) честно отражает заявленную суть cozy-игры: ты действительно управляешь чайной лавкой. Собираешь чайные листья в лесу, выращиваешь разноцветные фруктовые растения, сушишь листья. Есть механика гибридизации, через которую получаются разные добавки к чаю, но там не очень много возможностей для экспериментов, запороть что-то практически невозможно, а времени всегда бесконечно много.
Когда листья высушены, ты завариваешь чай в причудливой машине посреди магазина. Машина эта — отдельный персонаж: нужно нагреть воду мехами, засыпать ингредиенты, проследить за температурой, налить правильное количество в чашку. Ничего сложного, и опять no pressure, но есть механические действия, которые просто нужно с умиротворяющей последовательностью совершить.
Суть геймплея в том, что персонажи будут приходить и просить сделать им чай с разными добавками. Как правило, всё это будет выглядеть очень прямолинейно: персонаж сказал “хочу с мятой”, значит, нужно в книге с описаниями фруктов найти, какой из них даёт мятный вкус, и добавить его.
Всё это абсолютно без стресса: покупатели ждут сколько нужно, если что-то сделал не так — просто попробуй снова. Нет таймеров, нет штрафов, ничего нет; гейм-дизайн тоже учит тебя замедлиться.
Какие-то более сложные задачки появляются только в самых последних частях игры. Среди них есть и действительно нетривиальные — но игрового челленджа всё равно не будет, ведь в библиотеке на полке стоит “The Book of Answers”, в которой просто прямым текстом написано, что именно сейчас нужно сделать.
Сама Альта поначалу ненавидит судьбу-злодейку, заставившую её подавать чай вместо того, чтобы быть чемпионом арены. Её диалоговые опции практически всегда дают возможность огрызаться на покупателей, жаловаться на скуку, закатывать глаза. И при этом игра никогда не наказывает тебя за это. Можно быть милой и услужливой (не сразу, но eventually можно), можно колючей и раздражённой — история продолжится в любом случае.
Персонажи и истории
Но если геймплей — не главное, то что же главное в этой игре? Разумеется, нарратив, что же ещё…
Персонажи, которые в игре приходят и просят чай, сделаны просто замечательно. Как правило, они одновременно и рассказывают свои человеческие истории, и дают comic relief, и содержат отсылки на что-то узнаваемое. Вот для примера один из персонажей — Джеральд, отец, который никак не может оставить сына в покое. Он пришёл в волшебный лес, чтобы стать настоящим рыцарем и тем самым подняться в глазах сына (который уже подросток, так что ему это всё до большого фонаря).
Но больше всего на свете, конечно же, он любит показывать свои фотографии с сыном:
Спойлерить остальных персонажей не буду. Скажу только, что разумеется, среди них будет и отсылка на The Stanley Parable — одинаково одетые бизнесмены, которые не очень отдают себе отчёт в том, где находятся, и ищут в волшебном лесу переговорку, чтобы сделать в ней презентацию (и их презентации можно послушать, это действительно смешно сделано):
Альта и сама может выпить приготовленный ею чай. Это, кстати, никак не мешает процессу, потому что воды в чайнике хватает на несколько чашек, а персонажам больше одной обычно не требуется. Усевшись на скамейку или диван с чашкой чая, Альта рассказывает о своём прошлом, своих чувствах, каких-то важных воспоминаниях… в общем, эти моменты действительно выглядят как приёмы у психотерапевта:
По мере прохождения раскрывается и второй главный персонаж. Боро — идеальный противовес Альте: она резкая, а он мягкий, она торопится, а он замедляет. Боро никогда не обижается на Альту (поводы, поверьте, есть в избытке), никогда не давит, просто… присутствует. Его манера речи — странноватая, немного не от мира сего — создаёт ощущение, что он знает что-то, чего не знаем мы.
Отдельное удовольствие — книги, которые попадаются в игре. Здесь мы в полный рост видим Дэйви Ридена, автора The Stanley Parable; вот несколько кусочков из разных книг:
Заключение
Конечно, это ещё не всё. Я не буду спойлерить вам ни других важных персонажей, ни сюжетных линий, которые действительно вызывают эмоции. Да и очаровательные плаффины стоят упоминания. Но пора подвести итоги.
Wanderstop — это не совсем та игра, которую я ожидал от Дэйви Ридена. Здесь нет безумного метанарратива Stanley Parable, нет болезненной интроспекции The Beginner’s Guide. Это более… человечная игра? Более тёплая? И при этом она всё ещё несёт фирменный почерк Ридена. Юмор на месте. Неожиданные повороты на месте. Персонажи, которые говорят вещи, от которых хочется остановиться и подумать — тоже на месте.
Wanderstop — это игра о выгорании. Не метафорическом, а буквальном, о том состоянии, когда ты делаешь всё правильно, работаешь усерднее, чем когда-либо, и при этом становится только хуже.
Сам Риден говорил в интервью, что после успеха Stanley Parable и The Beginner’s Guide он столкнулся с тяжёлым выгоранием. Он думал, что создание “уютной игры” поможет ему восстановиться. Это не сработало — по крайней мере, не так, как он ожидал. Разработка Wanderstop заняла почти девять лет, и за это время “cozy game” успело стать целым жанром. Кстати, Риден и здесь показал свою гениальность: он начал делать Wanderstop, когда ещё не вышла даже Stardew Valley, и фермы были разве что весёлые и мобильные, с которых точно пример брать никому не рекомендуется.
“Просто сделать cozy game недостаточно, чтобы исцелить человека”, — говорит Риден. И игра честно показывает это: Альта не выздоравливает просто потому, что поливает цветочки и заваривает чай. Ей приходится столкнуться с причинами своего состояния, с тем внутренним голосом, который требует быть лучшей, сильнейшей, идеальной.
Во мне всё это очень откликается. Я, конечно, не так клинически выгорел, но тоже очень устал к концу этого года, и тоже задаю себе те же вопросы, что и Альта: “Почему мне уже ничего больше не хочется, а порой и не можется? Что со мной не так?” Так что Wanderstop попалась мне очень вовремя. Может быть, я бы иначе воспринял её год назад или через год — но сейчас это именно то, что мне нужно.
Если вы чувствуете себя как Альта — попробуйте Wanderstop. Не ради геймплея (хотя он милый), не ради истории (хотя она трогательная), а ради того странного эффекта, когда игра про чайный магазин говорит вам что-то важное о вашей собственной жизни.
Альта постепенно, через разговоры с посетителями, через чаепития, через саму необходимость замедлиться находит ответы на свои вопросы. Не простые ответы, не “просто отдохни и всё пройдёт”, а настоящие, честные. Надеюсь, что и мы с вами их найдём.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!
Как, ну как у азиатских разработчиков раз за разом получается сделать по-настоящему глубокие произведения?.. Сюжет и мораль в Minds Beneath Us, пожалуй, на голову выше даже пресловутой Nier: Automata, которая мне когда-то очень понравилась и вместе с Outer Wilds вернула меня в большой гейминг. А в “западных” проектах даже и не знаю, с чем сравнить.
Думаю, секрет прост: они не отворачиваются от сложных вопросов. И не пытаются давать на них слишком простых ответов вроде “просто будь чутким к людям”, “любовь победит всё” или “мы разные, но мы вместе”, чем часто грешат западные студии. Нет, в этой игре тебе честно показывают несколько вариантов и признают: да, здесь действительно есть проблема, и да, её действительно можно решать по-разному, это неоднозначный этический вопрос, а не IQ-тест с правильным ответом. Я не знаю, почему у условно “западных” студий редко получается сделать то же самое, но факт: очень, очень редко.
Из других примеров, которые когда-то запали мне в душу, назову Until Then — ещё одну азиатскую инди-игру, от филиппинской студии Polychroma Games. Это пиксельная визуальная новелла о старшекласснике Марке Борха, живущем на Филиппинах после глобальной катастрофы.
Как и Minds Beneath Us, игра мастерски сочетает slice of life эпизоды с глубоким метафизическим сюжетом о потере, памяти и взрослении. Атмосфера, кстати, там тоже очень классная, с невероятной любовью к деталям; но главное именно в сюжетных поворотах и эмоциональном воздействии. Я проходил её ещё до того, как появился этот блог, так что вряд ли уже смогу написать подробный обзор, но очень рекомендую.
Но давайте переходить к Minds Beneath Us.
Разработчики, жанр, геймплей
Minds Beneath Us — дебютный проект тайваньской инди-студии BearBone Studio. Студия была основана в 2019 году и состоит всего из семи человек. Разработка игры началась в 2020 году, первый тизер появился в июне 2021-го, а релиз состоялся в конце июля 2024 года. Честно говоря, ничего особенно интересного о разработчиках добавить не могу, разве что отмечу отдельно саундтрек от французского композитора Кевина “Kounine” Коломбэна (Kevin Colombin).
По жанру Minds Beneath Us — это нарративное приключение, почти визуальная новелла, только с небольшими элементами point-and-click квеста. Геймплей максимально простой: ходим влево-вправо по ограниченным локациям, разговариваем с персонажами, иногда в острых моментах прожимаем несложные QTE.
Озвучки нет — только текст и звуковые эффекты. Прохождение занимает около 15 часов.
Визуально игра выполнена в стиле 2.5D: трёхмерные локации с двумерными персонажами, нарисованными вручную. Интересная деталь — у персонажей нет лиц, только силуэты и причёски; поначалу это кажется странным, но эмоциональной вовлечённости совершенно не мешает: характеры передаются через диалоги, позы и анимацию.
Есть и хорошо анимированные мультипликационные вставки в важных местах (не совсем кат-сцены, обычно там диалог тоже есть, но они заметно отличаются от основного геймплея).
Фоны детализированы с большой любовью: камеры наблюдения следят за тобой, кошки спят на крышах, NPC на фоне живут своей жизнью — играют в гача-автоматы, курят, болтают.
Отдельно понравилось внимание к тайваньским реалиям (хотя, конечно, в Тайване я никогда не бывал): магазины betel nut, лапшичные, мастерские по ремонту скутеров, станции метро — всё это создаёт ощущение реального живого города, а не абстрактного киберпанк-мегаполиса.
Главная геймплейная механика, разумеется, содержится в диалогах. В игре часто нужно делать выбор; иногда понятно, какой выбор “хороший”, но далеко не всегда! Эти небольшие выборы вряд ли повлияют на глобальное развитие сюжета (разве что после титров, возможно, исход побочной ветки изменится), но это действительно круто сделанные повествовательные мини-загадки: они честные (догадаться, что ведёт к желаемому результату, можно), но непростые, да и желаемый результат у разных людей может быть разный.
Даже загружаться и переигрывать до победного не получается — результаты своего выбора ты частенько узнаёшь очень не скоро.
В общем, картинка приятная, киберпанк-стиль хороший, но в целом ничего особенного, не в этом сила игры. Сила — в повествовании, сюжете и мыслях…
Переходя к спойлерам
Minds Beneath Us — это игра, которую очень хочется обсудить и которую нельзя обсуждать. Хочется, потому что игра действительно глубокая, и вопросы, которые в ней затрагиваются, стоят обсуждения. Нельзя, потому что любое обсуждение испортит вам впечатление.
Так что давайте сделаем так: выше я написал пару слов без спойлеров об игре в целом, а сейчас напрямую расскажу вам сюжет и то, почему он мне понравился. Но ещё раз рекомендую сначала поиграть самому.
И, кстати, не надейтесь, что получится всё забыть. Я играл на Steam Deck, то есть в основном урывками в пути, и 14 часов прохождения у меня растянулись больше чем на месяц. Обычно это значит, что между игровыми сессиями ты всё забываешь, и обычно для такого режима лучше подходят игры с короткими независимыми сессиями. Но не в этом случае. Не буду врать, что я помнил об игре всё время и размышлял о её моральных проблемах в ожидании следующей поездки в метро, но как только снова брал игру в руки, тут же вспоминал сюжет во всех подробностях.
Но хватит предупреждений, давайте переходить к делу.
Сюжет со всеми спойлерами
Minds Beneath Us — это киберпанк-история. Она начинается с очень крутого эпизода: ты — личность неизвестного происхождения и без всякой памяти о себе, которая вдруг оказывается в теле какого-то контрабандиста по имени Иван Чжан. Тебе нужно добыть важную информацию у его подельника, находящегося в той же больничной палате, и об этом тебе рассказывают какие-то странные люди, смотрящие за тобой через одностороннее стекло.
Мы ничего не понимаем — кто мы такие, почему здесь, что происходит — но справляемся. А потом вдруг появляется из ниоткуда непонятно кто в капюшоне и убивает странных людей. Про эту таинственную фигуру нам ещё не скоро расскажут, только в самом конце игры.
Потом ты оказываешься в теле Джейсона Дая (Jason Dai), которым и будешь в основном управлять. Но “настоящий” Джейсон не пропадает — в конце каждого игрового дня ты будешь разговаривать со своим “хостом”, а в процессе игры иногда видеть его мнение о происходящем; и ты сможешь выбирать, прислушиваться к нему или нет.
И начинается достаточно долгая экспозиция, в которой тебе рассказывают, как этот мир устроен. Главное фантастическое предположение похоже на “Матрицу”, но с характерным киберпанковым перевёртышем: в мире, где AI автоматизировал почти всё, человеческие мозги используются как вычислительные устройства. Обычных серверов больше нет — их роль выполняют так называемые “flop farms”, на которых люди (их тут называют juicers) сдают свои мозги в аренду, подключаясь к серверу на месяцы или даже годы.
Для беднейших слоёв общества это зачастую единственный способ заработать на жизнь в мире, где все рабочие места забрали роботы.
И Джейсон как раз устраивается на работу на одной из таких ферм, принадлежащей крупной Vision Corporation. Сотрудники фермы управляют AI-системой под названием Silencio… или Silencio управляет если не всей корпорацией, то по крайней мере своей фермой; это не до конца ясно.
Параллельно развиваются его отношения с девушкой по имени Фрэн (Frances Cheng), которая занимает важную должность в Vision. Она искренне верит, что flop farming может решить проблему безработицы и дать шанс беднякам выбраться из нищеты, но у неё свои претензии к Vision, глубину которых ты пока не понимаешь.
Мне, кстати, кажется, что это тоже сильная сторона именно азиатского гейм-дизайна: почему-то в западных проектах реже встречается такая экспозиция через эпизоды slice of life (даже сам этот термин, кстати, пришёл из мира манги/аниме). При этом западный проект может быть бесконечно растянут за счёт закрывания однотипных вопросиков в открытом мире, но почему-то никогда не за счёт настоящей смены регистров и темпа повествования — а жаль!
Джейсон проходит собеседование и должен выбрать между двумя отделами: Screening (отбор кандидатов для фермы, по сути HR на большом потоке) и Ops (непосредственная работа с juicers, когда их готовят к подключению). Каждый отдел показывает разные грани этой индустрии. В Screening ты видишь отчаянных людей, готовых продать своё сознание за деньги, и тут же погружаешься в небольшие, но важные для этих людей моральные дилеммы:
А в Ops приходится погрузиться в саму механику “выжимания сока”, где людей укладывают в стойки и подключают к системе. Люди под транквилизаторами, но кажется, что процесс для них всё равно довольно мучительный:
Разумеется, там всё время что-то идёт не так, есть масса мини-квестов, которые развивают отношения с другими персонажами и прорабатывают образы, куча небольших выборов, всё такое. Но всё это описывать было бы совсем уж долго.
Через несколько дней на Фрэн совершают покушение — её сбрасывают с крыши штаб-квартиры Vision. Она выживает, и это событие затягивает Джейсона в корпоративные интриги. Он знакомится с членами секретной организации OWL: лидером группы Nin Situ — оперативницей с нечеловеческими способностями, её напарником 23 и молодым идеалистом Лоуренсом.
Выясняется, что OWL расследует Vision на предмет незаконной деятельности — компания производит слишком много вычислительных мощностей, больше, чем можно объяснить отчётным количеством juicers. Тебя втягивают в расследование, причём сразу со всех сторон, официальные следователи тебя тоже вербуют:
Параллельно мы узнаём, что и Джейсон — не обычный человек. В его генах есть модификации, которые делают его сильнее и быстрее обычного человека. Это тоже, конечно, не случайность — он сам является частью какого-то эксперимента.
Когда вот так излагаешь сюжет, всё это звучит как бред сумасшедшего или B-movie из восьмидесятых, правда? Но, во-первых, это действительно очень круто подано, ты всё время внутри событий, и никакого отторжения всё это не вызывает. А во-вторых, в конце ты понимаешь, что на самом деле всё это просто большой сетап для того, чтобы заставить тебя задуматься о нетривиальных моральных проблемах.
В итоге суть проекта корпорации Vision оказывается такова: они берут ДНК здоровых детей (никакого вреда им не нанося при этом) и выращивают на её основе специальные усиленные человеческие мозги, которые потом фактически пытают, чтобы извлечь из них побольше вычислительных мощностей. Это проект “Sleeping God” (“Спящий Бог”) — массовое производство искусственно выращенных мозгов для замены добровольных “выжимателей”.
Ваша ячейка OWL проникает в секретную лабораторию и уже готова её взорвать… но тут выясняется, что буквально сегодня утром приняли закон, по которому всё это абсолютно легально, OWL прислала группу на перехват, и игра заканчивается на крыше небоскрёба. Ты стоишь перед Nin Situ, которая убедительно объясняет тебе, что оставить Vision в покое — это меньшее зло, и делаешь финальный выбор.
Давайте рассмотрим и его, и другие моральные вопросы подробнее.
Моральные дилеммы Minds Beneath Us
Первый вопрос, который ставит игра, вы уже поняли: насколько этично то, что делает Vision? Если мозг клонирован и выращен искусственно ускоренными темпами, значит ли это, что с ним можно делать всё что угодно?
Мне кажется, что это очень прозрачно прикрытый вопрос о том, когда мы начнём считать этическим субъектом собственно сам искусственный интеллект. Именно об этом недавно вышла работа “Taking AI Welfare Seriously“, которую я часто поминаю в своих докладах.
Главное, что меня в ней привлекает, — это, конечно, чистая апелляция к авторитету: среди авторов статьи есть сам Дэвид Чалмерс! Тот самый австралийский философ, который первым начал всерьёз писать о hard problem of consciousness, философских зомби и всём таком прочем. Если на свете и есть эксперт в теме самосознания, то это Дэвид Чалмерс.
И вот в этой статье авторы, включая Чалмерса, утверждают, что существует реалистичная возможность появления сознательных и/или обладающих устойчивой агентностью ИИ-систем в ближайшем будущем! А значит, вопрос о благополучии ИИ и его моральном статусе — это уже не вопрос для научной фантастики или далёкого будущего, а вопрос, который компании и общество должны начать воспринимать всерьёз прямо сейчас. Вот главный вывод в статье:
В игре, конечно, вопрос сделан несколько проще, чем в реальной жизни: там буквально человеческий мозг, просто выращенный из чужой ДНК. Но суть та же: с какого момента вычислительный субстрат становится моральным субъектом? Когда появляется сознание? Когда появляется способность страдать? И кто имеет право это определять?
Второй очень интересный вопрос — это собственно последний выбор. Когда ты стоишь в окружении оперативников OWL, у тебя четыре варианта:
Взять оружие и присоединиться к OWL вместе с Нин Ситу — стать частью системы, которая пытается бороться с корпорациями изнутри. Да, тебя будут использовать, да, вход тут рубль, а выход два, но у тебя будут ресурсы и структура, способная что-то реально изменить. Фрэн будет рядом, и вы сможете вместе делать мир лучше.
Присоединиться к OWL, но отвергнуть Нин Ситу — вступить в организацию, но держать дистанцию от человека, который неоднократно манипулировал тобой. Признать её опасной, но работать в той же структуре. Я особой разницы между первыми двумя вариантами не ощутил, честно говоря, но не в этом дело.
Использовать светошумовую гранату и сбежать — отказаться от обеих сторон, присоединиться к “Moonflowers” (подпольной организации Ивана Чжана) и начать новую жизнь с чистого листа. Но это значит бросить Фрэн и всё, что у тебя было, и вряд ли уже смочь на что-то повлиять в дальнейшем.
Взорвать лабораторию и погибнуть — уничтожить проект “Sleeping God” ценой своей жизни. Радикальное решение, которое нанесёт удар по Vision, но также обрушит инфраструктуру города, зависящего от flop farms, и оставит Фрэн одну, разбитую горем. Это на первый взгляд и есть “хороший моральный выбор”, но на самом деле это довольно мрачная концовка: город погружается в хаос, жизненно важные службы перестают работать, люди страдают.
На мой личный взгляд, это один из очень немногих выборов в видеоиграх, о котором действительно интересно поразмыслить! Аргументы в пользу каждого из вариантов довольно очевидны, но что из них перевесит, что здесь действительно меньшее зло — это вопрос, на который нет ни верного ответа, ни даже “хорошего”.
В этом и искусство нарратива Minds Beneath Us: поставить вопрос, на который все четыре взаимоисключающих варианта ответа выглядят очень неплохо… или очень плохо, в зависимости от того, как на это посмотреть.
Есть и пятый, скрытый вариант: если на протяжении игры ты систематически принимал решения, противоречащие желаниям “настоящего” Джейсона Дая (того, чьё тело ты занимаешь), в финале он может взять контроль обратно и принять решение за тебя. Это добавляет ещё один слой к вопросу о свободе воли и праве на собственное тело.
Обзор и так уже затягивается до невозможности, поэтому ограничусь этими двумя примерами. Но на самом деле мини-выборы, о которых я писал выше, тоже очень хорошо сделаны. Они не так важны для твоего персонажа и сюжета, но там тоже есть это самое главное качество: совершенно не очевидно, какой выбор “правильный”, или, точнее, “хороший” — it’s always messy, just like real life.
И, кстати, в конце тебе расскажут больше о проекте Sleeping God и о том, кем было то таинственное существо из самого начала игры. Там тоже сразу же возникают крутые вопросы, но эта ветка фактически только анонсирована, и по всей видимости это задел на сиквел, так что обсуждать её не буду.
Заключение
Minds Beneath Us — редкий пример игры, которая не боится задавать сложные вопросы и не пытается дать на них простые ответы. В нашем мире большинство нарративных игр сводятся к бинарному выбору между “хорошим” и “плохим”, или, в лучшем случае, между “синими” и “красными”, где у каждой стороны своя правда, и ты выбираешь исходя из личных пристрастий к тем или иным персонажам. А BearBone Studio создали историю, в которой масса действительно неочевидных решений, о которых хочется подумать и поспорить.
И да, я не упомянул многие сюжетные повороты и побочные линии: отношения между 23 и Нин, историю Лоуренса и его одержимость справедливостью, загадку M.B.U. и существа из пролога. Всё это лучше открыть самому.
Если вас не пугают около 15 часов чтения текста без озвучки, если вам нравятся истории о киберпанке, корпоративной антиутопии и вопросах сознания и идентичности — Minds Beneath Us однозначно заслуживает внимания. Это не просто игра — это произведение искусства, которое останется с вами надолго после финальных титров. Надеюсь, когда-нибудь и западные разработчики научатся делать что-то подобное.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!
Нет, я не стал инди-разработчиком игр, хотя иногда очень хочется. Это название бандла, содержащего три игры от разработчика bilge — и название это как нельзя лучше отражает суть происходящего: игры маленькие, странные и очень личные.
Кто такой bilge
За псевдонимом bilge скрывается Билге Каан, независимый разработчик из Стамбула, который делает игры в свободное время между коммерческими проектами. Много интересного я про него выяснить не смог — кажется, по основной работе он создаёт HTML5-игры на фрилансе и продаёт игровые шаблоны, а в личных проектах работает в необычном движке Construct 3.
Но главное в том, что Билге создаёт экспериментальные игры, которые балансируют где-то между искусством, головоломкой и философским высказыванием. Его авторский подход выделяется даже в разнообразном мире инди-игр; каждый проект — это законченное высказывание, короткое, но плотное по смыслу. Критики регулярно употребляют слова вроде “сюрреалистичный”, “экспериментальный” и “не для всех”; именно здесь они как нельзя более к месту.
Indecision: видеоигровое хокку
Первая игра в бандле, Indecision. (да, с точкой в конце), вышла в феврале 2018 года, и её разработка заняла у Билге два года. Сам автор называет её “a haiku platformer” — и это определение действительно проникает в суть. Игра очень короткая (около получаса; если захотеть увидеть весь контент, наверное, придётся потратить час-полтора) и расплывчатая, она построена на недосказанности и атмосфере.
Визуально Indecision. напоминает Fez по стилю пиксельной графики, но по духу это совершенно другая вещь. Игра представляет собой набор сценок, слабо связанных друг с другом. Каждый уровень начинается с чёрного экрана и одного слова в нижнем левом углу экрана, и связь между словом и происходящим редко бывает очевидной. Иногда есть контур двери, в которую можно войти, чтобы перейти к следующей виньетке, но часто его надо искать разными способами.
Критики отнеслись к игре неожиданно тепло для столь экспериментального проекта. Kotaku написал, что “потребовалось всего несколько секунд, чтобы влюбиться в неё”, а Defunct Games назвал Indecision “микро-шедевром”. Действительно, в игре много интересного: загадочные решения головоломок, визуальные шутки, и что-то зловещее, прячущееся за внешней простотой. Даже экран паузы превращается в метафору: ваш персонаж стоит перед дверью на платформе, окружённой тьмой; если вы побежите вправо и упадёте с края, игра закроется.
И тем не менее, даже игру на полчаса-час хочется назвать неровной. Среди уровней есть очень интересные решения, есть откровенно проходные, а есть оставляющие в полном недоумении. Но разве не в этом суть хокку?
Stikir: игра о создании игры
Вторая игра в бандле, stikir (да, с маленькой буквы), вышла в октябре 2019 года и представляет собой ещё более радикальный эксперимент. Официальное описание гласит, что это “игра о создании этой игры” — и это святая правда.
Игра начинается с того, что вы управляете космическим кораблём и стреляете по словам “Я хочу выпустить игру за шесть месяцев”, которые продолжают появляться на экране.
Отсюда начинается путешествие внутрь головы разработчика, пытающегося понять, какую игру он вообще хочет сделать. Получается хаотичное, но продуманное месиво жанров: платформер превращается в гонки сверху вниз, затем в shoot ’em up против большого красного шара, потом в JRPG, где нужно принести воду для кофе…
Цветовая палитра stikir напоминает славные времена EGA-графики — четыре кислотных цвета, которые сразу отсылают к самым ранним компьютерным играм. Но за ретро-эстетикой скрывается постмодернистское высказывание о природе творчества: stikir показывает, каким одновременно фрустрирующим и захватывающим может быть процесс разработки.
Это снова очень короткая игра (меньше часа), она снова представляет собой набор по сути отдельных сценок-уровней, и она опять получила отличный приём от критиков. На этот раз ничего неровного или проседающего я не увидел, сценки очевидно связаны друг с другом процессом разработки игры, юмор на месте, темп выдерживается, и в игре много неожиданных решений, разрушающих стереотипы.
PAGER: Кафка в небоскрёбе
Теперь переходим к главному содержанию бандла — PAGER, самой свежей и самой амбициозной работе Билге. Игра вышла в августе 2025 года и представляет собой уже не маленький набор коротких сценок, а… большой набор коротких сценок, аж на 60 этажей офисного здания.
PAGER — это “однобитный кафкианский 3D-хоррор”, действие которого разворачивается в офисном здании 90-х годов. Стиль игры снова необычный и ещё более интересный, чем в играх выше. Монохромная картинка в чёрно-белых тонах с минималистичной 3D-графикой создаёт атмосферу, в которой смешиваются ностальгия, дискомфорт и сюрреализм.
Билге говорил, что вдохновлялся сериалом Severance, произведениями Кафки и Линча, сериалом The Prisoner (1967), игрой The Stanley Parable и аниме Sonny Boy и Serial Experiments Lain.
Основная механика крутится вокруг пейджера, который присылает вам указания. Вы — wetware, сотрудник, выполняющий непонятную работу в корпоративной иерархии. Указания нужно выполнять в точности — и именно здесь начинается самое интересное.
Вот пример из самого начала игры: вам пишут, что в другую комнату можно заходить только с ящиком. Потом приходит задание — занести ящик в комнату 1 и поставить на стол. Отлично, задание выполнено! Теперь можно идти к лифту, который отправит вас дальше… но подождите. Лифт тоже в другой комнате, а значит, туда тоже можно только с ящиком. Который вы только что оставили в другом месте.
Идея крутая, и звучит как основа для большой и разнообразной пазл-игры. PAGER действительно начинается очень интересно, с хоррор-элементами и неожиданными поворотами. PC Gamer назвал её “trippy, tense 1-bit simulation perfect for fans of Severance”, Kotaku написал про “excellent Kafkaesque horror based on obeying a pager”, а Rock Paper Shotgun признался, что “не должен был чувствовать себя как дома в кошмарном офисном мире PAGER”.
Но я сильно подозреваю, что в данном случае не все обозреватели доиграли до конца… Хотя начало действительно захватывает, в целом многие уровни оказываются слишком прямолинейными. Идёшь, делаешь что сказано, и всё; иногда встречаются любопытные высказывания, но далеко не каждый раз, а представляющие геймплейный интерес задания и того реже. Потенциал механики раскрыт не полностью — кажется, что можно было сделать куда более разнообразные и интересные загадки. Есть уровни, которые удивляют и заставляют думать, но немало и таких, которые просто проходишь на автопилоте.
И всё-таки это любопытный опыт. Действительно уникальная атмосфера, среди уровней есть много интересных; скучные тоже есть, но с общей длительностью 4-5 часов это не так страшно. Рекомендую как минимум попробовать.
Заключение: маленькие странные миры
Каждая из трёх игр в бандле — по сути, набор слабо связанных друг с другом сценок. Это не классические игры с чёткой структурой, прогрессией и концовкой. Это скорее интерактивные эссе, видеоигровая поэзия, эксперименты с формой и содержанием.
Качество у них довольно неровное — это факт. В каждой игре есть моменты, которые заставляют улыбнуться или задуматься, но есть и моменты, которые оставляют в недоумении или раздражают. Но я всё равно рекомендую с ними ознакомиться. Много времени на это не понадобится — все три игры в сумме займут несколько часов — а впечатления будут как минимум необычные.
Интересно, что мне первые две игры (Indecision. и stikir) понравились даже больше, чем magnum opus разработчика PAGER. Возможно, дело в том, что они короче, и концентрация идей, которые со мной срезонировали, в итоге получается выше.
Билге Каан не гонится за мейнстримом, и в этом его сила. Его игры напоминают, что видеоигры могут быть какими угодно — не обязательно большими, отполированными и понятными. Нужна только та самая загадочная “душа”, которую в этих проектах почувствовал и я, и, думаю, профессиональные критики.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!



")
")
")
")
")
")
")
")



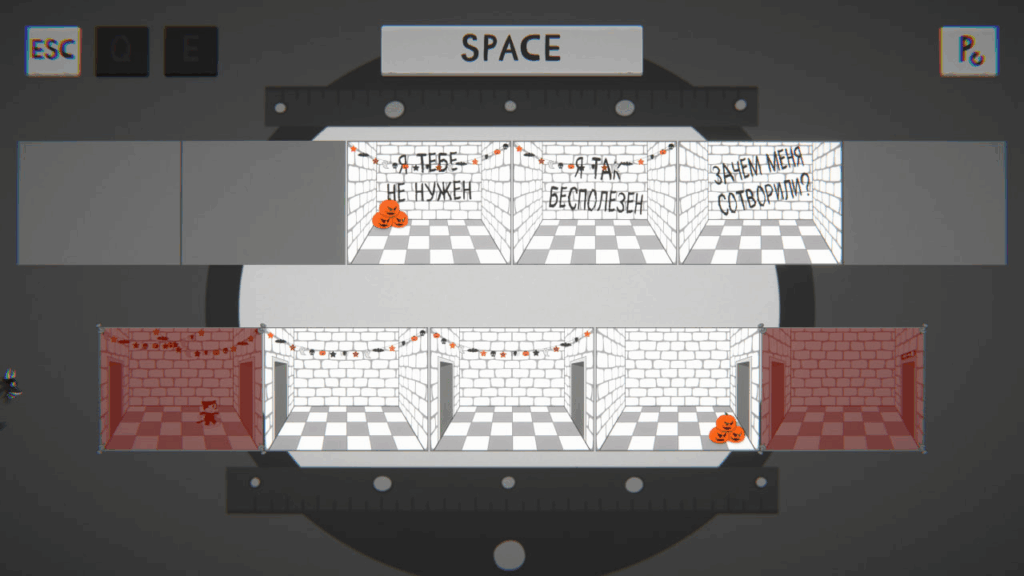












")

")
")
























































































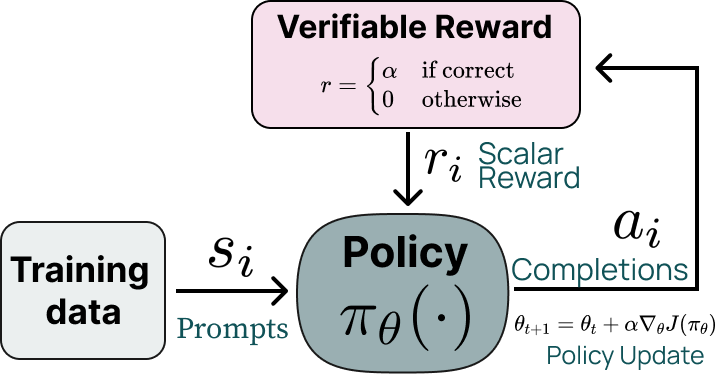

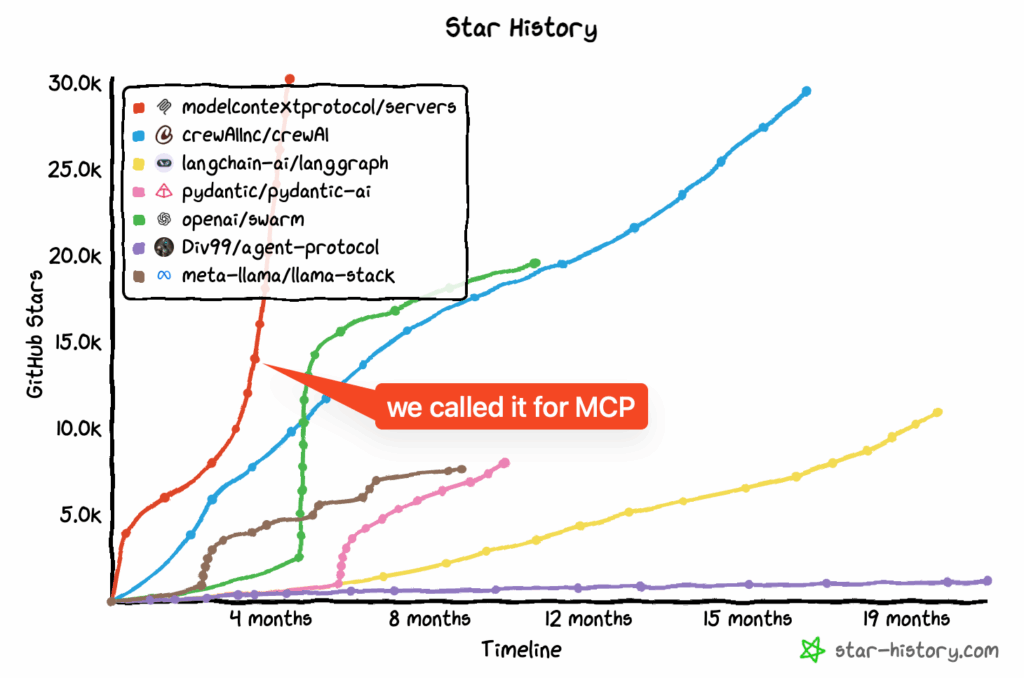
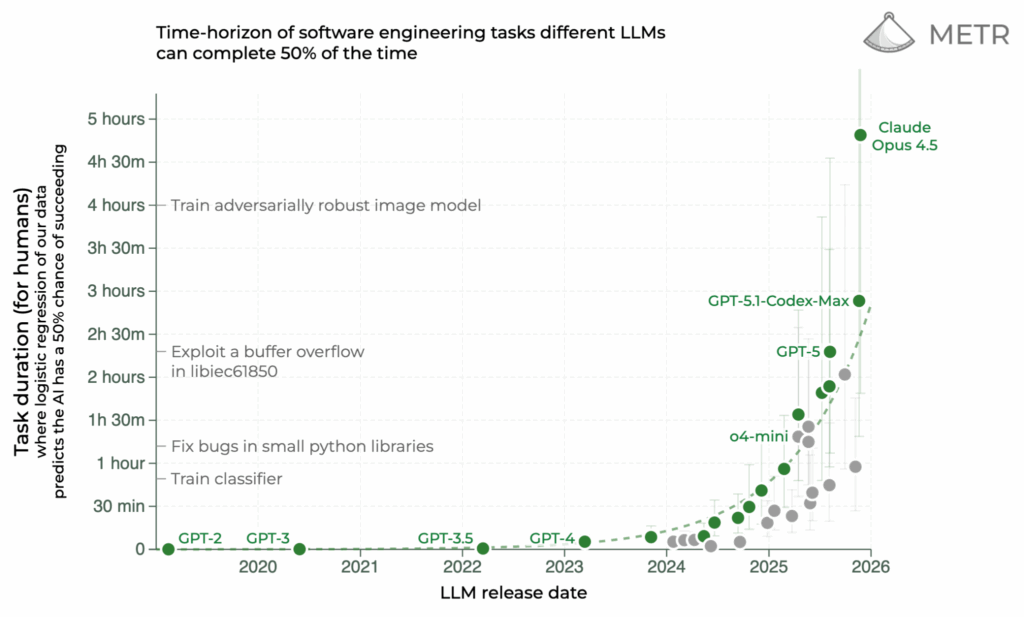
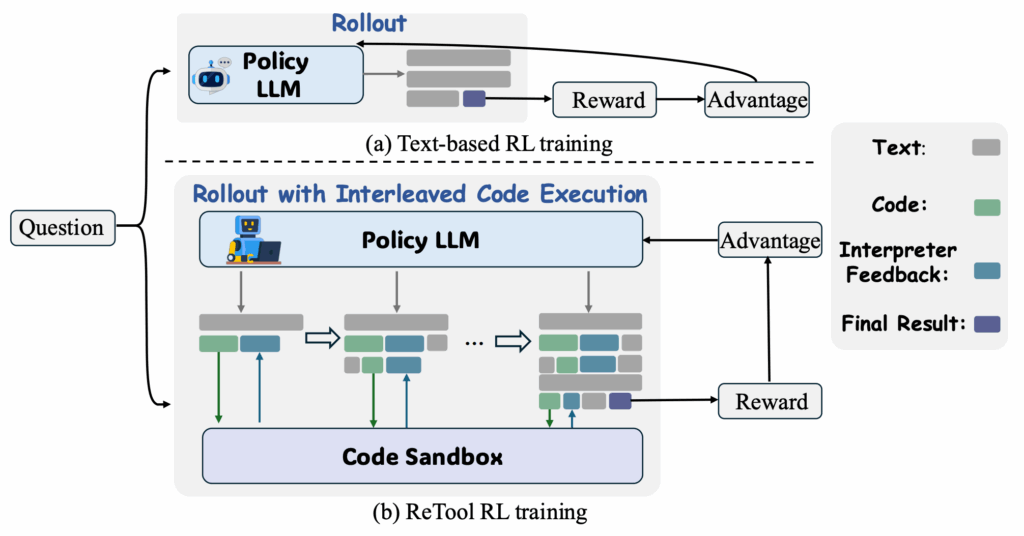

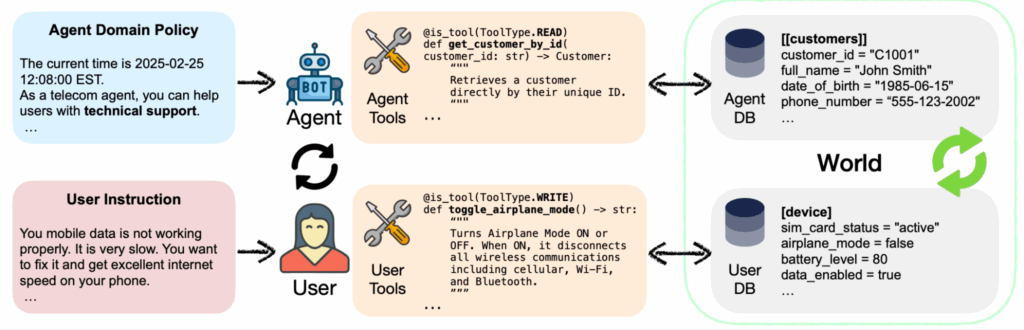
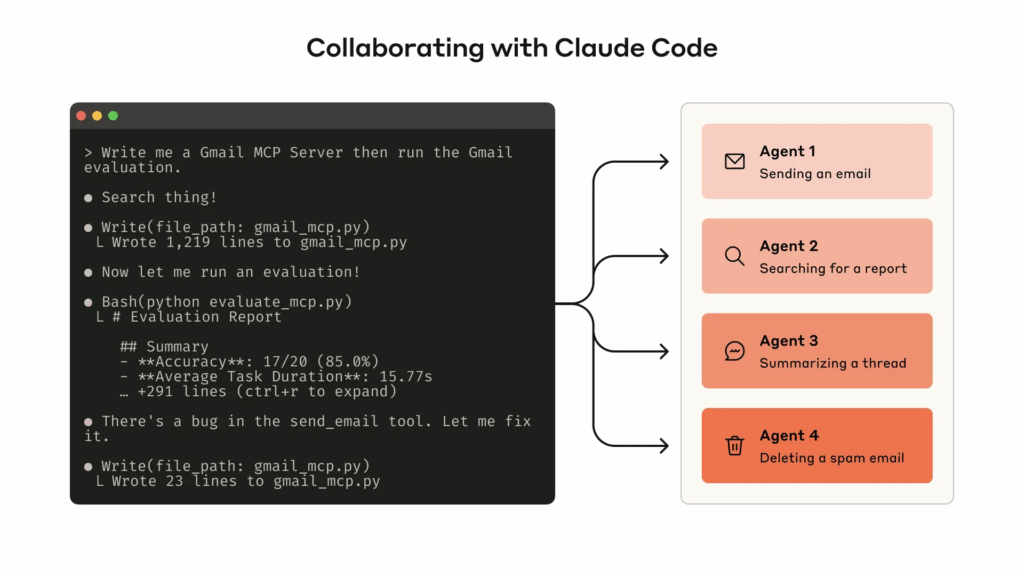
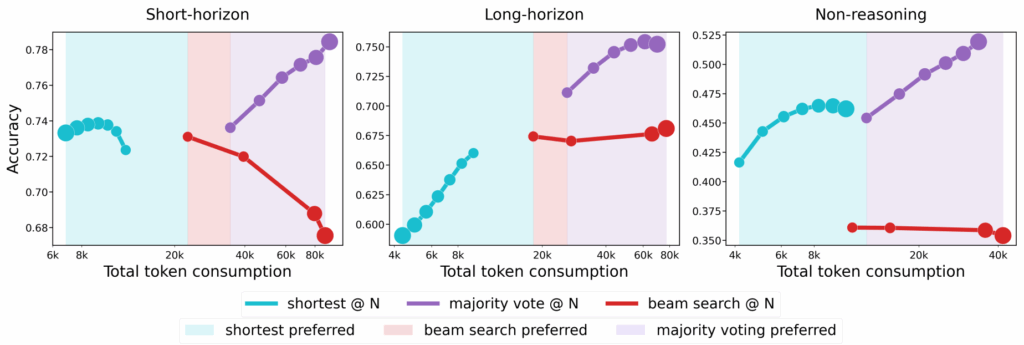
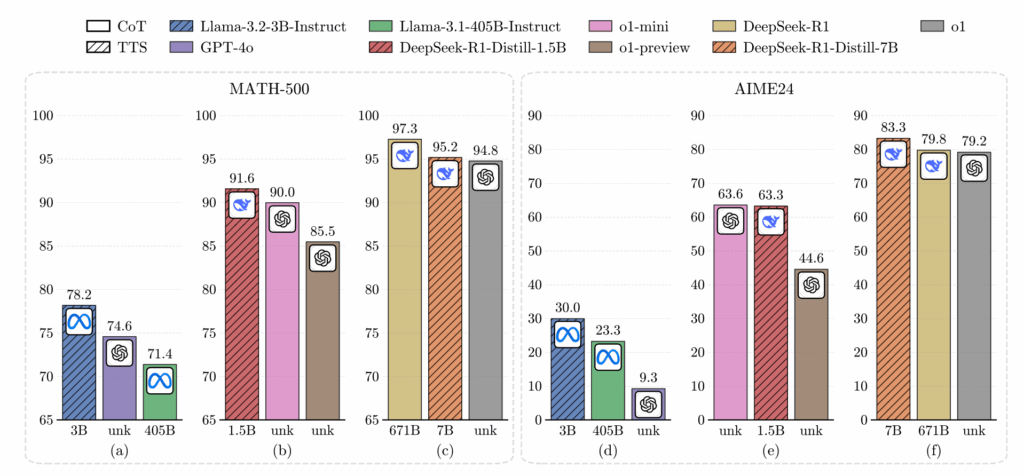
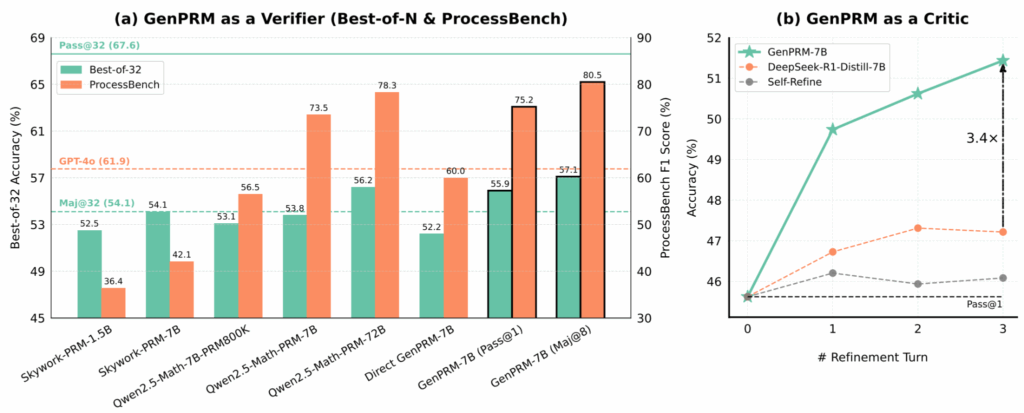
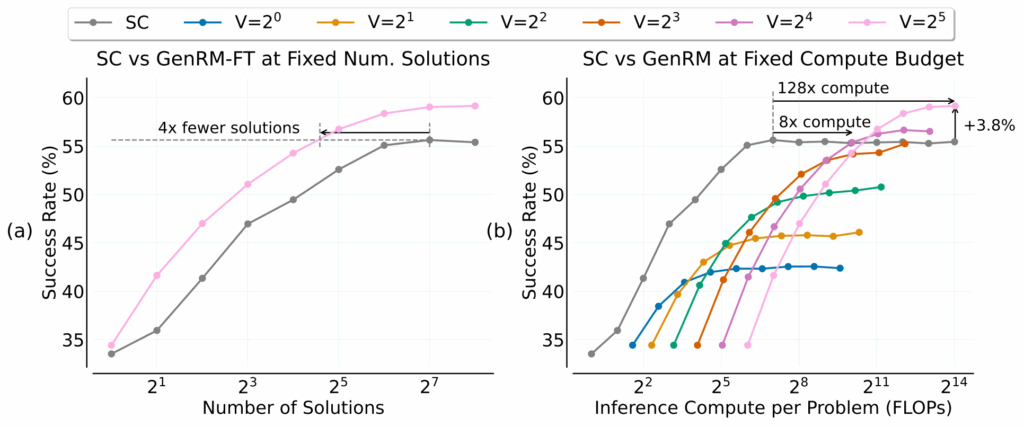
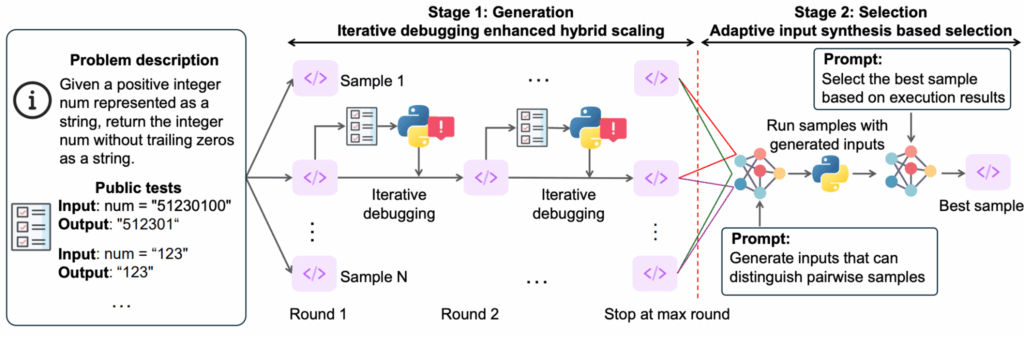
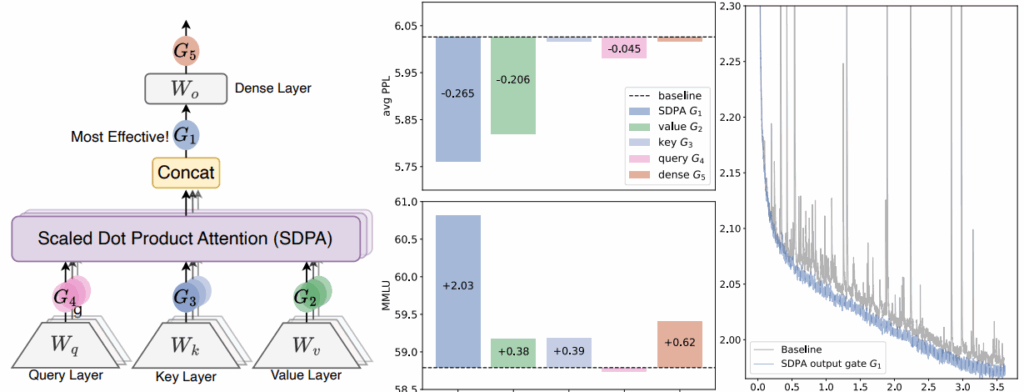


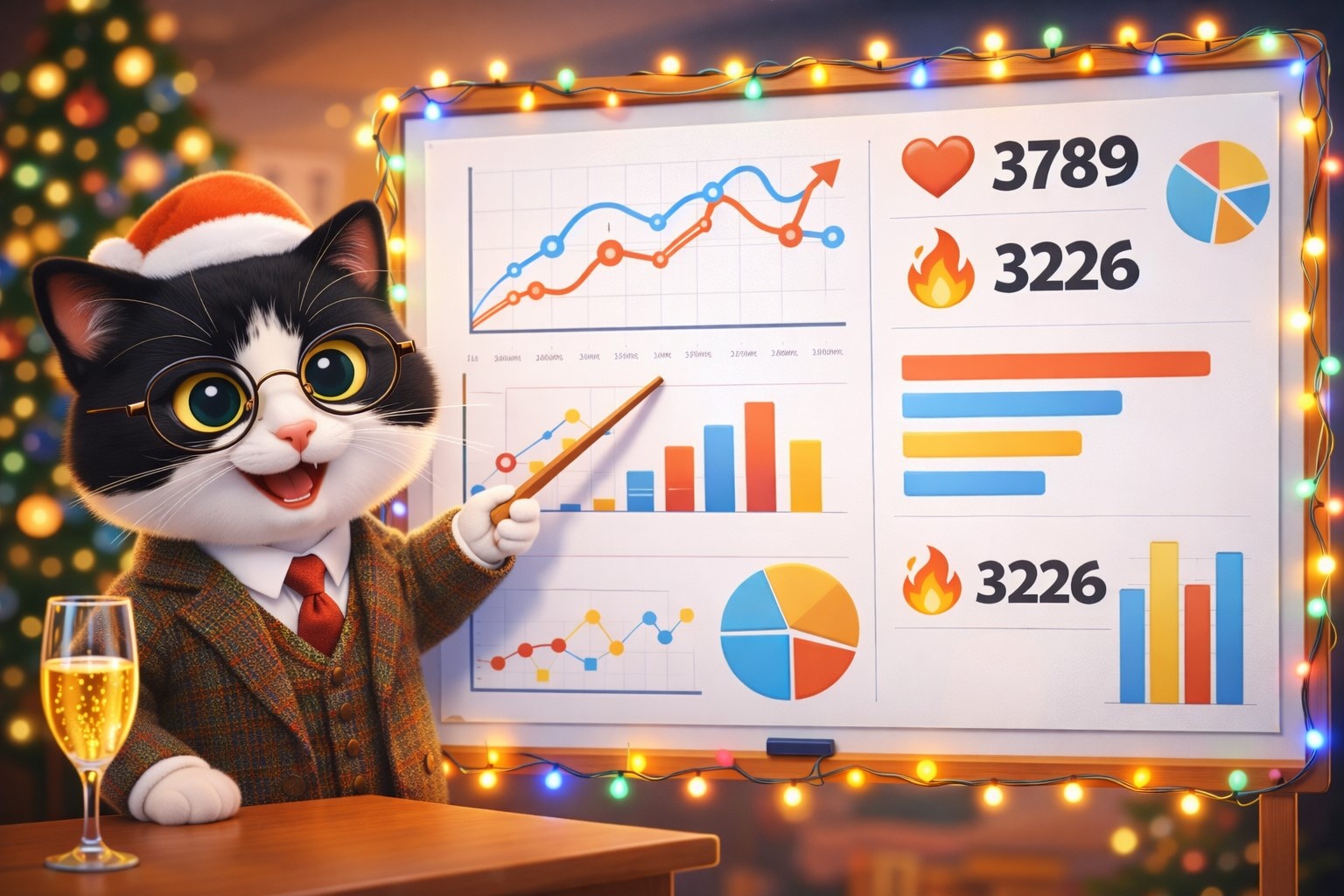
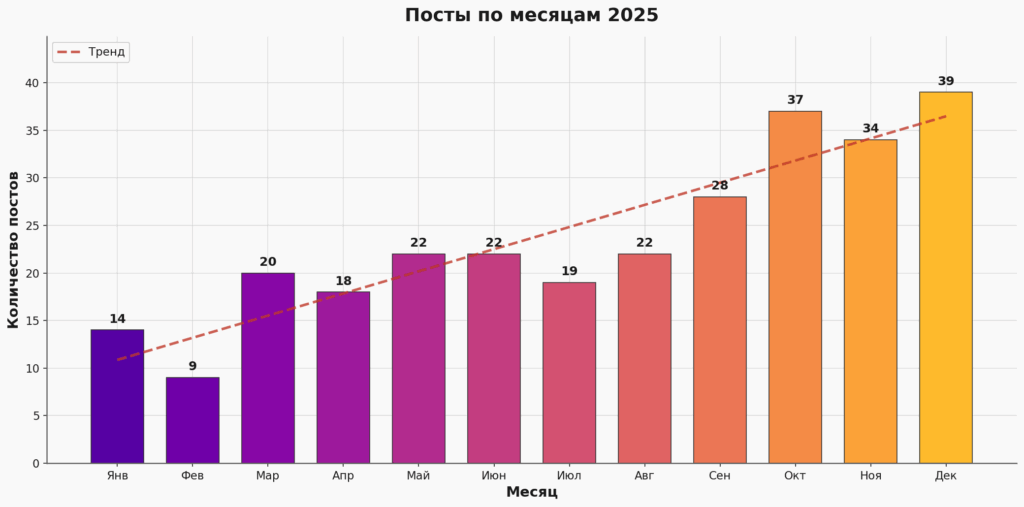
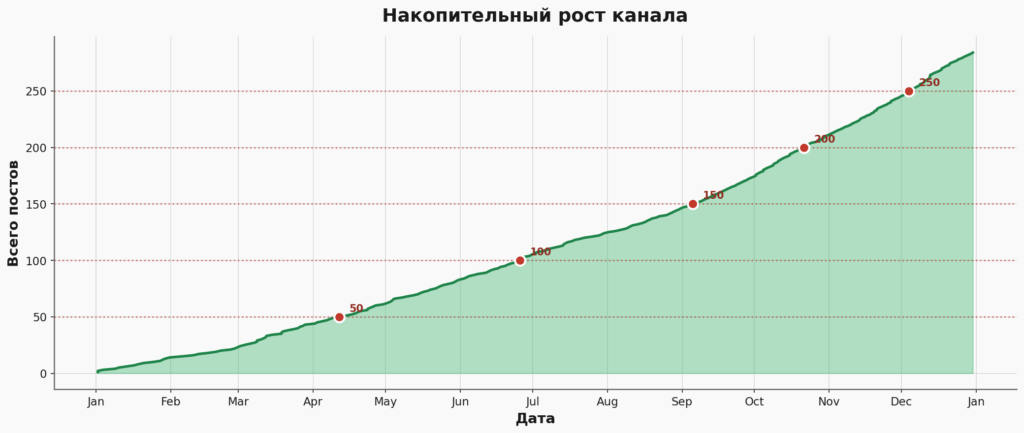
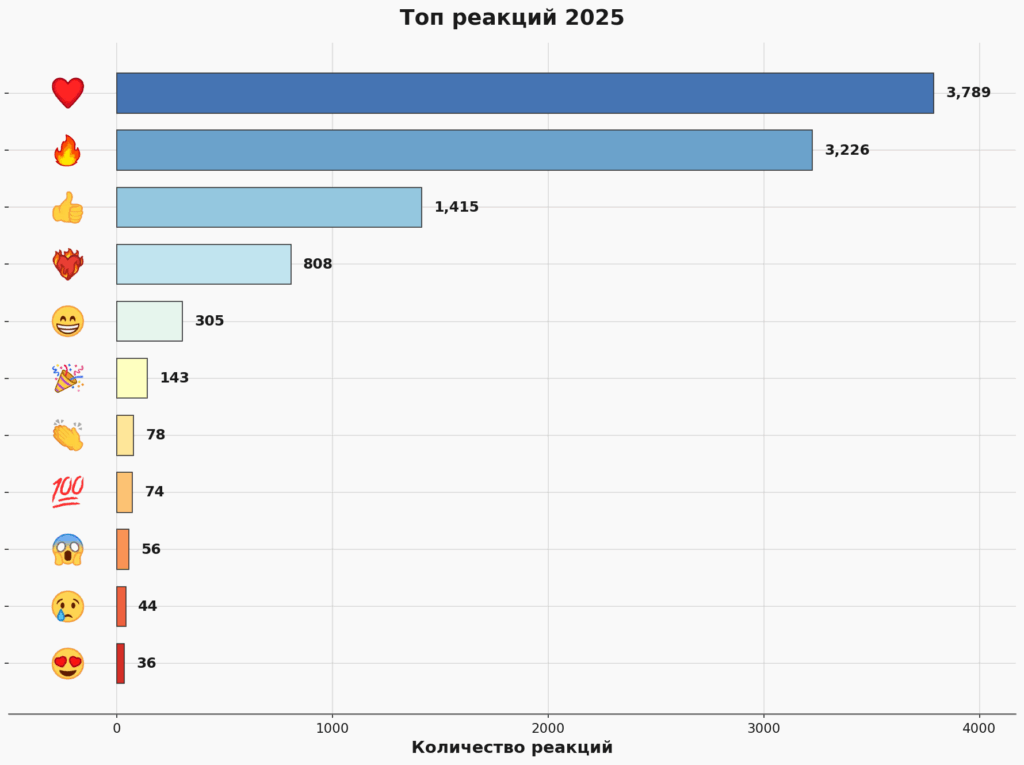
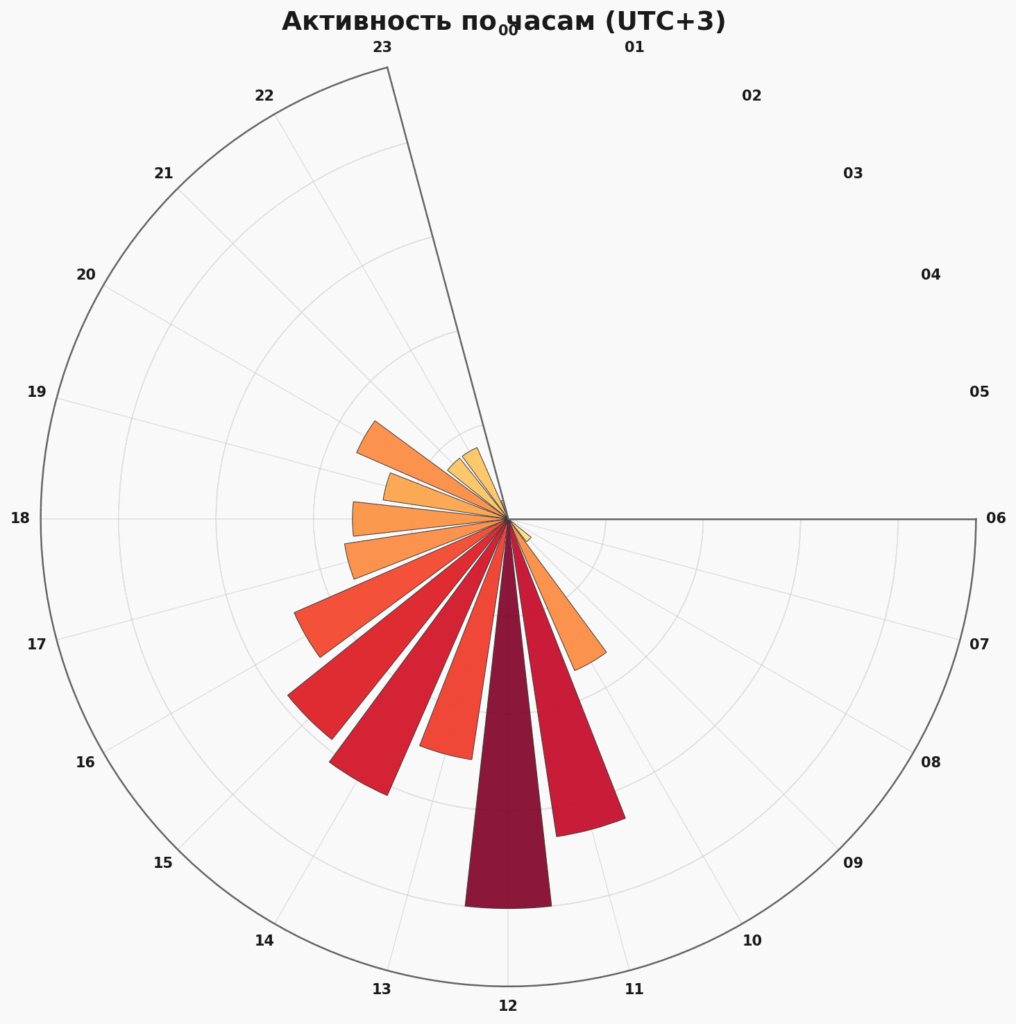
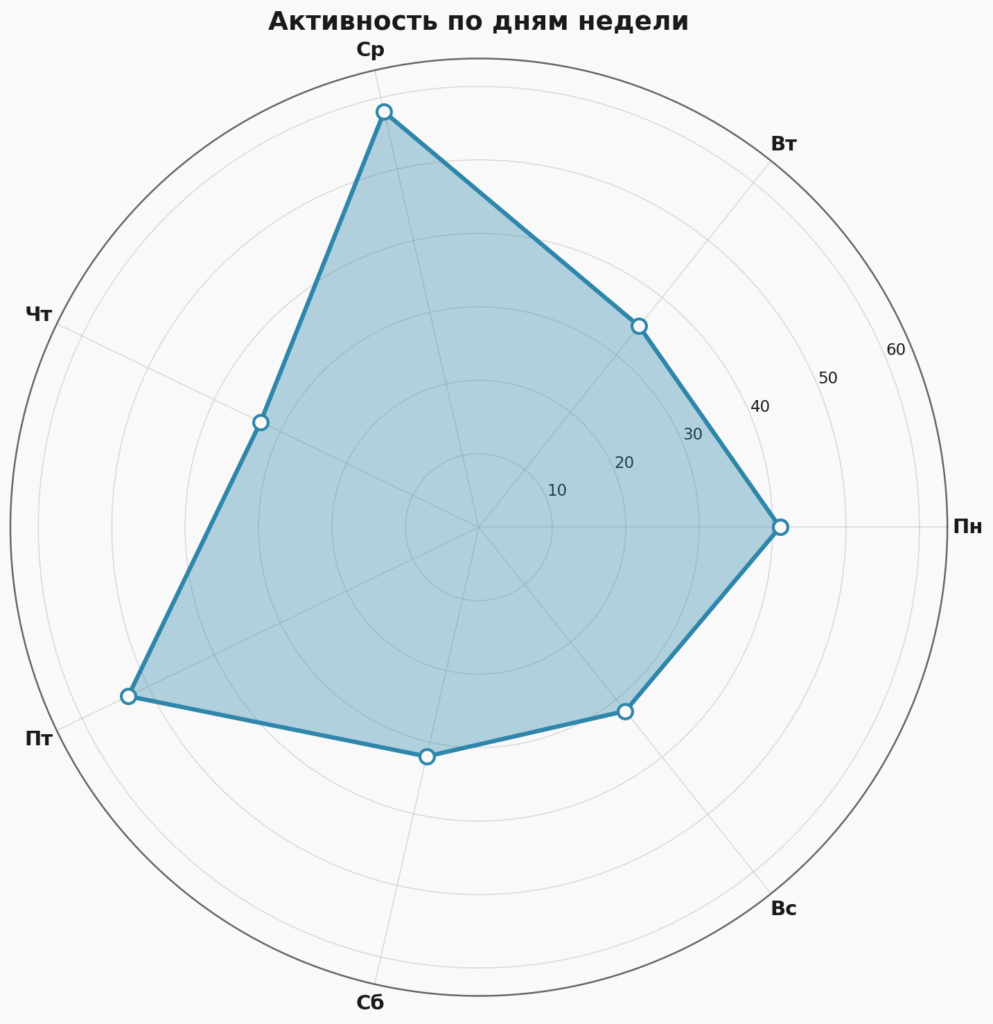
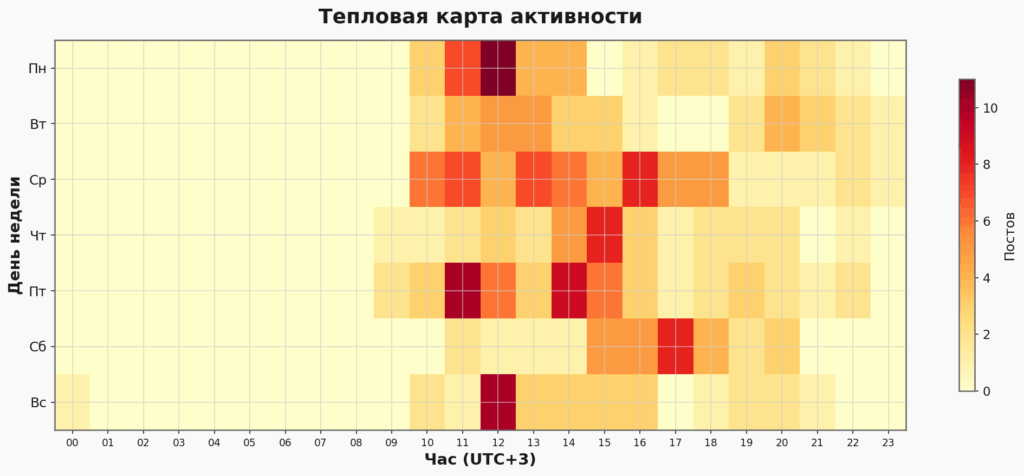
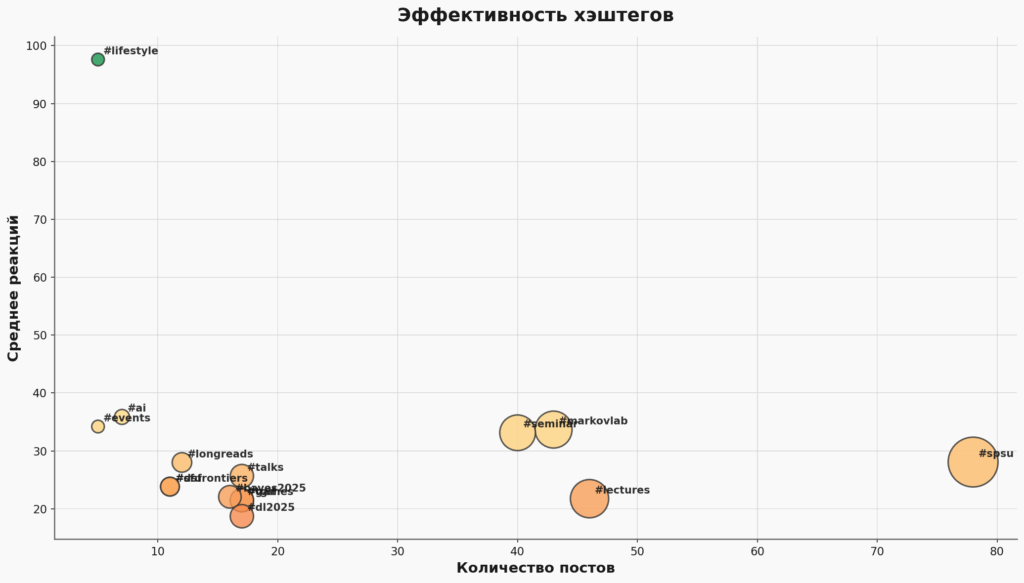
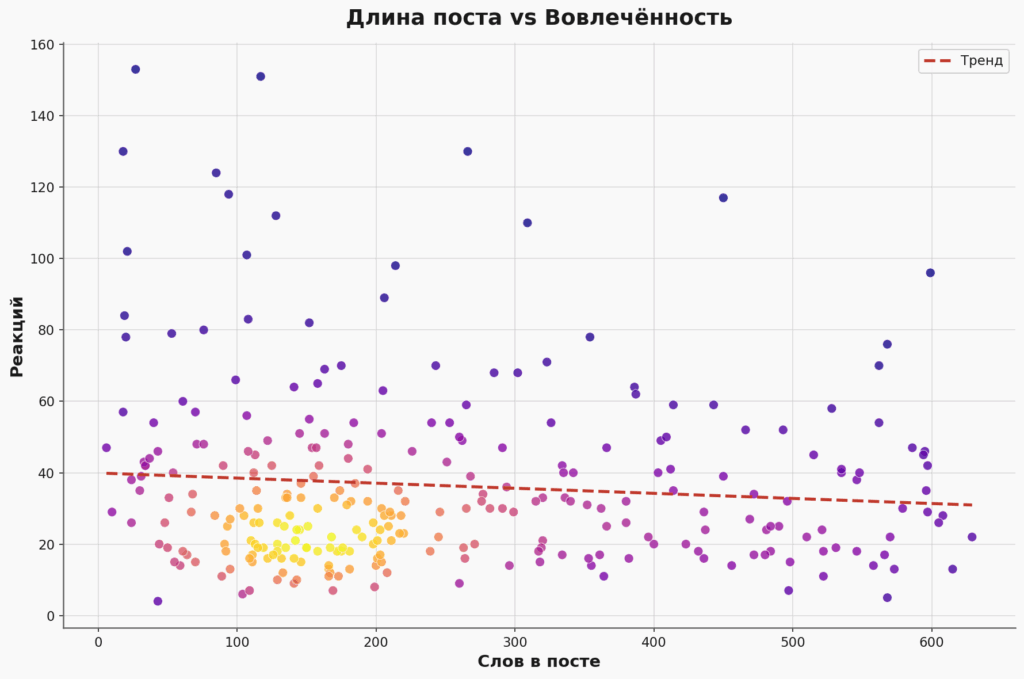
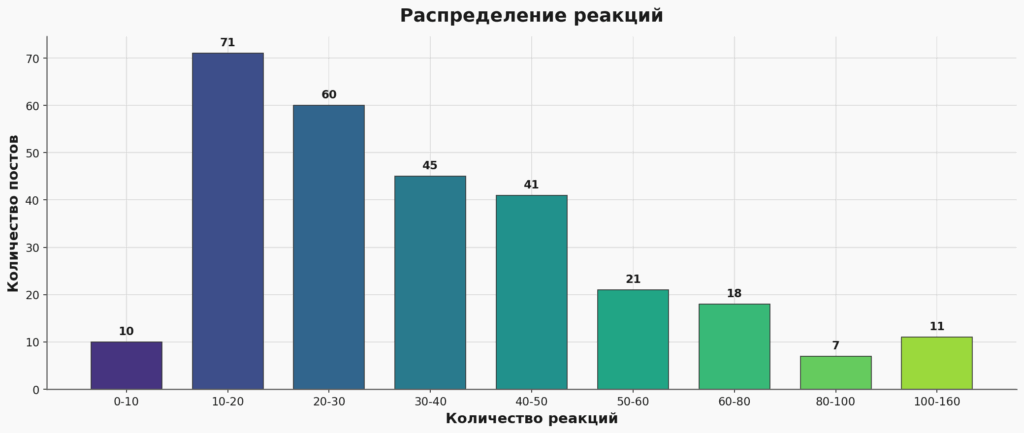

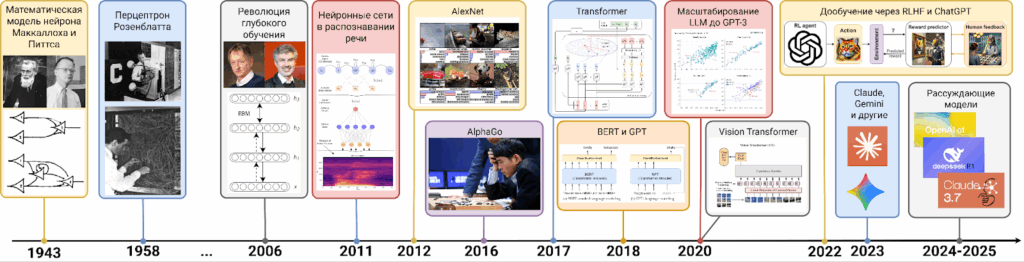
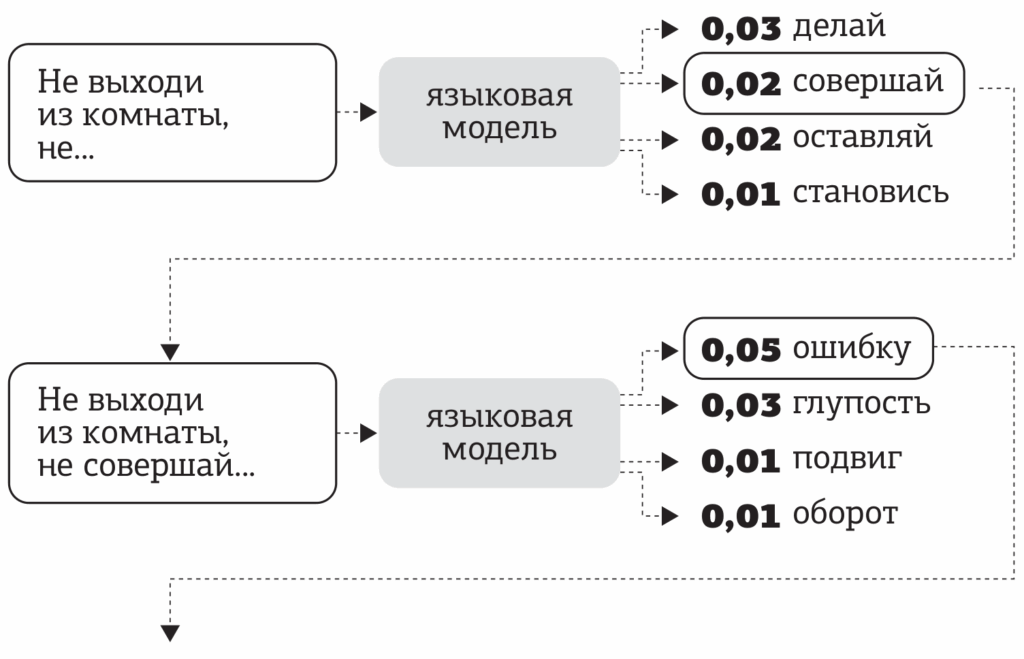



























































































































")










